еҰӮдҪ•еҒҡеҲ°жҖ§иғҪзҝ»еҖҚ NVIDIA Ampereжһ¶жһ„и§Јжһҗ( дәҢ )
е®Ңж•ҙзҡ„GeForce RTX 3080ж ёеҝғ
жҲ‘们еңЁеҸ‘еёғдјҡдёӯз»Ҹеёёеҗ¬еҲ°жҖ§иғҪзҝ»еҖҚзҡ„иҜҙжі• пјҢ е…¶е®һжҳҜеӣ дёәжң¬ж¬ЎNVIDIAAmpereзҡ„SMеңЁTuringеҹәзЎҖдёҠеўһеҠ дәҶдёҖеҖҚзҡ„FP32иҝҗз®—еҚ•е…ғ пјҢ иҝҷе°ұдҪҝеҫ—жҜҸдёӘSMзҡ„FP32иҝҗз®—еҚ•е…ғж•°йҮҸжҸҗй«ҳдәҶдёҖеҖҚ пјҢ еҗҢж—¶еҗһеҗҗйҮҸд№ҹе°ұеҸҳдёәдәҶдёҖеҖҚ гҖӮ
иҖҢйҖҡеёёжҲ‘们计算жҳҫеҚЎзҡ„CUDAж•°йҮҸ пјҢ 并дёҚжҳҜжҠҠSMдёӯзҡ„жүҖжңүеҚ•е…ғеҠ иө·жқҘи®Ўж•° пјҢ иҖҢжҳҜеҸӘз»ҹи®ЎFP32еҚ•е…ғзҡ„ж•°йҮҸ пјҢ жүҖд»Ҙиҝҷж ·дёҖжқҘ пјҢ SMдёӯзҡ„гҖҗFP32 : INT32гҖ‘ д»Һ 1:1 еҸҳдёә 2:1 гҖӮ
еҰӮRTX 3080зҡ„8704дёӘCUDA пјҢ е…¶е®һе®ғеҸӘжңү4352дёӘINT32еҚ•е…ғ пјҢ дҪҶз”ұдәҺеҶ…йғЁзҡ„FP32ж•°йҮҸзҝ»дәҶдёҖеҖҚ пјҢ жүҖд»ҘжңҖз»Ҳе®һзҺ°дәҶ8704иҝҷдёӘжғҠдәәзҡ„ж•°еӯ— гҖӮ
иҖҢиҝҷж ·зІ—жҡҙзҡ„жҸҗеҚҮCUDAж•°йҮҸеҜ№дәҺжёёжҲҸжңүеё®еҠ©еҗ—пјҹзӯ”жЎҲжҳҜжңү пјҢ дёҚд»…жңүжҸҗеҚҮиҝҳеҫҲеӨ§ гҖӮ е…¶е®һйҖҡеёёеңЁжёёжҲҸдёӯжө®зӮ№иҝҗз®—зӣёжҜ”ж•ҙж•°и®Ўз®—иҰҒеёёз”Ёзҡ„еӨҡ пјҢ еӣҫеҪўгҖҒз®—жі•д»ҘеҸҠеҗ„з§Қи®Ўз®—ж“ҚдҪңдёӯзқҖиүІеҷЁе·ҘдҪңиҙҹиҪҪйҖҡеёёйңҖиҰҒж··еҗҲдҪҝз”ЁFP32з®—ж•°жҢҮд»Ө пјҢ иҖҢFP32зҡ„еҠ йҖҹд№ҹжңүеҠ©дәҺе…үзәҝиҝҪиёӘйҷҚеҷӘзқҖиүІеҷЁ гҖӮ
03第дәҢд»ЈRT Core
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…үиҝҪе·ҘдҪңеҺҹзҗҶзӨәж„Ҹ
