еҪ»еә•зҗҶи§Ј IO еӨҡи·ҜеӨҚз”Ёе®һзҺ°жңәеҲ¶( дәҢ )
зј“еӯҳ I/O зҡ„зјәзӮ№пјҡ
ж•°жҚ®еңЁдј иҫ“иҝҮзЁӢдёӯйңҖиҰҒеңЁеә”з”ЁзЁӢеәҸең°еқҖз©әй—ҙе’ҢеҶ…ж ёиҝӣиЎҢеӨҡж¬Ўж•°жҚ®жӢ·иҙқж“ҚдҪң пјҢ иҝҷдәӣж•°жҚ®жӢ·иҙқж“ҚдҪңжүҖеёҰжқҘзҡ„ CPU д»ҘеҸҠеҶ…еӯҳејҖй”ҖжҳҜйқһеёёеӨ§зҡ„ гҖӮ
д»Җд№ҲжҳҜIOеӨҡи·ҜеӨҚз”Ёпјҹ
- IO еӨҡи·ҜеӨҚз”ЁжҳҜдёҖз§ҚеҗҢжӯҘIOжЁЎеһӢ пјҢ е®һзҺ°дёҖдёӘзәҝзЁӢеҸҜд»Ҙзӣ‘и§ҶеӨҡдёӘж–Ү件еҸҘжҹ„пјӣ
- дёҖж—ҰжҹҗдёӘж–Ү件еҸҘжҹ„е°ұз»Ә пјҢ е°ұиғҪеӨҹйҖҡзҹҘеә”з”ЁзЁӢеәҸиҝӣиЎҢзӣёеә”зҡ„иҜ»еҶҷж“ҚдҪңпјӣ
- жІЎжңүж–Ү件еҸҘжҹ„е°ұз»Әе°ұдјҡйҳ»еЎһеә”з”ЁзЁӢеәҸ пјҢ дәӨеҮәCPU гҖӮ
дёәд»Җд№ҲжңүIOеӨҡи·ҜеӨҚз”ЁжңәеҲ¶пјҹжІЎжңүIOеӨҡи·ҜеӨҚз”ЁжңәеҲ¶ж—¶ пјҢ жңүBIOгҖҒNIOдёӨз§Қе®һзҺ°ж–№ејҸ пјҢ дҪҶе®ғ们йғҪжңүдёҖдәӣй—®йўҳ
еҗҢжӯҘйҳ»еЎһпјҲBIOпјү
- жңҚеҠЎз«ҜйҮҮз”ЁеҚ•зәҝзЁӢ пјҢ еҪ“ accept дёҖдёӘиҜ·жұӮеҗҺ пјҢ еңЁ recv жҲ– send и°ғз”Ёйҳ»еЎһж—¶ пјҢ е°Ҷж— жі• accept е…¶д»–иҜ·жұӮпјҲеҝ…йЎ»зӯүдёҠдёҖдёӘиҜ·жұӮеӨ„зҗҶ recv жҲ– send е®Ң пјүпјҲж— жі•еӨ„зҗҶ并еҸ‘пјү
// дјӘд»Јз ҒжҸҸиҝ°while (true) { // acceptйҳ»еЎһclient_fd = accept(listen_fd);fds.append(client_fd);for (fd in fds) {// recvйҳ»еЎһпјҲдјҡеҪұе“ҚдёҠйқўзҡ„acceptпјүif (recv(fd)) {// logic}}}- жңҚеҠЎз«ҜйҮҮз”ЁеӨҡзәҝзЁӢ пјҢ еҪ“ accept дёҖдёӘиҜ·жұӮеҗҺ пјҢ ејҖеҗҜзәҝзЁӢиҝӣиЎҢ recv пјҢ еҸҜд»Ҙе®ҢжҲҗ并еҸ‘еӨ„зҗҶ пјҢ дҪҶйҡҸзқҖиҜ·жұӮж•°еўһеҠ йңҖиҰҒеўһеҠ зі»з»ҹзәҝзЁӢ пјҢ еӨ§йҮҸзҡ„зәҝзЁӢеҚ з”ЁеҫҲеӨ§зҡ„еҶ…еӯҳз©әй—ҙ пјҢ 并且зәҝзЁӢеҲҮжҚўдјҡеёҰжқҘеҫҲеӨ§зҡ„ејҖй”Җ пјҢ 10000дёӘзәҝзЁӢзңҹжӯЈеҸ‘з”ҹиҜ»еҶҷе®һйҷ…зҡ„зәҝзЁӢж•°дёҚдјҡи¶…иҝҮ20% пјҢ жҜҸж¬ЎacceptйғҪејҖдёҖдёӘзәҝзЁӢд№ҹжҳҜдёҖз§Қиө„жәҗжөӘиҙ№ гҖӮ
