CPU жү§иЎҢзЁӢеәҸзҡ„з§ҳеҜҶпјҢи—ҸеңЁдәҶиҝҷ 15 еј еӣҫйҮҢ( еӣӣ )
CPU д»ҺзЁӢеәҸи®Ўж•°еҷЁиҜ»еҸ–жҢҮд»ӨгҖҒеҲ°жү§иЎҢгҖҒеҶҚеҲ°дёӢдёҖжқЎжҢҮд»Ө пјҢ иҝҷдёӘиҝҮзЁӢдјҡдёҚж–ӯеҫӘзҺҜ пјҢ зӣҙеҲ°зЁӢеәҸжү§иЎҢз»“жқҹ пјҢ иҝҷдёӘдёҚж–ӯеҫӘзҺҜзҡ„иҝҮзЁӢиў«з§°дёә CPU зҡ„жҢҮд»Өе‘Ёжңҹ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫa = 1 + 2 жү§иЎҢе…·дҪ“иҝҮзЁӢзҹҘйҒ“дәҶеҹәжң¬зҡ„зЁӢеәҸжү§иЎҢиҝҮзЁӢеҗҺ пјҢ жҺҘдёӢжқҘз”Ё a = 1 + 2 зҡ„дҪңдёәдҫӢеӯҗ пјҢ иҝӣдёҖжӯҘеҲҶжһҗиҜҘзЁӢеәҸеңЁеҶҜиҜәдјҠжӣјжЁЎеһӢзҡ„жү§иЎҢиҝҮзЁӢ гҖӮ
CPU жҳҜдёҚи®ӨиҜҶ a = 1 + 2 иҝҷдёӘеӯ—з¬ҰдёІ пјҢ иҝҷдәӣеӯ—з¬ҰдёІеҸӘжҳҜж–№дҫҝжҲ‘们зЁӢеәҸе‘ҳи®ӨиҜҶ пјҢ иҰҒжғіиҝҷж®өзЁӢеәҸиғҪи·‘иө·жқҘ пјҢ иҝҳйңҖиҰҒжҠҠж•ҙдёӘзЁӢеәҸзҝ»иҜ‘жҲҗжұҮзј–иҜӯиЁҖзҡ„зЁӢеәҸ пјҢ иҝҷдёӘиҝҮзЁӢз§°дёәзј–иҜ‘жҲҗжұҮзј–д»Јз Ғ гҖӮ
й’ҲеҜ№жұҮзј–д»Јз Ғ пјҢ жҲ‘们иҝҳйңҖиҰҒз”ЁжұҮзј–еҷЁзҝ»иҜ‘жҲҗжңәеҷЁз Ғ пјҢ иҝҷдәӣжңәеҷЁз Ғз”ұ 0 е’Ң 1 з»„жҲҗзҡ„жңәеҷЁиҜӯиЁҖ пјҢ иҝҷдёҖжқЎжқЎжңәеҷЁз Ғ пјҢ е°ұжҳҜдёҖжқЎжқЎзҡ„и®Ўз®—жңәжҢҮд»Ө пјҢ иҝҷдёӘжүҚжҳҜ CPU иғҪеӨҹзңҹжӯЈи®ӨиҜҶзҡ„дёңиҘҝ гҖӮ
дёӢйқўжқҘзңӢзңӢ a = 1 + 2 еңЁ 32 дҪҚ CPU зҡ„жү§иЎҢиҝҮзЁӢ гҖӮ
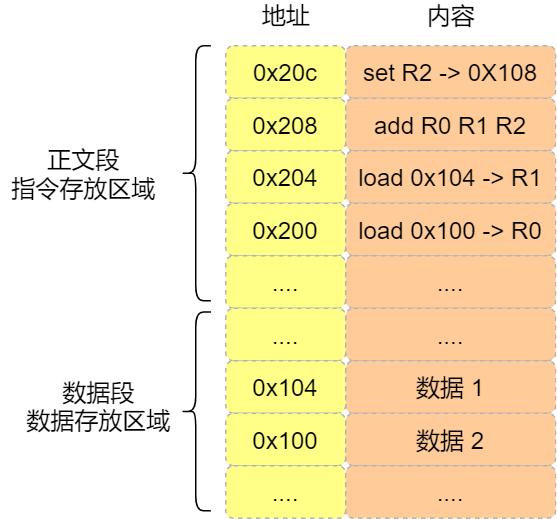
