жңүе…іиҮӘ然иҜӯиЁҖеӨ„зҗҶзҡ„ж·ұеәҰеӯҰд№ зҹҘиҜҶжңүе“Әдәӣпјҹ( дәҢ )
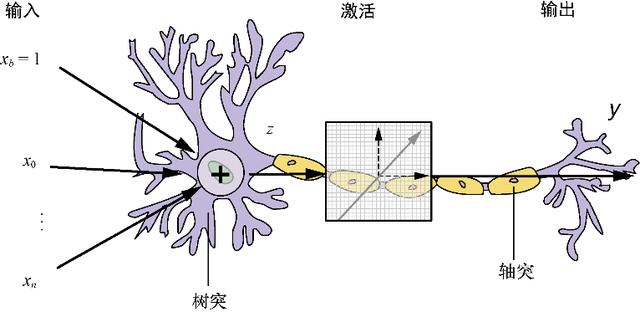
з»ҙеҗ‘йҮҸзҡ„иҫ“е…Ҙ пјҢ еңЁеҗ‘йҮҸзҡ„ејҖеӨҙжҲ–з»“е°ҫеӨ„еўһеҠ дёҖдёӘе…ғзҙ пјҢ жһ„жҲҗдёҖдёӘn + 1з»ҙзҡ„еҗ‘йҮҸ гҖӮ 1зҡ„дҪҚзҪ®дёҺзҪ‘з»ңж— е…і пјҢ еҸӘиҰҒеңЁжүҖжңүж ·жң¬дёӯдҝқжҢҒдёҖиҮҙеҚіеҸҜ гҖӮ еҸҰдёҖз§ҚиЎЁзӨәеҪўејҸжҳҜ пјҢ йҰ–е…ҲеҒҮе®ҡеӯҳеңЁдёҖдёӘеҒҸзҪ®йЎ№ пјҢ е°Ҷе…¶зӢ¬з«ӢдәҺиҫ“е…Ҙд№ӢеӨ– пјҢ е…¶еҜ№еә”дёҖдёӘзӢ¬з«Ӣзҡ„жқғйҮҚ пјҢ е°ҶиҜҘжқғйҮҚд№ҳд»Ҙ1 пјҢ 然еҗҺдёҺж ·жң¬иҫ“е…ҘеҖјеҸҠе…¶зӣёе…іжқғйҮҚзҡ„зӮ№з§ҜиҝӣиЎҢеҠ е’Ң гҖӮ иҝҷдёӨиҖ…е®һйҷ…дёҠжҳҜдёҖж ·зҡ„ пјҢ еҸӘдёҚиҝҮеҲҶеҲ«жҳҜдёӨз§Қеёёи§Ғзҡ„иЎЁзӨәеҪўејҸиҖҢе·І гҖӮ
и®ҫзҪ®еҒҸзҪ®жқғйҮҚзҡ„еҺҹеӣ жҳҜзҘһз»Ҹе…ғйңҖиҰҒеҜ№е…Ё0зҡ„иҫ“е…Ҙе…·жңүеј№жҖ§ гҖӮ зҪ‘з»ңйңҖиҰҒеӯҰд№ еңЁиҫ“е…Ҙе…Ёдёә0зҡ„жғ…еҶөдёӢиҫ“еҮәд»Қ然дёә0 пјҢ дҪҶе®ғеҸҜиғҪеҒҡдёҚеҲ°иҝҷдёҖзӮ№ гҖӮ еҰӮжһңжІЎжңүеҒҸзҪ®йЎ№ пјҢ зҘһз»Ҹе…ғеҜ№еҲқе§ӢжҲ–еӯҰд№ зҡ„д»»ж„ҸжқғйҮҚйғҪдјҡиҫ“еҮә0 Г— жқғйҮҚ = 0 гҖӮ иҖҢжңүдәҶеҒҸзҪ®йЎ№д№ӢеҗҺ пјҢ е°ұдёҚдјҡжңүиҝҷдёӘй—®йўҳдәҶ гҖӮ еҰӮжһңзҘһз»Ҹе…ғйңҖиҰҒеӯҰд№ иҫ“еҮә0 пјҢ еңЁиҝҷз§Қжғ…еҶөдёӢ пјҢ зҘһз»Ҹе…ғеҸҜд»ҘеӯҰдјҡеҮҸе°ҸдёҺеҒҸзҪ®зӣёе…ізҡ„жқғйҮҚ пјҢ дҪҝзӮ№з§ҜдҝқжҢҒеңЁйҳҲеҖјд»ҘдёӢеҚіеҸҜ гҖӮ
еӣҫ5-3з”ЁеҸҜи§ҶеҢ–ж–№жі•еҜ№з”ҹзү©зҡ„еӨ§и„‘зҘһз»Ҹе…ғзҡ„дҝЎеҸ·дёҺж·ұеәҰеӯҰд№ дәәе·ҘзҘһз»Ҹе…ғзҡ„дҝЎеҸ·иҝӣиЎҢдәҶзұ»жҜ” пјҢ еҰӮжһңжғіиҰҒеҒҡжӣҙж·ұе…Ҙзҡ„дәҶи§Ј пјҢ еҸҜд»ҘжҖқиҖғдёҖдёӢдҪ жҳҜеҰӮдҪ•дҪҝз”Ёз”ҹзү©зҘһз»Ҹе…ғжқҘйҳ…иҜ»жң¬д№Ұ并еӯҰд№ жңүе…іиҮӘ然иҜӯиЁҖеӨ„зҗҶзҡ„ж·ұеәҰеӯҰд№ зҹҘиҜҶзҡ„[5] гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ5-3гҖҖж„ҹзҹҘжңәдёҺз”ҹзү©зҘһз»Ҹе…ғ
