一个爬虫的故事:这是人干的事儿?( 二 )
为了拿到数据 , 我只好也学着去请求这些数据接口 , 不过因为这些网站都有API网关 , 会检查请求的Token或者Authorization之类的认证字段 , 再加上我不知道他们的接口参数格式 , 导致我经常拿不到数据 。
到了最近两年 , 我拿到的网页HTML越来越简单了 , 在浏览器中丰富多彩的页面 , 一查看源代码竟然只有简单几行 , 真是见了鬼了!
终于有一天 , 一个前辈告诉我 , 现在流行单页应用SPA了 , 页面全都是在前端动态生成的 , 拿到的HTML根本没有价值 。
 文章插图
文章插图
这简直欺人太甚了!
一不做二不休 , 我决定弄一个真正的浏览器进来 , 这个内嵌的浏览器没有界面 , 专门为我服务 , 嵌入到我的程序中 , 让他去真正的渲染网页 , 渲染完成后我再去取数据!
这是真正意义上模拟人类去访问网站了 , 再也不用模拟繁琐的数据接口访问 , 也不用担心单页应用 , 前端渲染就前端渲染 , 我再也不怕了!
验证码到后来 , 不知道是谁发明的 , 网站们纷纷用上了一种叫验证码的技术 , 给我们出了难题 。
开始的验证码还算比较简单 , 一般都是些简单的数字、英文字符做了些变形 , 就像这样:
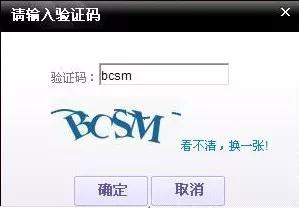 文章插图
文章插图
圈子里很快有大佬教我们用文字识别技术OCR来自动识别这种验证码 , 我也折腾了一下 , 费了老大劲终于可以识别出来 , 准确率不敢说100% , 99%还是有的 。
不过没多久 , 这验证码就变得越来越复杂 , 什么汉字识别 , 物体识别 , 滑动解锁 , 一个比一个难 , 根本超出了我的理解范围 , 你瞧瞧下面这些验证码 , 这是人干的事儿吗?
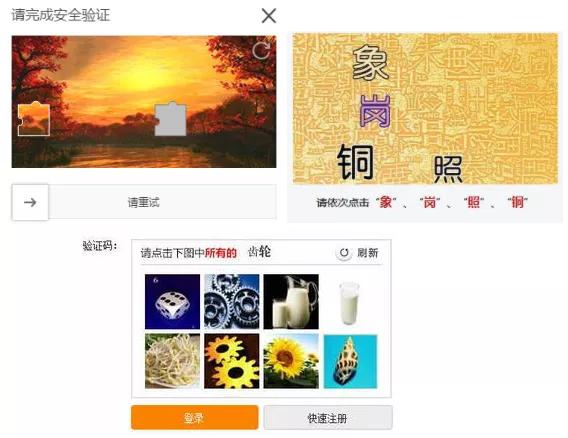 文章插图
文章插图
哎 , 这还真是人才能干的事 , 不是我们爬虫能干的~
如今 , 这些网站的反爬虫技术越来越先进 , 我们能发挥的空间被一步步挤压 。
前段时间 , 有个愣头青爬虫把一家公司的服务器给爬崩溃了 , 把人家正常业务都弄停掉了 , 他还被抓了起来 , 现在监管越来越严 , 搞得大家人心惶惶 。
内忧外患不断 , 不少爬虫兄弟失业的失业 , 转行的转行 , 爬虫这碗饭 , 真是越来越不好吃了 。。。
作者:轩辕之风
来源:编程技术宇宙(ID:xuanyuancoding)
推荐阅读















- 微软Edge迎来一个新的浮层菜单 用于管理下载进度
- 一个亮点解读 创维小湃P3 Pro必须要买的理由
- 华为认证HCIP-GaussDB-OLTP发布,下一个高级DBA会是你吗
- 又黄一个APP,“品牌收购机”成“没落收割机”,收一黄一
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 教你用Siri来控制电脑:真香
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 虾米音乐宣布2月5日关停 人们更关心谁将是下一个
- 虾米音乐一个月后关停 我的听歌记录和个人信息怎么办?
- 华为隐藏一个会议神器,一分钟录入1000字,打字慢的可以看看