зЁӢеәҸзј–иҜ‘иҝҮзЁӢдёӯ пјҢ зј–иҜ‘еҷЁйҖҡиҝҮеҲҶжһҗд»Јз Ғ пјҢ еҸ‘зҺ° 1 е’Ң 2 жҳҜж•°жҚ® пјҢ дәҺжҳҜзЁӢеәҸиҝҗиЎҢж—¶ пјҢ еҶ…еӯҳдјҡжңүдёӘдё“й—Ёзҡ„еҢәеҹҹжқҘеӯҳж”ҫиҝҷдәӣж•°жҚ® пјҢ иҝҷдёӘеҢәеҹҹе°ұжҳҜгҖҢж•°жҚ®ж®өгҖҚ гҖӮ еҰӮдёӢеӣҫ пјҢ ж•°жҚ® 1 е’Ң 2 зҡ„еҢәеҹҹдҪҚзҪ®пјҡ
- ж•°жҚ® 1 иў«еӯҳж”ҫеҲ° 0x100 дҪҚзҪ®пјӣ
- ж•°жҚ® 2 иў«еӯҳж”ҫеҲ° 0x104 дҪҚзҪ®пјӣ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫзј–иҜ‘еҷЁдјҡжҠҠ a = 1 + 2 зҝ»иҜ‘жҲҗ 4 жқЎжҢҮд»Ө пјҢ еӯҳж”ҫеҲ°жӯЈж–Үж®өдёӯ гҖӮ еҰӮеӣҫ пјҢ иҝҷ 4 жқЎжҢҮд»Өиў«еӯҳж”ҫеҲ°дәҶ 0x200 ~ 0x20c зҡ„еҢәеҹҹдёӯпјҡ
- 0x200 зҡ„еҶ…е®№жҳҜ load жҢҮд»Өе°Ҷ 0x100 ең°еқҖдёӯзҡ„ж•°жҚ® 1 иЈ…е…ҘеҲ°еҜ„еӯҳеҷЁ R0пјӣ
- 0x204 зҡ„еҶ…е®№жҳҜ load жҢҮд»Өе°Ҷ 0x104 ең°еқҖдёӯзҡ„ж•°жҚ® 2 иЈ…е…ҘеҲ°еҜ„еӯҳеҷЁ R1пјӣ
- 0x208 зҡ„еҶ…е®№жҳҜ add жҢҮд»Өе°ҶеҜ„еӯҳеҷЁ R0 е’Ң R1 зҡ„ж•°жҚ®зӣёеҠ пјҢ 并жҠҠз»“жһңеӯҳж”ҫеҲ°еҜ„еӯҳеҷЁ R2пјӣ
- гҖҗCPU жү§иЎҢзЁӢеәҸзҡ„з§ҳеҜҶпјҢи—ҸеңЁдәҶиҝҷ 15 еј еӣҫйҮҢгҖ‘0x20c зҡ„еҶ…е®№жҳҜ store жҢҮд»Өе°ҶеҜ„еӯҳеҷЁ R2 дёӯзҡ„ж•°жҚ®еӯҳеӣһж•°жҚ®ж®өдёӯзҡ„ 0x108 ең°еқҖдёӯ пјҢ иҝҷдёӘең°еқҖд№ҹе°ұжҳҜеҸҳйҮҸ a еҶ…еӯҳдёӯзҡ„ең°еқҖпјӣ
дёҠйқўзҡ„дҫӢеӯҗдёӯ пјҢ з”ұдәҺжҳҜеңЁ 32 дҪҚ CPU жү§иЎҢзҡ„ пјҢ еӣ жӯӨдёҖжқЎжҢҮд»ӨжҳҜеҚ 32 дҪҚеӨ§е°Ҹ пјҢ жүҖд»ҘдҪ дјҡеҸ‘зҺ°жҜҸжқЎжҢҮд»Өй—ҙйҡ” 4 дёӘеӯ—иҠӮ гҖӮ
иҖҢж•°жҚ®зҡ„еӨ§е°ҸжҳҜж №жҚ®дҪ еңЁзЁӢеәҸдёӯжҢҮе®ҡзҡ„еҸҳйҮҸзұ»еһӢ пјҢ жҜ”еҰӮ int зұ»еһӢзҡ„ж•°жҚ®еҲҷеҚ 4 дёӘеӯ—иҠӮ пјҢ char зұ»еһӢзҡ„ж•°жҚ®еҲҷеҚ 1 дёӘеӯ—иҠӮ гҖӮ