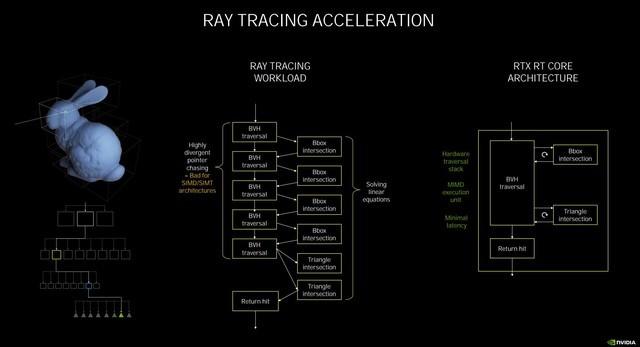
еңЁжӯӨж¬Ўзҡ„NVIDIAAmpereжһ¶жһ„дёӯ пјҢ NVIDIAе®ҳж–№е®Јеёғдёә第дәҢд»ЈRT Core пјҢ е®ғе’Ң第дёҖд»Јжңүд»Җд№ҲдёҚеҗҢе‘ў гҖӮ йҰ–е…ҲиҰҒзҹҘйҒ“RT Coreзҡ„е·ҘдҪңеҺҹзҗҶжҳҜ пјҢ зқҖиүІеҷЁеҸ‘еҮәе…үзәҝиҝҪиёӘзҡ„иҜ·жұӮ пјҢ дәӨз»ҷRT CoreжқҘеӨ„зҗҶ пјҢ е®ғе°ҶиҝӣиЎҢдёӨз§ҚжөӢиҜ• пјҢ еҲҶеҲ«дёәиҫ№з•ҢдәӨеҸүжөӢиҜ•пјҲBox Intersection testingпјүе’Ңдёүи§’еҪўдәӨеҸүжөӢиҜ•пјҲTriangle Intersectiontestingпјү гҖӮ еҹәдәҺBVHз®—жі•жқҘеҲӨж–ӯ пјҢ еҰӮжһңжҳҜж–№еҪў пјҢ йӮЈд№Ҳе°ұиҝ”еӣһзј©е°ҸиҢғеӣҙ继з»ӯжөӢиҜ• пјҢ еҰӮжһңжҳҜдёүи§’еҪў пјҢ еҲҷеҸҚйҰҲз»“жһңиҝӣиЎҢжёІжҹ“ гҖӮ
иҖҢе…үзәҝиҝҪиёӘжңҖиҖ—ж—¶зҡ„жӯЈжҳҜжұӮдәӨи®Ўз®— пјҢ еӣ жӯӨ пјҢ иҰҒжҸҗеҚҮе…үзәҝиҝҪиёӘжҖ§иғҪ пјҢ дё»иҰҒжҳҜеҜ№дёӨз§ҚжұӮдәӨпјҲBVH/дёүи§’еҪўжұӮдәӨпјүиҝӣиЎҢеҠ йҖҹ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
RT Coreзҡ„еҸҳеҢ–
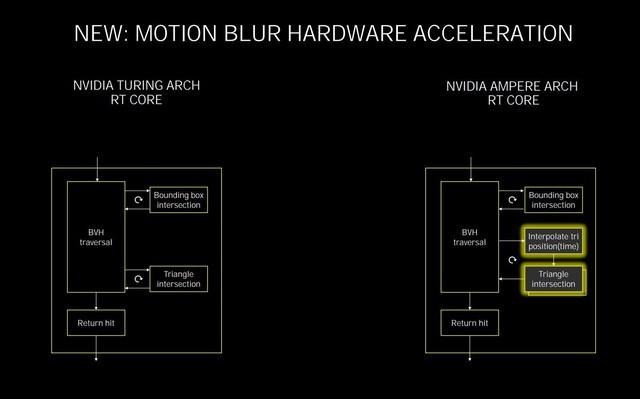
еңЁTuringзҡ„RT Coreдёӯ пјҢ еҸҜд»ҘжҜҸдёӘе‘Ёжңҹе®ҢжҲҗ5ж¬ЎBVHйҒҚеҺҶгҖҒ4ж¬ЎBVHжұӮдәӨд»ҘеҸҠдёҖж¬Ўдёүи§’еҪўжұӮдәӨ пјҢ еңЁз¬¬дәҢд»ЈRT Core йҮҢ пјҢ NVIDIAеўһеҠ дәҶдёҖдёӘж–°зҡ„дёүи§’еҪўдҪҚзҪ®жҸ’еҖјжЁЎеқ—д»ҘеҸҠдёҖдёӘзҡ„йўқеӨ–зҡ„дёүи§’еҪўжұӮдәӨжЁЎеқ— пјҢ иҝҷж ·еҒҡзҡ„зӣ®зҡ„жҳҜдёәдәҶжҸҗеҚҮиҜёеҰӮиҝҗеҠЁжЁЎзіҠзү№ж•Ҳж—¶еҖҷзҡ„е…үзәҝиҝҪиёӘжҖ§иғҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