// дјӘд»Јз ҒжҸҸиҝ°while(true) {// acceptйҳ»еЎһclient_fd = accept(listen_fd)// ејҖеҗҜзәҝзЁӢreadж•°жҚ®пјҲfdеўһеӨҡеҜјиҮҙзәҝзЁӢж•°еўһеӨҡпјүnew Thread func() {// recvйҳ»еЎһпјҲеӨҡзәҝзЁӢдёҚеҪұе“ҚдёҠйқўзҡ„acceptпјүif (recv(fd)) {// logic}}}еҗҢжӯҘйқһйҳ»еЎһпјҲNIOпјү- жңҚеҠЎеҷЁз«ҜеҪ“ accept дёҖдёӘиҜ·жұӮеҗҺ пјҢ еҠ е…Ҙ fds йӣҶеҗҲ пјҢ жҜҸж¬ЎиҪ®иҜўдёҖйҒҚ fds йӣҶеҗҲ recv (йқһйҳ»еЎһ)ж•°жҚ® пјҢ жІЎжңүж•°жҚ®еҲҷз«ӢеҚіиҝ”еӣһй”ҷиҜҜ пјҢ жҜҸж¬ЎиҪ®иҜўжүҖжңү fd пјҲеҢ…жӢ¬жІЎжңүеҸ‘з”ҹиҜ»еҶҷе®һйҷ…зҡ„ fdпјүдјҡеҫҲжөӘиҙ№ CPU гҖӮ
// дјӘд»Јз ҒжҸҸиҝ°while(true) {// acceptйқһйҳ»еЎһпјҲcpuдёҖзӣҙеҝҷиҪ®иҜўпјүclient_fd = accept(listen_fd)if (client_fd != null) {// жңүдәәиҝһжҺҘfds.append(client_fd)} else {// ж— дәәиҝһжҺҘ}for (fd in fds) {// recvйқһйҳ»еЎһsetNonblocking(client_fd)// recv дёәйқһйҳ»еЎһе‘Ҫд»Өif (len = recv(fd)--tt-darkmode-color: #9940C3;">IOеӨҡи·ҜеӨҚз”ЁжңҚеҠЎеҷЁз«ҜйҮҮз”ЁеҚ•зәҝзЁӢйҖҡиҝҮ select/poll/epoll зӯүзі»з»ҹи°ғз”ЁиҺ·еҸ– fd еҲ—иЎЁ пјҢ йҒҚеҺҶжңүдәӢ件зҡ„ fd иҝӣиЎҢ accept/recv/sendпјҢ дҪҝе…¶иғҪж”ҜжҢҒжӣҙеӨҡзҡ„并еҸ‘иҝһжҺҘиҜ·жұӮ гҖӮ
// дјӘд»Јз ҒжҸҸиҝ°while(true) {// йҖҡиҝҮеҶ…ж ёиҺ·еҸ–жңүиҜ»еҶҷдәӢ件еҸ‘з”ҹзҡ„fd пјҢ еҸӘиҰҒжңүдёҖдёӘеҲҷиҝ”еӣһ пјҢ ж— еҲҷйҳ»еЎһ// ж•ҙдёӘиҝҮзЁӢеҸӘеңЁи°ғз”ЁselectгҖҒpollгҖҒepollиҝҷдәӣи°ғз”Ёзҡ„ж—¶еҖҷжүҚдјҡйҳ»еЎһ пјҢ accept/recvжҳҜдёҚдјҡйҳ»еЎһfor (fd in select(fds)) {if (fd == listen_fd) {client_fd = accept(listen_fd)fds.append(client_fd)} elseif (len = recv(fd)--tt-darkmode-color: #9940C3;">IOеӨҡи·ҜеӨҚз”Ёзҡ„дёүз§Қе®һзҺ°- select
- poll
- epoll