жҢҮд»ӨдёҠйқўзҡ„дҫӢеӯҗдёӯ пјҢ еӣҫдёӯжҢҮд»Өзҡ„еҶ…е®№жҲ‘еҶҷзҡ„жҳҜз®Җжҳ“зҡ„жұҮзј–д»Јз Ғ пјҢ зӣ®зҡ„жҳҜдёәдәҶж–№дҫҝзҗҶи§ЈжҢҮд»Өзҡ„е…·дҪ“еҶ…е®№ пјҢ дәӢе®һдёҠжҢҮд»Өзҡ„еҶ…е®№жҳҜдёҖдёІдәҢиҝӣеҲ¶ж•°еӯ—зҡ„жңәеҷЁз Ғ пјҢ жҜҸжқЎжҢҮд»ӨйғҪжңүеҜ№еә”зҡ„жңәеҷЁз Ғ пјҢ CPU йҖҡиҝҮи§ЈжһҗжңәеҷЁз ҒжқҘзҹҘйҒ“жҢҮд»Өзҡ„еҶ…е®№ гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- зЁӢеәҸе‘ҳдёәж•ҷеёҲеҰ»еӯҗејҖеҸ‘еә”з”Ёпјҡе°ҶiPhoneеҸҳжҲҗж–ҮжЎЈж‘„еғҸеӨҙ
- йЈһд№Ұж–ҮжЎЈеҫ®дҝЎе°ҸзЁӢеәҸе®Ўж ёиў«еҚЎпјҹеӯ—иҠӮи·іеҠЁеүҜжҖ»иЈҒи°ўж¬ЈпјҡеёҢжңӣи…ҫи®ҜеҒңжӯўж— зҗҶз”ұе°ҒжқҖ
- еӨҡ家еҝ«йҖ’жҡӮеҒңеҸ‘еҫҖжІіеҢ—зңҒеҝ«д»¶пјҢйЎәдё°иЎЁзӨәе…ҲжҡӮеҒңдёүеӨ©пјҢдә¬дёңе°ҸзЁӢеәҸе·Іж— жі•дёӢеҚ•
- 2021е№ҙжҚўжүӢжңәе“ӘдёӘй…ҚзҪ®жңҖйҮҚиҰҒпјҢCPUеҸӘиғҪжҺ’第дёүдҪҚ
- 8ж ёZen3 AMDж–°CPUзҺ°иә«пјҡй”җйҫҷ7 5700G
- е…Ёж–°8ж ёеӣҪдә§CPUж·ұе…ҘжҺўз§ҳпјҡ马дёҠиғҪд№°еҲ°
- еӯ—иҠӮи·іеҠЁй«ҳз®Ўе–ҠиҜқи…ҫи®ҜпјҢз§°вҖңйЈһд№Ұж–ҮжЎЈвҖқе°ҸзЁӢеәҸе®Ўж ёиў«еҚЎиҝ‘дёӨжңҲ
- жӮ”е“ӯпјҒдёҖзЁӢеәҸе‘ҳиҜҜжҠҠ7500дёӘжҜ”зү№еёҒеҪ“еһғеңҫжү”жҺүпјҢдј°з®—зәҰ2.4дәҝзҫҺе…ғ
- иӢ№жһңж”№еҸҳз«Ӣеңә з§°macOSе®һз”ЁзЁӢеәҸAmphetamineеҸҜ继з»ӯз•ҷеңЁMacеә”з”Ёе•Ҷеә—дёӯ
- 2.4дәҝзҫҺе…ғжү“ж°ҙжјӮпјҒзЁӢеәҸе‘ҳе°Ҹе“ҘжҠҠ7500дёӘжҜ”зү№еёҒеҪ“еһғеңҫжү”жҺү зЎ¬зӣҳжүҫдёҚеӣһ