з”Ёж•°еӯҰжңҜиҜӯжқҘиҜҙ пјҢ ж„ҹзҹҘжңәзҡ„иҫ“еҮәиЎЁзӨәдёәf (x) пјҢ еҰӮдёӢпјҡ
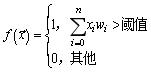 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¬ејҸ5-1гҖҖйҳҲеҖјжҝҖжҙ»еҮҪж•°
жҸҗзӨә
иҫ“е…Ҙеҗ‘йҮҸпјҲXпјүдёҺжқғйҮҚеҗ‘йҮҸпјҲWпјүдёӨдёӨзӣёд№ҳеҗҺзҡ„еҠ е’Ңе°ұжҳҜиҝҷдёӨдёӘеҗ‘йҮҸзҡ„зӮ№з§Ҝ гҖӮ иҝҷжҳҜзәҝжҖ§д»Јж•°еңЁзҘһз»ҸзҪ‘з»ңдёӯжңҖеҹәзЎҖзҡ„еә”з”Ё пјҢ еҜ№зҘһз»ҸзҪ‘з»ңзҡ„еҸ‘еұ•еҪұе“Қе·ЁеӨ§ гҖӮ еҸҰеӨ– пјҢ йҖҡиҝҮзҺ°д»Ји®Ўз®—жңәGPUеҜ№зәҝжҖ§д»Јж•°ж“ҚдҪңзҡ„жҖ§иғҪдјҳеҢ–жқҘе®ҢжҲҗж„ҹзҹҘжңәзҡ„зҹ©йҳөд№ҳжі•иҝҗз®— пјҢ дҪҝеҫ—е®һзҺ°зҡ„зҘһз»ҸзҪ‘з»ңеҸҳеҫ—жһҒдёәй«ҳж•Ҳ гҖӮ
жӯӨж—¶зҡ„ж„ҹзҹҘжңә并жңӘеӯҰеҲ°д»»дҪ•дёңиҘҝ пјҢ дёҚиҝҮеӨ§е®¶е·Із»ҸиҺ·еҫ—дәҶйқһеёёйҮҚиҰҒзҡ„з»“жһң пјҢ жҲ‘们已з»Ҹеҗ‘жЁЎеһӢиҫ“е…Ҙж•°жҚ®е№¶дё”еҫ—еҲ°иҫ“еҮә гҖӮ еҪ“然иҝҷдёӘиҫ“еҮәеҸҜиғҪжҳҜй”ҷиҜҜзҡ„ пјҢ еӣ дёәиҝҳжІЎжңүе‘ҠиҜүж„ҹзҹҘжңәеҰӮдҪ•иҺ·еҫ—жқғйҮҚ пјҢ иҖҢиҝҷжӯЈжҳҜжңҖжңүи¶Јзҡ„ең°ж–№жүҖеңЁ гҖӮ
жҸҗзӨә
жүҖжңүзҘһз»ҸзҪ‘з»ңзҡ„еҹәжң¬еҚ•дҪҚйғҪжҳҜзҘһз»Ҹе…ғ пјҢ еҹәжң¬ж„ҹзҹҘжңәжҳҜе№ҝд№үзҘһз»Ҹе…ғзҡ„дёҖдёӘзү№дҫӢ пјҢ д»ҺзҺ°еңЁејҖе§Ӣ пјҢ жҲ‘们е°Ҷж„ҹзҹҘжңәз§°дёәдёҖдёӘзҘһз»Ҹе…ғ гҖӮ
1пјҺPythonзүҲзҘһз»Ҹе…ғеңЁPythonдёӯ пјҢ и®Ўз®—зҘһз»Ҹе…ғзҡ„иҫ“еҮәжҳҜеҫҲз®ҖеҚ•зҡ„ гҖӮ еӨ§е®¶еҸҜд»Ҙз”Ёnumpyзҡ„dotеҮҪж•°е°ҶдёӨдёӘеҗ‘йҮҸзӣёд№ҳпјҡ