selectе®ғд»…д»…зҹҘйҒ“дәҶ пјҢ жңүI/OдәӢ件еҸ‘з”ҹдәҶ пјҢ еҚҙ并дёҚзҹҘйҒ“жҳҜе“ӘйӮЈеҮ дёӘжөҒпјҲеҸҜиғҪжңүдёҖдёӘ пјҢ еӨҡдёӘ пјҢ з”ҡиҮіе…ЁйғЁпјү пјҢ жҲ‘们еҸӘиғҪж— е·®еҲ«иҪ®иҜўжүҖжңүжөҒ пјҢ жүҫеҮәиғҪиҜ»еҮәж•°жҚ® пјҢ жҲ–иҖ…еҶҷе…Ҙж•°жҚ®зҡ„жөҒ пјҢ еҜ№д»–们иҝӣиЎҢж“ҚдҪң гҖӮ жүҖд»Ҙselectе…·жңүO(n)зҡ„ж— е·®еҲ«иҪ®иҜўеӨҚжқӮеәҰ пјҢ еҗҢж—¶еӨ„зҗҶзҡ„жөҒи¶ҠеӨҡ пјҢ ж— е·®еҲ«иҪ®иҜўж—¶й—ҙе°ұи¶Ҡй•ҝ гҖӮ
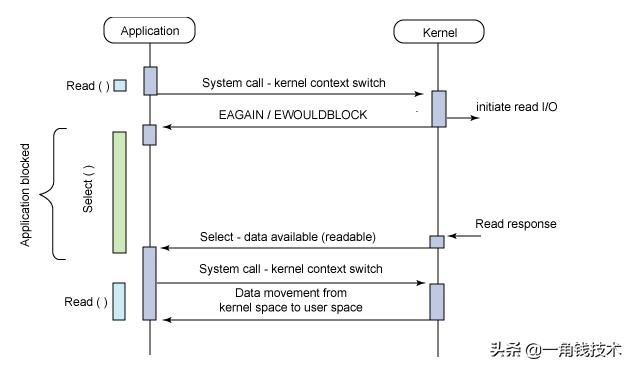
selectи°ғз”ЁиҝҮзЁӢ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
пјҲ1пјүдҪҝз”Ёcopy_from_userд»Һз”ЁжҲ·з©әй—ҙжӢ·иҙқfd_setеҲ°еҶ…ж ёз©әй—ҙ
пјҲ2пјүжіЁеҶҢеӣһи°ғеҮҪж•°__pollwait
пјҲ3пјүйҒҚеҺҶжүҖжңүfd пјҢ и°ғз”Ёе…¶еҜ№еә”зҡ„pollж–№жі•пјҲеҜ№дәҺsocket пјҢ иҝҷдёӘpollж–№жі•жҳҜsock_poll пјҢ sock_pollж №жҚ®жғ…еҶөдјҡи°ғз”ЁеҲ°tcp_poll,udp_pollжҲ–иҖ…datagram_pollпјү
жҺЁиҚҗйҳ…иҜ»
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- жӣҫиў«дә¬дёңзү©жөҒж•Ҳд»ҝпјҢи®©йӣ·еҶӣиҠұ1дәҝжӢҜж•‘пјҢеҰӮд»Ҡж¬ 7000дёҮеҪ»еә•еҮәеұҖ
- зәҝдёӢеёӮеңәеҪ»еә•вҖңд№ұдәҶвҖқпјҒе°Ҹзұіе®Јеёғ新规пјҒеҚҺдёәжҚҶз»‘еҠ д»·иЎҢдёәиҝҺдәүи®®
- дёҖжіўжңӘе№ідёҖжіўеҸҲиө·пјҢжҲ‘д№°дёӘиҸңе°ұж¬ дәҶдёҖ笔иҙ·ж¬ҫпјҹзҫҺеӣўиҝҷж¬ЎеҪ»еә•жІЎиҜқиҜҙ
- еҫ®иҪҜ|еӨ–еӘ’пјҡеҫ®иҪҜе°ҶеҜ№Windows 10з•ҢйқўиҝӣиЎҢеҪ»еә•ж”№иҝӣ е·ІжӢӣе…ө买马
- еҚҺдёәP50зңҹжңәеӣҫжӣқе…үпјҡеӨ–еҪўеҸҳеҢ–еҫҲеҪ»еә•
- дә¬дёң7FRESHиҝҺжқҘеҪ»еә•еҸҳйқ©
- Windows 10зӯүиҪҜ件全йғЁе°ҒжқҖ FlashеҪ»еә•иҜҙеҶҚи§Ғ
- ж•°жҚ®|ж–°еҹәе»әж—¶д»ЈпјҢй«ҳеӨ§е…Ёзҡ„ж•°жҚ®з®ЎзҗҶи§ЈеҶіж–№жЎҲжҳҜжҖҺж ·вҖңзӮјвҖқжҲҗзҡ„пјҹ
- е°јеә·зӣёжңәе°ҶдәҺ2021е№ҙеә•еүҚеҪ»еә•е‘ҠеҲ«вҖңж—Ҙжң¬дә§вҖқ
- еҫ®дҝЎзҡ„дёҖйЎ№жӣҙж–°пјҢеҪ»еә•и®©з”ЁжҲ·вҖңеҸҚж„ҹвҖқпјҢиҝҷжҳҜиҰҒејҖеҗҜзӣҙж’ӯж—¶д»Јпјҹ






![[vivo]дёӨеҚғе·ҰеҸіеҸҜд»Ҙжҗһе®ҡзҡ„5Gдёӯз«ҜжңәпјҡдёҖж¬ҫ120Hzй«ҳеҲ·еұҸпјҢеҸҰдёҖж¬ҫз»ӯиҲӘжҖӘе…Ҫ](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/4c382528b7b9d7f7ebee19b4bbca1156.jpg)