жңүе…іиҮӘ然иҜӯиЁҖеӨ„зҗҶзҡ„ж·ұеәҰеӯҰд№ зҹҘиҜҶжңүе“Әдәӣпјҹ( еӣӣ )
е“Ҳе“ҲпјҒиҝҷдёӘж„ҹзҹҘжңәзңҹжҳҜдёӘеҘҪеӯҰз”ҹ гҖӮ йҖҡиҝҮеҶ…йғЁеҫӘзҺҜжӣҙж–°жқғйҮҚ пјҢ ж„ҹзҹҘжңәд»Һж•°жҚ®йӣҶдёӯеӯҰд№ дәҶз»ҸйӘҢ гҖӮ еңЁз¬¬дёҖж¬Ўиҝӯд»ЈеҗҺ пјҢ е®ғжҜ”йҡҸжңәзҢңжөӢпјҲжӯЈзЎ®зҺҮдёә1/4пјүеӨҡеҫ—еҲ°дәҶдёӨдёӘжӯЈзЎ®з»“жһңпјҲжӯЈзЎ®зҺҮдёә3/4пјү гҖӮ
еңЁз¬¬дәҢж¬Ўиҝӯд»Јдёӯ пјҢ е®ғиҝҮеәҰдҝ®жӯЈдәҶжқғйҮҚпјҲжӣҙж”№дәҶеӨӘеӨҡпјү пјҢ 然еҗҺйҖҡиҝҮи°ғж•ҙжқғйҮҚжқҘеӣһжәҜз»“жһң гҖӮ еҪ“第еӣӣж¬Ўиҝӯд»Је®ҢжҲҗеҗҺ пјҢ е®ғе·Із»Ҹе®ҢзҫҺең°еӯҰд№ дәҶиҝҷдәӣе…ізі» гҖӮ йҡҸеҗҺзҡ„иҝӯд»Је°ҶдёҚеҶҚжӣҙж–°зҪ‘з»ң пјҢ еӣ дёәжҜҸдёӘж ·жң¬зҡ„иҜҜе·®дёә0 пјҢ жүҖд»ҘдёҚдјҡеҶҚеҜ№жқғйҮҚеҒҡи°ғж•ҙ гҖӮ
иҝҷе°ұжҳҜжүҖи°“зҡ„收ж•ӣ гҖӮ еҪ“дёҖдёӘжЁЎеһӢзҡ„иҜҜе·®еҮҪж•°иҫҫеҲ°дәҶжңҖе°ҸеҖј пјҢ жҲ–иҖ…зЁіе®ҡеңЁдёҖдёӘеҖјдёҠ пјҢ иҜҘжЁЎеһӢе°ұиў«з§°дёә收ж•ӣ гҖӮ жңүж—¶еҖҷеҸҜиғҪжІЎжңүиҝҷд№Ҳе№ёиҝҗ гҖӮ жңүж—¶зҘһз»ҸзҪ‘з»ңеңЁеҜ»жүҫжңҖдјҳжқғеҖјж—¶дёҚж–ӯжіўеҠЁд»Ҙж»Ўи¶ідёҖжү№ж•°жҚ®зҡ„зӣёдә’е…ізі» пјҢ дҪҶж— жі•ж”¶ж•ӣ гҖӮ еңЁ5.8иҠӮдёӯ пјҢ еӨ§е®¶е°ҶзңӢеҲ°зӣ®ж ҮеҮҪж•°пјҲobjective functionпјүжҲ–жҚҹеӨұеҮҪж•°пјҲloss functionпјүеҰӮдҪ•еҪұе“ҚзҘһз»ҸзҪ‘з»ңеҜ№жңҖдјҳжқғйҮҚзҡ„йҖүжӢ© гҖӮ
