学习扩增:联合数据扩增和针对文本识别的网络优化( 二 )
总结:论文在文本识别上提出了一种新的数据扩增方法 , 这种方法被设计出用于顺序式的特征扩增 , 它主要的核心在于关注图像的空间转换 。 它首先将图形分成一些方形小块 , 并将方形小块的顶点当作转换的基准点 , 通过对这些基准点的操作来完成图形文本转换 , 生成新的样本 。 完成一系列流程 。
存在的问题与传统的相关工作:
a. 图像文本识别:
存在的问题:图像文本的特征多样导致文本字符串识别比单纯的特征识别更加困难 。
常用的方法:传统的图像文本识别的两种类型:基于定位、无分割 。
传统的方法:He 与 Sshi 等人采取的方法为将循环神经网络加入到卷积神经网络当中 。 Luo 与 Shi 等人提出整流网络的方法来减少识别难度 。 Zhan 与 Lu 等人并通过迭代对图像进行透明度变化 , 通过对图像中的每一个特征使用更多的几何限制来使识别更加准确 。
b. 手写文本识别
存在的问题:不同的人的书写风格不同 。
传统的方法:Sueiras 与 Sun 等人通过卷积神经网络与循环神经网络来获取卓越的成果 。 Zhang 等人通过域适应网络来处理书写方式的多样化 。 Bhunia 等人特征空间的对央行来扩增训练集 。
c. 数据扩增
存在的问题:在深度神经网络当中的训练出现过拟合的现象 , 传统的方法不能满足特征的多样性 。
传统的方法:由于静态扩增方针不能满足动态需求 , Cubuk 等人提出强化学习的方法 。 Ho 等人提出使用灵活的扩增方针计划来加速搜索过程 。 Peng 等人通过预训练过程的方法来扩增样本 。
文章的方法与流程方法:通过结合代理网络 , 扩增模型与识别网络这三个主要模型来组成框架 。
流程:初始化基准点——>通过代理网络来随机的移动基准点——>扩增模型对图像进行转换——>识别器预测文本字符串的扩增图像——>衡量识别器对扩增图像的识别难度(其中的一个验证依据为基准点的移动距离)
实验验证过程:两个研究点:移动的方向、移动的距离
分成 N 个方形区域 , 因此产生 2(N+1)个基准点 。
移动基准点 u , 记录移动段 距离 Wi , 设定移动最大半径 pi,以此进行推导:
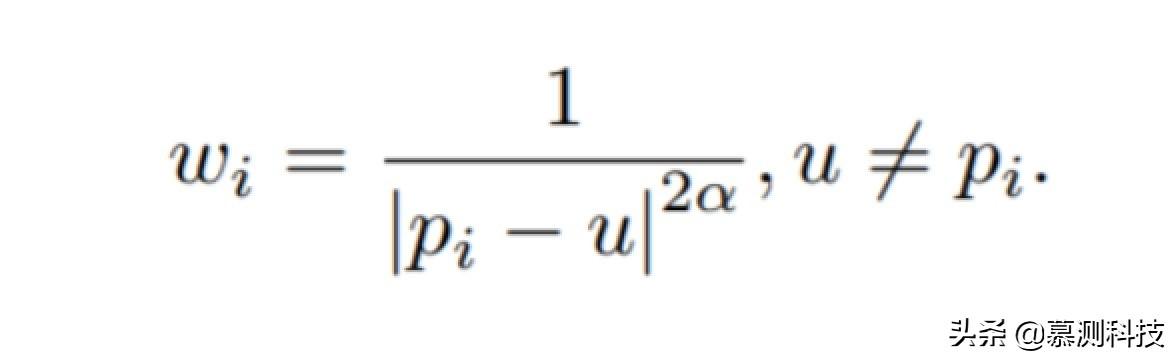 文章插图
文章插图
生成的数据分为对应的样本集 , 对样本的特征多样性进行分析 。
致谢【学习扩增:联合数据扩增和针对文本识别的网络优化】本论文由南京大学软件学院 2021 级学生何家伟转述 。
推荐阅读
















- 计算机专业大一下学期,该选择学习Java还是Python
- 假期弯道超车 国美学习“神器”助孩子变身“学霸”
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 市科委与联影集团联合首设“探索者计划”,共推基础及应用基础研究
- 学习大数据是否需要学习JavaEE
- 跨界才是潮流?看看这四款联合跨界手机 款款是精品
- 学习“时代楷模”精神 信息科技创新助跑5G智慧港口
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手