е®һи·өдёӯеҰӮдҪ•дјҳеҢ–MySQL(е»ә议收и—ҸпјҒ)
- SQLиҜӯеҸҘзҡ„дјҳеҢ–пјҡ
- 1гҖҒе°ҪйҮҸйҒҝе…ҚдҪҝз”ЁеӯҗжҹҘиҜў
- 3гҖҒз”ЁINжқҘжӣҝжҚўOR
- 4гҖҒLIKEеүҚзјҖ%еҸ·гҖҒеҸҢзҷҫеҲҶеҸ·гҖҒ_дёӢеҲ’зәҝжҹҘиҜўйқһзҙўеј•еҲ—жҲ–*ж— жі•дҪҝз”ЁеҲ°зҙўеј• пјҢ еҰӮжһңжҹҘиҜўзҡ„жҳҜзҙўеј•еҲ—еҲҷеҸҜд»Ҙ
- 5гҖҒиҜ»еҸ–йҖӮеҪ“зҡ„и®°еҪ•LIMIT M,N пјҢ иҖҢдёҚиҰҒиҜ»еӨҡдҪҷзҡ„и®°еҪ•
- 6гҖҒйҒҝе…Қж•°жҚ®зұ»еһӢдёҚдёҖиҮҙ
- 7гҖҒеҲҶз»„з»ҹи®ЎеҸҜд»ҘзҰҒжӯўжҺ’еәҸsort пјҢ жҖ»е’ҢжҹҘиҜўеҸҜд»ҘзҰҒжӯўжҺ’йҮҚз”Ёunion all
- 8гҖҒйҒҝе…ҚйҡҸжңәеҸ–и®°еҪ•
- 9гҖҒзҰҒжӯўдёҚеҝ…иҰҒзҡ„ORDER BYжҺ’еәҸ
- 10гҖҒжү№йҮҸINSERTжҸ’е…Ҙ
- 11гҖҒдёҚиҰҒдҪҝз”ЁNOTзӯүиҙҹеҗ‘жҹҘиҜўжқЎд»¶
- 12гҖҒе°ҪйҮҸдёҚз”Ёselect *
- 13гҖҒ**еҢәеҲҶinе’Ңexists**
- зҙўеј•зҡ„дјҳеҢ–пјҡ
- 1гҖҒJoinиҜӯеҸҘзҡ„дјҳеҢ–
- 2гҖҒйҒҝе…Қзҙўеј•еӨұж•Ҳ
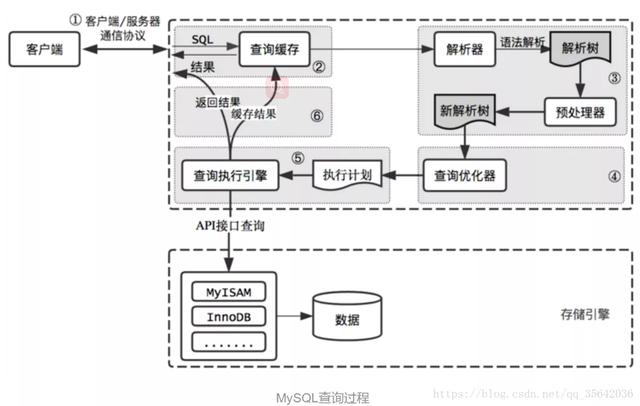 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫв‘ SQLиҜӯеҸҘеҸҠзҙўеј•зҡ„дјҳеҢ–SQLиҜӯеҸҘзҡ„дјҳеҢ–пјҡ1гҖҒе°ҪйҮҸйҒҝе…ҚдҪҝз”ЁеӯҗжҹҘиҜў
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ2гҖҒйҒҝе…ҚеҮҪж•°зҙўеј•
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ3гҖҒз”ЁINжқҘжӣҝжҚўOR
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫеҸҰеӨ– пјҢ MySQLеҜ№дәҺINеҒҡдәҶзӣёеә”зҡ„дјҳеҢ– пјҢ еҚіе°ҶINдёӯзҡ„еёёйҮҸе…ЁйғЁеӯҳеӮЁеңЁдёҖдёӘж•°з»„йҮҢйқў пјҢ иҖҢдё”иҝҷдёӘж•°з»„жҳҜжҺ’еҘҪеәҸзҡ„ гҖӮ дҪҶжҳҜеҰӮжһңж•°еҖјиҫғеӨҡ пјҢ дә§з”ҹзҡ„ж¶ҲиҖ—д№ҹжҳҜжҜ”иҫғеӨ§зҡ„ гҖӮ еҶҚдҫӢеҰӮпјҡselect id from table_name where num in(1,2,3) еҜ№дәҺиҝһз»ӯзҡ„ж•°еҖј пјҢ иғҪз”Ё between е°ұдёҚиҰҒз”Ё in дәҶпјӣеҶҚжҲ–иҖ…дҪҝз”ЁиҝһжҺҘжқҘжӣҝжҚў гҖӮ