4пјҺдёӢдёҖжӯҘеҹәжң¬ж„ҹзҹҘжңәжңүдёҖдёӘеӣәжңүзјәйҷ· пјҢ йӮЈе°ұжҳҜ пјҢ еҰӮжһңж•°жҚ®дёҚжҳҜзәҝжҖ§еҸҜеҲҶзҡ„ пјҢ жҲ–иҖ…ж•°жҚ®д№Ӣй—ҙзҡ„е…ізі»дёҚиғҪз”ЁзәҝжҖ§е…ізі»жқҘжҸҸиҝ° пјҢ жЁЎеһӢе°Ҷж— жі•ж”¶ж•ӣ пјҢ д№ҹе°ҶдёҚе…·жңүд»»дҪ•жңүж•Ҳйў„жөӢзҡ„иғҪеҠӣ пјҢ еӣ дёәе®ғж— жі•еҮҶзЎ®ең°йў„жөӢзӣ®ж ҮеҸҳйҮҸ гҖӮ
ж—©жңҹзҡ„е®һйӘҢеңЁд»…еҹәдәҺж ·жң¬еӣҫеғҸеҸҠе…¶зұ»еҲ«жқҘиҝӣиЎҢеӣҫеғҸеҲҶзұ»зҡ„еӯҰд№ дёҠеҸ–еҫ—дәҶжҲҗеҠҹ гҖӮ иҝҷдёӘжҰӮеҝөеңЁж—©жңҹеҫҲжҝҖеҠЁдәәеҝғ пјҢ дҪҶеҫҲеҝ«еҸ—еҲ°дәҶжқҘиҮӘжҳҺж–ҜеҹәпјҲMinskyпјүе’ҢдҪ©зҸҖзү№пјҲPapertпјүзҡ„иҖғйӘҢ[6] пјҢ 他们жҢҮеҮәж„ҹзҹҘжңәеңЁеҲҶзұ»ж–№йқўжңүдёҘйҮҚзҡ„еұҖйҷҗжҖ§ пјҢ 他们иҜҒжҳҺдәҶеҰӮжһңж•°жҚ®ж ·жң¬дёҚиғҪзәҝжҖ§еҸҜеҲҶдёәзӢ¬з«Ӣзҡ„з»„ пјҢ йӮЈд№Ҳж„ҹзҹҘжңәе°Ҷж— жі•еӯҰд№ еҰӮдҪ•еҜ№иҫ“е…Ҙж•°жҚ®иҝӣиЎҢеҲҶзұ» гҖӮ
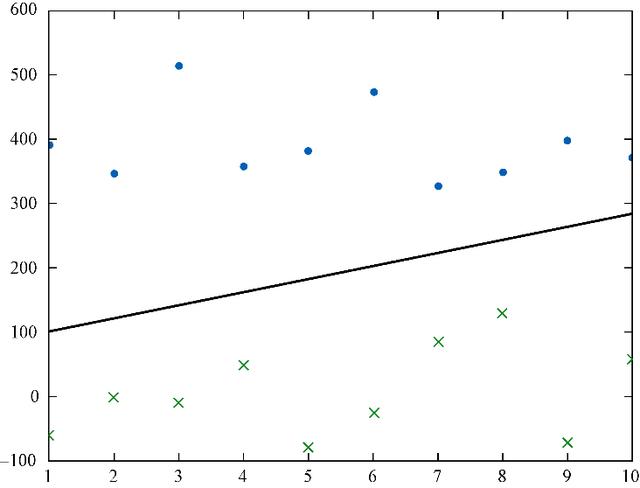
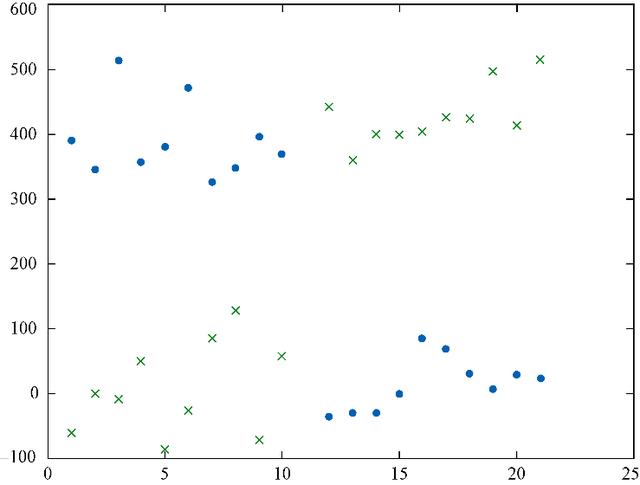
зәҝжҖ§еҸҜеҲҶзҡ„ж•°жҚ®зӮ№пјҲеҰӮеӣҫ5-4жүҖзӨәпјүеҜ№ж„ҹзҹҘжңәжқҘиҜҙжҳҜжІЎжңүй—®йўҳзҡ„ пјҢ иҖҢеӯҳеңЁзұ»еҲ«дәӨеҸүзҡ„ж•°жҚ®е°ҶеҜјиҮҙеҚ•зҘһз»Ҹе…ғж„ҹзҹҘжңәеҺҹең°иёҸжӯҘ пјҢ еӯҰд№ йў„жөӢзҡ„з»“жһңе°ҶдёҚжҜ”йҡҸжңәзҢңжөӢеҘҪ пјҢ иЎЁзҺ°еҫ—е°ұеғҸжҳҜеңЁйҡҸжңәжҠӣзЎ¬еёҒ гҖӮ еңЁеӣҫ5-5дёӯжҲ‘们е°ұж— жі•еңЁдёӨдёӘзұ»пјҲеҲҶеҲ«з”ЁзӮ№е’ҢеҸүиЎЁзӨәпјүд№Ӣй—ҙз”»дёҖжқЎеҲҶеүІзәҝ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ5-4гҖҖзәҝжҖ§еҸҜеҲҶзҡ„ж•°жҚ®
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ5-5гҖҖйқһзәҝжҖ§еҸҜеҲҶзҡ„ж•°жҚ®
ж„ҹзҹҘжңәдјҡз”ЁзәҝжҖ§ж–№зЁӢжқҘжҸҸиҝ°ж•°жҚ®йӣҶзҡ„зү№еҫҒдёҺж•°жҚ®йӣҶдёӯзҡ„зӣ®ж ҮеҸҳйҮҸд№Ӣй—ҙзҡ„е…ізі» пјҢ иҝҷе°ұжҳҜзәҝжҖ§еӣһеҪ’ пјҢ дҪҶжҳҜж„ҹзҹҘжңәж— жі•жҸҸиҝ°йқһзәҝжҖ§ж–№зЁӢжҲ–иҖ…йқһзәҝжҖ§е…ізі» гҖӮ
еұҖйғЁжһҒе°ҸеҖјдёҺе…ЁеұҖжһҒе°ҸеҖј
еҪ“дёҖдёӘж„ҹзҹҘжңә收ж•ӣж—¶ пјҢ еҸҜд»ҘиҜҙе®ғжүҫеҲ°дәҶдёҖдёӘжҸҸиҝ°ж•°жҚ®дёҺзӣ®ж ҮеҸҳйҮҸд№Ӣй—ҙе…ізі»зҡ„зәҝжҖ§ж–№зЁӢ гҖӮ 然иҖҢ пјҢ иҝҷ并дёҚиғҪиҜҙжҳҺиҝҷдёӘжҸҸиҝ°жҖ§зәҝжҖ§ж–№зЁӢжңүеӨҡеҘҪ пјҢ жҲ–иҖ…иҜҙд»Јд»·жңүеӨҡвҖңе°ҸвҖқ гҖӮ еҰӮжһңжңүеӨҡдёӘи§ЈеҶіж–№жЎҲ пјҢ еҚіеӯҳеңЁзқҖеӨҡдёӘеҸҜиғҪзҡ„жһҒе°Ҹд»Јд»· пјҢ е®ғеҸӘдјҡзЎ®е®ҡдёҖдёӘз”ұжқғйҮҚеҲқе§ӢеҖјеҶіе®ҡзҡ„гҖҒзү№е®ҡзҡ„жһҒе°ҸеҖј гҖӮ иҝҷиў«з§°дёәеұҖйғЁжһҒе°ҸеҖј пјҢ еӣ дёәе®ғжҳҜеңЁжқғйҮҚејҖе§Ӣзҡ„ең°ж–№йҷ„иҝ‘жүҫеҲ°зҡ„жңҖдјҳеҖјпјҲжңҖе°Ҹзҡ„д»Јд»·пјү