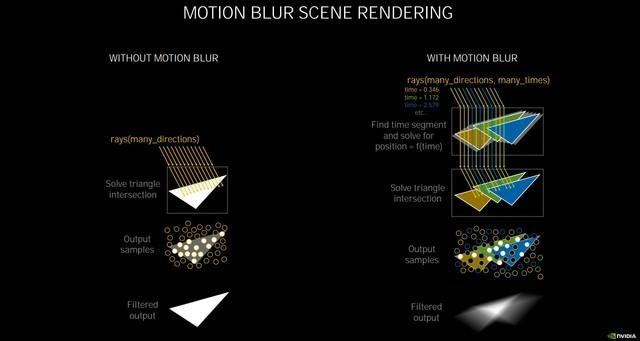
иҝҗеҠЁжЁЎзіҠжёІжҹ“еҺҹзҗҶ
第дәҢд»ЈRT CoreеҸҜд»Ҙи®©е…үзәҝиҝҪиёӘдёҺзқҖиүІеҗҢж—¶иҝӣиЎҢ пјҢ иҝӣиЎҢзҡ„е…үзәҝиҝҪиёӘи¶ҠеӨҡ пјҢ еҠ йҖҹе°ұи¶Ҡеҝ« пјҢ е®ғе°Ҷе…үзәҝзӣёдәӨзҡ„еӨ„зҗҶжҖ§иғҪжҸҗеҚҮдәҶдёҖеҖҚ пјҢ еңЁжёІжҹ“жңүеҠЁжҖҒжЁЎзіҠзҡ„еҪұеғҸж—¶ пјҢ жҢүз…§NVIDIAиҮӘе·ұзҡ„е®һжөӢ пјҢ жҜ”Turingеҝ«8еҖҚ гҖӮ
04第дёүд»ЈTensor Core
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
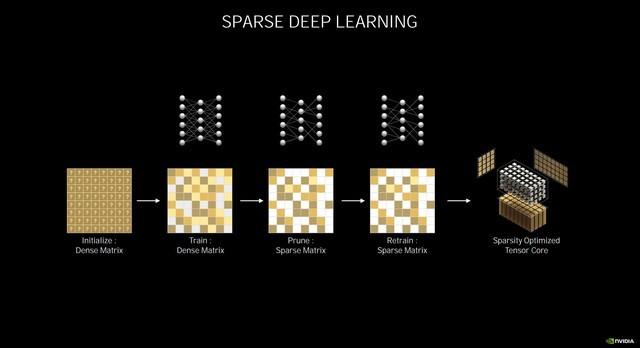
зЁҖз–Ҹж·ұеәҰеӯҰд№
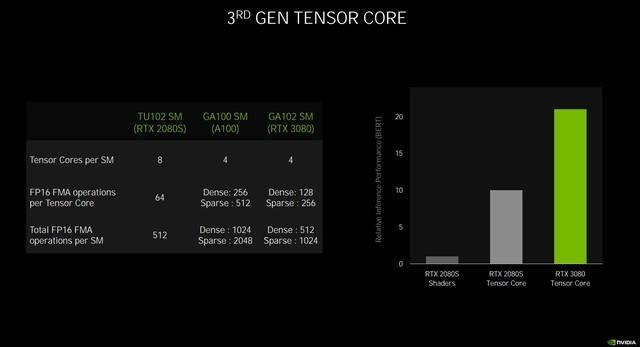
йҷӨдәҶе…үзәҝиҝҪиёӘзҡ„ејәеҢ– пјҢ Ampereжһ¶жһ„зҡ„Tensor Coreд№ҹеҫ—еҲ°дәҶжһҒеӨ§ең°еҠ ејә пјҢ еңЁз¬¬дёүд»ЈTensor Coreдёӯ пјҢ NVIDIAеј•е…ҘдәҶзЁҖз–ҸеҢ–еҠ йҖҹ пјҢ еҸҜиҮӘеҠЁиҜҶеҲ«е№¶ж¶ҲйҷӨдёҚеӨӘйҮҚиҰҒзҡ„DNNпјҲж·ұеәҰзҘһз»ҸзҪ‘з»ңпјүжқғйҮҚ пјҢ еҗҢж—¶дҫқ然иғҪдҝқжҢҒдёҚй”ҷзҡ„зІҫеәҰ гҖӮ
йҰ–е…ҲеҺҹе§Ӣзҡ„еҜҶйӣҶзҹ©йҳөдјҡз»ҸиҝҮи®ӯз»ғ пјҢ еҲ йҷӨжҺүзЁҖз–Ҹзҹ©йҳө пјҢ еҶҚз»ҸиҝҮи®ӯз»ғзЁҖз–Ҹзҹ©йҳө пјҢ д»ҺиҖҢе®һзҺ°зЁҖз–ҸдјҳеҢ– пјҢ иҝӣиҖҢжҸҗй«ҳTensor Coreзҡ„жҖ§иғҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
第дёүд»ЈTensor Coreзҡ„еӨ„зҗҶиғҪеҠӣеӨ§еӨ§жҸҗеҚҮ
жүҖд»ҘжңҖз»Ҳзҡ„з»“жһңе°ұжҳҜTensor CoreеңЁеӨ„зҗҶзЁҖз–ҸзҪ‘з»ңзҡ„йҖҹзҺҮжҳҜTuringзҡ„дёӨеҖҚ пјҢ з®—еҠӣй«ҳиҫҫ238 TensorTFLOPS пјҢ иҖҢTuringдёә89 TensorTFLOPS гҖӮ