>>> import numpy as np>>> example_input = [1, .2, .1, .05, .2]>>> example_weights = [.2, .12, .4, .6, .90]>>> input_vector = np.array(example_input)>>> weights = np.array(example_weights)>>> bias_weight = .2>>> activation_level = np.dot(input_vector, weights) +\...(bias_weight * 1)?---гҖҖиҝҷйҮҢbias_weight * 1еҸӘжҳҜдёәдәҶејәи°ғbias_weightе’Ңе…¶д»–жқғйҮҚдёҖж ·пјҡжқғйҮҚдёҺиҫ“е…ҘеҖјзӣёд№ҳ пјҢ еҢәеҲ«еҸӘжҳҜbias_weightзҡ„иҫ“е…Ҙзү№еҫҒеҖјжҖ»жҳҜ1>>> activation_level0.674жҺҘдёӢжқҘ пјҢ еҒҮи®ҫжҲ‘们йҖүжӢ©дёҖдёӘз®ҖеҚ•зҡ„йҳҲеҖјжҝҖжҙ»еҮҪж•° пјҢ 并йҖүжӢ©0.5дҪңдёәйҳҲеҖј пјҢ з»“жһңеҰӮдёӢпјҡ
>>> threshold = 0.5>>> if activation_level >= threshold:...perceptron_output = 1... else:...perceptron_output = 0>>> perceptron_output)1еҜ№дәҺз»ҷе®ҡзҡ„иҫ“е…Ҙж ·жң¬example_inputе’ҢжқғйҮҚ пјҢ иҝҷдёӘж„ҹзҹҘжңәе°Ҷдјҡиҫ“еҮә1 гҖӮ еҰӮжһңжңүи®ёеӨҡexample_inputеҗ‘йҮҸ пјҢ иҫ“еҮәе°ҶдјҡжҳҜдёҖдёӘж ҮзӯҫйӣҶеҗҲ пјҢ еӨ§е®¶еҸҜд»ҘжЈҖжҹҘжҜҸж¬Ўж„ҹзҹҘжңәзҡ„йў„жөӢжҳҜеҗҰжӯЈзЎ® гҖӮ
2пјҺиҜҫе Ӯж—¶й—ҙеӨ§е®¶е·Із»Ҹжһ„е»әдәҶдёҖдёӘеҹәдәҺж•°жҚ®иҝӣиЎҢйў„жөӢзҡ„ж–№жі• пјҢ е®ғдёәжңәеҷЁеӯҰд№ еҲӣйҖ дәҶжқЎд»¶ гҖӮ еҲ°зӣ®еүҚдёәжӯў пјҢ жқғйҮҚйғҪдҪңдёәд»»ж„ҸеҖјиҖҢиў«жҲ‘们еҝҪз•ҘдәҶ гҖӮ е®һйҷ…дёҠ пјҢ е®ғ们жҳҜж•ҙдёӘжһ¶жһ„зҡ„е…ій”® пјҢ зҺ°еңЁжҲ‘们йңҖиҰҒдёҖз§Қз®—жі• пјҢ еҹәдәҺз»ҷе®ҡж ·жң¬зҡ„йў„жөӢз»“жһңжқҘи°ғж•ҙжқғйҮҚеҖјзҡ„еӨ§е°Ҹ гҖӮ
ж„ҹзҹҘжңәе°ҶжқғйҮҚзҡ„и°ғж•ҙзңӢжҲҗжҳҜз»ҷе®ҡиҫ“е…ҘдёӢйў„жөӢзі»з»ҹжӯЈзЎ®жҖ§зҡ„дёҖдёӘеҮҪж•° пјҢ д»ҺиҖҢеӯҰд№ иҝҷдәӣжқғйҮҚ гҖӮ дҪҶжҳҜиҝҷдёҖеҲҮд»ҺдҪ•ејҖе§Ӣе‘ўпјҹжңӘз»Ҹи®ӯз»ғзҡ„зҘһз»Ҹе…ғзҡ„жқғйҮҚдёҖејҖе§ӢжҳҜйҡҸжңәзҡ„пјҒйҖҡеёёжҳҜд»ҺжӯЈжҖҒеҲҶеёғдёӯйҖүеҸ–и¶Ӣиҝ‘дәҺйӣ¶зҡ„йҡҸжңәеҖј