гҖӮ е®ғеҸҜиғҪдёҚжҳҜе…ЁеұҖжһҒе°ҸеҖј пјҢ еӣ дёәе…ЁеұҖжһҒе°ҸеҖјйңҖиҰҒжҗңзҙўжүҖжңүеҸҜиғҪзҡ„жқғйҮҚеҖј гҖӮ еңЁеӨ§еӨҡж•°жғ…еҶөдёӢ пјҢ ж— жі•зЎ®е®ҡжҳҜеҗҰжүҫеҲ°дәҶе…ЁеұҖжһҒе°ҸеҖј гҖӮ
еҫҲеӨҡж•°жҚ®еҖјд№Ӣй—ҙзҡ„е…ізі»дёҚжҳҜзәҝжҖ§зҡ„ пјҢ д№ҹжІЎжңүеҘҪзҡ„зәҝжҖ§еӣһеҪ’жҲ–зәҝжҖ§ж–№зЁӢиғҪеӨҹжҸҸиҝ°иҝҷдәӣе…ізі» гҖӮ и®ёеӨҡж•°жҚ®йӣҶдёҚиғҪз”ЁзӣҙзәҝжҲ–е№ійқўжқҘзәҝжҖ§еҲҶеүІ гҖӮ еӣ дёәдё–з•ҢдёҠзҡ„еӨ§еӨҡж•°ж•°жҚ®дёҚиғҪз”ұзӣҙзәҝжҲ–е№ійқўжқҘжё…жҘҡең°еҲҶејҖ пјҢ жҳҺж–Ҝеҹәе’ҢдҪ©зҸҖзү№еҸ‘иЎЁзҡ„вҖңиҜҒжҳҺвҖқи®©ж„ҹзҹҘжңәиў«жқҹд№Ӣй«ҳйҳҒ гҖӮ
дҪҶжҳҜжңүе…іж„ҹзҹҘжңәзҡ„жғіжі•е№¶дёҚдјҡе°ұжӯӨж¶ҲдәЎ гҖӮ Rumelhardt McClellandзҡ„еҗҲдҪңжҲҗжһң[7]пјҲGeoffrey Hintonд№ҹеҸӮдёҺе…¶дёӯпјүеұ•зӨәдәҶеҸҜд»ҘдҪҝз”ЁеӨҡеұӮж„ҹзҹҘжңәзҡ„з»„еҗҲжқҘи§ЈеҶіејӮжҲ–пјҲXORпјүй—®йўҳ[8] пјҢ жӯӨеҗҺж„ҹзҹҘжңәеҶҚж¬Ўжө®еҮәж°ҙйқў гҖӮ д№ӢеүҚ пјҢ еӨ§е®¶дҪҝз”ЁеҚ•еұӮж„ҹзҹҘжңәи§ЈеҶізҡ„жҲ–пјҲORпјүй—®йўҳеұһдәҺжҜ”иҫғз®ҖеҚ•зҡ„й—®йўҳ пјҢ д№ҹжІЎжңүз”ЁеҲ°еӨҡеұӮеҸҚеҗ‘дј ж’ӯ гҖӮ Rumelhardt McClellandзҡ„е…ій”®зӘҒз ҙжҳҜеҸ‘зҺ°дәҶдёҖз§Қж–№жі• пјҢ иҜҘж–№жі•еҸҜд»ҘдёәжҜҸдёӘж„ҹзҹҘжңәйҖӮеҪ“ең°еҲҶй…ҚиҜҜе·® гҖӮ 