05RTX IO
дёҺжӯӨж¬ЎRTX 30зі»жҳҫеҚЎдёҖеҗҢеҸ‘еёғзҡ„иҝҳжңүдёҖйЎ№ж–°жҠҖжңҜвҖ”вҖ”RTX IO гҖӮ зӣ®еүҚеҫҲеӨҡжёёжҲҸеҠЁиҫ„еҮ еҚҒGз”ҡиҮізҷҫGзҡ„е®үиЈ…з©әй—ҙ пјҢ еҜ№дәҺеӯҳеӮЁз©әй—ҙзҡ„иҙҹжӢ…жҡӮдё”дёҚжҸҗ пјҢ дҪҶеӯҳж”ҫеңЁзЎ¬зӣҳдёӯзҡ„ж•°жҚ® пјҢ еҰӮжһңжҳҫеҚЎжғіиҰҒиҜ»еҸ–еҲ° пјҢ йңҖиҰҒе…Ҳз”ұCPUд»ҺзЎ¬зӣҳдёӯиҜ»еҸ–еҺӢзј©иҝҮзҡ„ж•°жҚ® пјҢ з»ҸиҝҮи§ЈеҺӢзј©еҶҚеҸ‘йҖҒеҲ°жҳҫеӯҳдёӯ гҖӮ
жҺЁиҚҗйҳ…иҜ»














- жҗӯиҪҪйӘҒйҫҷ888еӨ„зҗҶеҷЁ+120Wи¶…е…… жЁӘеұҸжҖ§иғҪж——иҲ°iQOO 7жӯЈејҸеҸ‘еёғ
- дёҚеҚ•жҖ§иғҪдёҖйӘ‘з»қе°ҳ iQOO 7зҡ„иҝҷдәӣдә®зӮ№д№ҹеҖјеҫ—дёҖжҸҗ
- йӘҒйҫҷ888йўҶиЎ” iQOO 7жҗӯиҪҪж–°дёҖд»ЈжҖ§иғҪвҖңй“Ғдёүи§’вҖқ
- вҖңжҖ§иғҪж——иҲ°вҖқiQOO 7жӯЈејҸеҸ‘еёғпјҡж„ҹеҸ—е…Ёж„ҹж“ҚжҺ§3798е…ғиө·
- еӨ§дёҖйқһи®Ўз®—жңәдё“дёҡзҡ„еӯҰз”ҹпјҢеҰӮдҪ•еҲ©з”ЁеҜ’еҒҮиҮӘеӯҰCиҜӯиЁҖ
- ж¶ҲжҒҜ|еҲҳдҪңиҷҺпјҡд»Ҡе№ҙе°ҶеңЁеҪұеғҸеҠӣжҠ•е…Ҙе·ЁеӨ§иө„жәҗ еҠӣдәүеҒҡеҲ°е…Ёзҗғ第дёҖ
- иӢ№жһңдёӨж¬ҫж–°iPadйҪҗжӣқе…үпјҡжҖ§иғҪжҸҗй«ҳгҖҒе…Ҙй—Ёж¬ҫжӣҙиҪ»и–„гҖҒе”®д»·дҫҝе®ң
- зәўзұіK40жёІжҹ“еӣҫжӣқе…үпјҡеұ…дёӯжҢ–еӯ”+еҗҺзҪ®еӣӣж‘„пјҢиҝҷеӨ–и§ӮдҪ и§үеҫ—еҰӮдҪ•пјҹ
- еҸ‘е”®д»…7еӨ©пјҢжҖ§иғҪе…ЁеӣҪ第дёҖпјҡеҚҺдёәгҖҒOVдёҖиө·дёҠпјҢйғҪдёҚеҰӮиҝҷж¬ҫжүӢжңәпјҹ
- дј з»ҹ1/10еӨ§е°Ҹ дёғеҪ©иҷ№еҸ‘еёғжңҖе°Ҹзҡ„mini SSDзЎ¬зӣҳпјҡжҖ§иғҪйҰ–ж¬Ўе…¬ејҖ