Python正则表达式简介( 二 )
我想展示的另一个例子是搜索和检索字符串内部的子字符串 。 在本例中 , 我将从一个被称为数据科学的“hello world”的数据集中举一个例子 。 这是泰坦尼克号的数据集 。
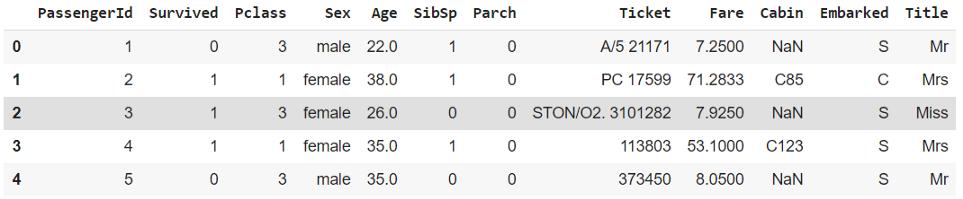
对于那些不知道的人来说 , 这是一个数据集 , 被用来作为Kaggle竞赛的介绍 。 这项竞赛的目标是根据与乘客相对应的数据来预测乘客是否幸存 。 数据集看起来像这样
 文章插图
文章插图
它由几个列组成 , 描述乘客的人口统计、票价、姓名 , 以及描述乘客是否幸存的“Survived”列 。 在本例中 , 让我们关注“Name”列 。 让我们看几个例子 ,
0Braund, Mr. Owen Harris1Cumings, Mrs. John Bradley (Florence Briggs Th...2Heikkinen, Miss. Laina3Futrelle, Mrs. Jacques Heath (Lily May Peel)4Allen, Mr. William Henry5Moran, Mr. James6McCarthy, Mr. Timothy J7Palsson, Master. Gosta Leonard8Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)9Nasser, Mrs. Nicholas (Adele Achem)10Sandstrom, Miss. Marguerite Rut11Bonnell, Miss. Elizabeth12Saundercock, Mr. William Henry13Andersson, Mr. Anders Johan14Vestrom, Miss. Hulda Amanda Adolfina15Hewlett, Mrs. (Mary D Kingcome) 16Rice, Master. Eugene17Williams, Mr. Charles Eugene18Vander Planke, Mrs. Julius (Emelia Maria Vande...19Masselmani, Mrs. FatimaName: Name, dtype: object根据上面的样本 , 你看到它有什么模式吗?如果你详细了解 , 每个名字都有自己的标题 , 例如Mr., Mrs., Miss., Master.等等 。 我们可以将这些名称提取为一个新的函数 , 称为“Title” 。 Title包括了.标点符号 。 因此 , 我们可以使用模式提取它 。
如何从每个名字中提取标题?我们可以使用re库中的一个名为search的函数 。 使用该函数 , 我们可以根据给定的模式提取术语 。 它需要模式和字符串列表 。 代码是这样的
def get_title(x):# 搜索匹配的模式x = re.search('\w*\.', x).group()# 删除点标点符号以简化分析过程x = re.sub('\.', '', x)return xtrain['Title'] = train['Name'].apply(get_title)train = train.drop('Name', axis=1)train.head()确保在搜索字符串中的一个词之后 , 用一个名为group的方法链接函数 。 或者看起来像这样 ,
# 如果不使用group方法 , 它将显示<_sre.SRE_Match object; span=(8, 11), match='Mr.'>如果你做得对 , 结果会是这样的 ,
 文章插图
文章插图
下面是搜索函数及其方法的摘要
re.search(pattern, data)parameters: - pattern: 适合我们想要的模式 - data: 我们使用的数据 。 它可以是字符串或字符串列表methods: - group: 它返回一个或更多个字符串 。 结论以上是我们如何使用正则表达式来处理使用Python的文本 , 这样我们就可以通过删除无意义的信息来获得更有意义的结论解 。 我还向你展示了它的概念和一些应用 。 我希望这篇文章对你有用 。
还有一件事 , 回想一下我上面的代码 , 我写的模式就像一个普通的字符串 。 但是为了确保你编写了一个regex模式 , 请在引用的模式之前添加'r'字符 , 如下所示
【Python正则表达式简介】# 你可以这样写re.sub("#\w+", "", tweet)# 或者像这样re.sub(r"#\w+", "", tweet)
推荐阅读












- 计算机专业大一下学期,该选择学习Java还是Python
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 2021年Java和Python的应用趋势会有什么变化?
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手
- 用Python制作图片验证码,这三行代码完事儿
- 历时 1 个月,做了 10 个 Python 可视化动图,用心且精美...
- 为何在人工智能研发领域Python应用比较多
- 对于非计算机专业的同学来说,该选择学习Python还是C
- 学习完Python之后,如何向人工智能领域发展