他们дҪҝз”Ёзҡ„жҳҜдёҖз§ҚеҸ«еҸҚеҗ‘дј ж’ӯзҡ„дј з»ҹжҖқжғі пјҢ йҖҡиҝҮиҝҷз§Қи·Ёи¶ҠеӨҡдёӘзҘһз»Ҹе…ғеұӮзҡ„еҸҚеҗ‘дј ж’ӯжҖқжғі пјҢ 第дёҖдёӘзҺ°д»ЈзҘһз»ҸзҪ‘з»ңиҜһз”ҹдәҶ гҖӮ
еҹәжң¬ж„ҹзҹҘжңәжңүдёҖдёӘеӣәжңүзҡ„зјәйҷ· пјҢ еҚіеҰӮжһңж•°жҚ®дёҚжҳҜзәҝжҖ§еҸҜеҲҶзҡ„ пјҢ еҲҷжЁЎеһӢдёҚдјҡ收ж•ӣеҲ°е…·жңүжңүж•Ҳйў„жөӢиғҪеҠӣзҡ„и§Ј гҖӮ
жҺЁиҚҗйҳ…иҜ»














- iQOO 7жҗӯиҪҪйӘҒйҫҷ888еӨ„зҗҶеҷЁе’Ң120Wи¶…е……пјҢ3798е…ғиө·е”®
- жҗӯиҪҪйӘҒйҫҷ888еӨ„зҗҶеҷЁ+120Wи¶…е…… жЁӘеұҸжҖ§иғҪж——иҲ°iQOO 7жӯЈејҸеҸ‘еёғ
- иҷҫзұійҹід№җж’ӯж”ҫеҷЁе°ҶдәҺ2жңҲ5ж—ҘеҒңжӯўжңҚеҠЎпјҢд»ҠејҖеҗҜз”ЁжҲ·иө„дә§еӨ„зҗҶйҖҡйҒ“
- RHEL 9жҸҗеҚҮдәҶx86_64еӨ„зҗҶеҷЁзҡ„е…Ҙй—ЁиҰҒжұӮ
- иҒ”жғіIdeaPad 5 Proзі»еҲ—笔记жң¬еҸ‘еёғ еҸҜйҖүдёӨз§ҚеӨ„зҗҶеҷЁе’ҢдёӨз§Қе°әеҜё
- иҒ”жғіжҺЁеҮәжҗӯиҪҪйӘҒйҫҷеӨ„зҗҶеҷЁзҡ„IdeaPad 5G
- жҖ§иғҪзҝ»еҖҚпјҒйЈһи…ҫйҰ–ж¬ҫ8ж ёжЎҢйқўеӨ„зҗҶеҷЁи…ҫй”җD2000иҜҰи§Ј
- иӢ№жһңиҮӘз ”ж–°еӨ„зҗҶеҷЁжӣқе…үпјҡ64ж ёеҝғ
- жҺЁиҝӣ|жҲ‘еӣҪд»Ҡе№ҙе°ҶжҺЁиҝӣеҝ«йҖ’вҖңиҝӣжқ‘вҖқвҖңиҝӣеҺӮвҖқвҖңеҮәжө·вҖқжһ„е»әж—ҘеӨ„зҗҶи¶…10дәҝ件еҜ„йҖ’зҪ‘з»ң
- ж”Ҝд»ҳеӨ„зҗҶе…¬еҸёJuspayеҸ‘з”ҹж•°жҚ®жі„жјҸпјҡ1дәҝз”ЁжҲ·дҝЎжҒҜеңЁжҡ—зҪ‘еҮәе”®