гҖӮ еңЁеүҚйқўзҡ„дҫӢеӯҗдёӯ пјҢ еӨ§е®¶еҸҜд»ҘзңӢеҲ°д»Һйӣ¶ејҖе§Ӣзҡ„жқғйҮҚпјҲеҢ…жӢ¬еҒҸзҪ®жқғйҮҚпјүдёәдҪ•дјҡеҜјиҮҙиҫ“еҮәе…ЁйғЁдёәйӣ¶ гҖӮ дҪҶжҳҜйҖҡиҝҮи®ҫзҪ®еҫ®е°Ҹзҡ„еҸҳеҢ– пјҢ ж— йЎ»жҸҗдҫӣз»ҷзҘһз»Ҹе…ғеӨӘеӨҡзҡ„иғҪеҠӣ пјҢ зҘһз»Ҹе…ғдҫҝиғҪд»ҘжӯӨдёәдҫқжҚ®еҲӨж–ӯз»“жһңдҪ•ж—¶дёәеҜ№дҪ•ж—¶дёәй”ҷ гҖӮ
жҺЁиҚҗйҳ…иҜ»









![[и®Өзңҹй’“йұј]йғҪдјҡж”№еҸҳдёӯй’©зҺҮпјҢеҸӘжңүиҝҷеҮ з§Қжғ…еҶөпјҢжүҚеә”иҜҘи°ғжјӮпјҢдёҚжҳҜд»Җд№Ҳж—¶еҖҷи°ғй’“](https://imgcdn.toutiaoyule.com/20200327/20200327174520950908a_t.jpeg)
![[еҙӣиө·еҗ§еӨ§еӣҪ科жҠҖ]иҠҜзүҮе’Ңзі»з»ҹйғҪжҲҗеҠҹдәҶпјҢдёәд»Җд№ҲйҖ дёҚеҮәе…үеҲ»жңәпјҹпјҢеҚҺдёәжҠ•е…ҘеӨ§йҮҸиө„йҮ‘](https://imgcdn.toutiaoyule.com/20200405/20200405211240067224a_t.jpeg)







- iQOO 7жҗӯиҪҪйӘҒйҫҷ888еӨ„зҗҶеҷЁе’Ң120Wи¶…е……пјҢ3798е…ғиө·е”®
- жҗӯиҪҪйӘҒйҫҷ888еӨ„зҗҶеҷЁ+120Wи¶…е…… жЁӘеұҸжҖ§иғҪж——иҲ°iQOO 7жӯЈејҸеҸ‘еёғ
- иҷҫзұійҹід№җж’ӯж”ҫеҷЁе°ҶдәҺ2жңҲ5ж—ҘеҒңжӯўжңҚеҠЎпјҢд»ҠејҖеҗҜз”ЁжҲ·иө„дә§еӨ„зҗҶйҖҡйҒ“
- RHEL 9жҸҗеҚҮдәҶx86_64еӨ„зҗҶеҷЁзҡ„е…Ҙй—ЁиҰҒжұӮ
- иҒ”жғіIdeaPad 5 Proзі»еҲ—笔记жң¬еҸ‘еёғ еҸҜйҖүдёӨз§ҚеӨ„зҗҶеҷЁе’ҢдёӨз§Қе°әеҜё
- иҒ”жғіжҺЁеҮәжҗӯиҪҪйӘҒйҫҷеӨ„зҗҶеҷЁзҡ„IdeaPad 5G
- жҖ§иғҪзҝ»еҖҚпјҒйЈһи…ҫйҰ–ж¬ҫ8ж ёжЎҢйқўеӨ„зҗҶеҷЁи…ҫй”җD2000иҜҰи§Ј
- иӢ№жһңиҮӘз ”ж–°еӨ„зҗҶеҷЁжӣқе…үпјҡ64ж ёеҝғ
- жҺЁиҝӣ|жҲ‘еӣҪд»Ҡе№ҙе°ҶжҺЁиҝӣеҝ«йҖ’вҖңиҝӣжқ‘вҖқвҖңиҝӣеҺӮвҖқвҖңеҮәжө·вҖқжһ„е»әж—ҘеӨ„зҗҶи¶…10дәҝ件еҜ„йҖ’зҪ‘з»ң
- ж”Ҝд»ҳеӨ„зҗҶе…¬еҸёJuspayеҸ‘з”ҹж•°жҚ®жі„жјҸпјҡ1дәҝз”ЁжҲ·дҝЎжҒҜеңЁжҡ—зҪ‘еҮәе”®