4гҖҒLIKEеүҚзјҖ%еҸ·гҖҒеҸҢзҷҫеҲҶеҸ·гҖҒ_дёӢеҲ’зәҝжҹҘиҜўйқһзҙўеј•еҲ—жҲ–*ж— жі•дҪҝз”ЁеҲ°зҙўеј• пјҢ еҰӮжһңжҹҘиҜўзҡ„жҳҜзҙўеј•еҲ—еҲҷеҸҜд»Ҙ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ5гҖҒиҜ»еҸ–йҖӮеҪ“зҡ„и®°еҪ•LIMIT M,N пјҢ иҖҢдёҚиҰҒиҜ»еӨҡдҪҷзҡ„и®°еҪ•
select id,name from table_name limit 866613, 20дҪҝз”ЁдёҠиҝ°sqlиҜӯеҸҘеҒҡеҲҶйЎөзҡ„ж—¶еҖҷ пјҢ еҸҜиғҪжңүдәәдјҡеҸ‘зҺ° пјҢ йҡҸзқҖиЎЁж•°жҚ®йҮҸзҡ„еўһеҠ пјҢ зӣҙжҺҘдҪҝз”ЁlimitеҲҶйЎөжҹҘиҜўдјҡи¶ҠжқҘи¶Ҡж…ў гҖӮдјҳеҢ–зҡ„ж–№жі•еҰӮдёӢпјҡеҸҜд»ҘеҸ–еүҚдёҖйЎөзҡ„жңҖеӨ§иЎҢж•°зҡ„id пјҢ 然еҗҺж №жҚ®иҝҷдёӘжңҖеӨ§зҡ„idжқҘйҷҗеҲ¶дёӢдёҖйЎөзҡ„иө·зӮ№ гҖӮ жҜ”еҰӮжӯӨеҲ—дёӯ пјҢ дёҠдёҖйЎөжңҖеӨ§зҡ„idжҳҜ866612 гҖӮ sqlеҸҜд»ҘйҮҮз”ЁеҰӮдёӢзҡ„еҶҷжі•пјҡ
select id,name from table_name where id> 866612 limit 206гҖҒйҒҝе…Қж•°жҚ®зұ»еһӢдёҚдёҖиҮҙ7гҖҒеҲҶз»„з»ҹи®ЎеҸҜд»ҘзҰҒжӯўжҺ’еәҸsort пјҢ жҖ»е’ҢжҹҘиҜўеҸҜд»ҘзҰҒжӯўжҺ’йҮҚз”Ёunion all ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫunionе’Ңunion allзҡ„е·®ејӮдё»иҰҒжҳҜеүҚиҖ…йңҖиҰҒе°Ҷз»“жһңйӣҶеҗҲ并еҗҺеҶҚиҝӣиЎҢе”ҜдёҖжҖ§иҝҮж»Өж“ҚдҪң пјҢ иҝҷе°ұдјҡж¶үеҸҠеҲ°жҺ’еәҸ пјҢ еўһеҠ еӨ§йҮҸзҡ„CPUиҝҗз®— пјҢ еҠ еӨ§иө„жәҗж¶ҲиҖ—еҸҠ延иҝҹ гҖӮ **еҪ“然 пјҢ union allзҡ„еүҚжҸҗжқЎд»¶жҳҜдёӨдёӘз»“жһңйӣҶжІЎжңүйҮҚеӨҚж•°жҚ® гҖӮ **жүҖд»ҘдёҖиҲ¬жҳҜжҲ‘们жҳҺзЎ®зҹҘйҒ“дёҚдјҡеҮәзҺ°йҮҚеӨҚж•°жҚ®зҡ„ж—¶еҖҷжүҚе»әи®®дҪҝз”Ё union all жҸҗй«ҳйҖҹеәҰ гҖӮ
еҸҰеӨ– пјҢ еҰӮжһңжҺ’еәҸеӯ—ж®өжІЎжңүз”ЁеҲ°зҙўеј• пјҢ е°ұе°ҪйҮҸе°‘жҺ’еәҸпјӣ
8гҖҒйҒҝе…ҚйҡҸжңәеҸ–и®°еҪ•
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ9гҖҒзҰҒжӯўдёҚеҝ…иҰҒзҡ„ORDER BYжҺ’еәҸ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ10гҖҒжү№йҮҸINSERTжҸ’е…Ҙ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ11гҖҒдёҚиҰҒдҪҝз”ЁNOTзӯүиҙҹеҗ‘жҹҘиҜўжқЎд»¶дҪ еҸҜд»ҘжғіиұЎдёҖдёӢ пјҢ еҜ№дәҺдёҖжЈөB+ж ‘ пјҢ ж №иҠӮзӮ№жҳҜ40 пјҢ еҰӮжһңдҪ зҡ„жқЎд»¶жҳҜзӯүдәҺ20 пјҢ е°ұеҺ»е·ҰйқўжҹҘ пјҢ дҪ зҡ„жқЎд»¶зӯүдәҺ50 пјҢ е°ұеҺ»еҸійқўжҹҘ пјҢ дҪҶжҳҜдҪ зҡ„жқЎд»¶жҳҜдёҚзӯүдәҺ66 пјҢ зҙўеј•еә”иҜҘе’ӢеҠһпјҹиҝҳдёҚжҳҜйҒҚеҺҶдёҖйҒҚжүҚзҹҘйҒ“ гҖӮ
жҺЁиҚҗйҳ…иҜ»
![з»ҝиҢ¶е’Ңй…ёеҘ¶еҸҜд»ҘеҗҢж—¶е–қеҗ—пјҹ[з»ҝиҢ¶]](/renwen/images/defaultpic.gif)

















- еӨ§дёҖйқһи®Ўз®—жңәдё“дёҡзҡ„еӯҰз”ҹпјҢеҰӮдҪ•еҲ©з”ЁеҜ’еҒҮиҮӘеӯҰCиҜӯиЁҖ
- еҗ‘ж—Ҙи‘өиҝңзЁӢжҺ§еҲ¶дјҒдёҡзүҲе®ўжҲ·з«Ҝжӣҙж–°еҚҮзә§пјҢдјҳеҢ–иҝңжҺ§UIйҖӮй…ҚSADDCеҶ…ж ёз®—жі•
- зәўзұіK40жёІжҹ“еӣҫжӣқе…үпјҡеұ…дёӯжҢ–еӯ”+еҗҺзҪ®еӣӣж‘„пјҢиҝҷеӨ–и§ӮдҪ и§үеҫ—еҰӮдҪ•пјҹ
- и§ҶзҪ‘иҶңдјҳеҢ–пјҹзҙўе°је…·и®ӨзҹҘиғҪеҠӣз”өи§ҶиҠҜзүҮXRжқҘдәҶ
- еҘӢж–—|иҜҘеҰӮдҪ•зңӢеҫ…жӢјеӨҡеӨҡе‘ҳе·ҘзҢқжӯ»пјҡйј“еҠұеҘӢж–—пјҢд№ҹиҰҒдҝқжҠӨеҘҪеҘӢж–—иҖ…
- иЈ…жңәзӮ№дёҚдә® еҰӮдҪ•з®Җжҳ“жҺ’жҹҘ硬件问йўҳпјҹ
- иҷҫзұійҹід№җе®Јеёғе…іеҒңпјҒжҲ‘зҡ„жӯҢеҚ•еҰӮдҪ•еҜје…ҘQQйҹід№җгҖҒзҪ‘жҳ“дә‘йҹід№җпјҹ
- дәәи„ёиҜҶеҲ«и®ҫеӨҮдё»жқҝеҰӮдҪ•йҖүеһӢ иҪҜзЎ¬ж•ҙеҗҲеӨ§е№…зј©зҹӯејҖеҸ‘ж—¶й—ҙ
- еҫ®иҪҜе®ҳж–№ж•°жҚ®жҒўеӨҚе·Ҙе…·еҚіе°Ҷжӣҙж–°пјҡжӣҙжҳ“дәҺдёҠжүӢ дјҳеҢ–жҒўеӨҚжҖ§иғҪ
- Mini-LEDдә§е“Ғж•Ҳжһң究з«ҹеҰӮдҪ•пјҹ