жү©еұ•еӣҫзҘһз»ҸзҪ‘з»ңпјҡжҡҙеҠӣе ҶеҸ жЁЎеһӢж·ұеәҰ并дёҚеҸҜеҸ–( дёү )
еңЁжҲ‘们дёҺ Ben ChamberlianгҖҒDavide Eynard д»ҘеҸҠ Federico Monti зӯүдәәиҒ”еҗҲеҸ‘иЎЁзҡ„и®әж–Ү вҖңSIGN: Scalable Inception Graph Neural NetworksвҖқ дёӯ пјҢ жҲ‘д»¬з ”з©¶дәҶдёәиҠӮзӮ№зә§еҲҶзұ»й—®йўҳи®ҫи®Ўз®ҖеҚ•гҖҒдёҺйҮҮж ·ж— е…ізҡ„жһ¶жһ„зҡ„еҸҜиғҪжҖ§ гҖӮ
иҖғиҷ‘еҲ°дёҠж–Үд»Ӣз»Қзҡ„йҮҮж ·жҠҖжңҜзҡ„й—ҙжҺҘеҘҪеӨ„ пјҢ иҜ»иҖ…еҸҜиғҪдјҡй—®пјҡдёәд»Җд№ҲжҲ‘们иҰҒж‘’ејғйҮҮж ·зӯ–з•Ҙе‘ўпјҹ
еҺҹеӣ еҰӮдёӢпјҡиҠӮзӮ№еҲҶзұ»й—®йўҳзҡ„е®һдҫӢд№Ӣй—ҙеҸҜиғҪеӯҳеңЁжҳҫи‘—зҡ„е·®ејӮ пјҢ жҚ®жҲ‘们жүҖзҹҘ пјҢ иҮід»ҠиҝҳжІЎжңүе·ҘдҪңзі»з»ҹең°з ”究дәҶгҖҢдҪ•ж—¶йҮҮж ·гҖҚиғҪзңҹжӯЈиө·еҲ°з§ҜжһҒзҡ„дҪңз”Ё пјҢ иҖҢдёҚжҳҜд»…д»…еҮҸиҪ»дәҶи®Ўз®—еӨҚжқӮеәҰ гҖӮ
еҜ№йҮҮж ·ж–№жЎҲзҡ„е®һзҺ°еј•е…ҘдәҶйўқеӨ–зҡ„еӨҚжқӮжҖ§ пјҢ иҖҢжҲ‘们зӣёдҝЎ пјҢ жҲ‘们йңҖиҰҒзҡ„жҳҜдёҖз§Қз®ҖеҚ•гҖҒејәеӨ§гҖҒдёҺйҮҮж ·ж— е…ігҖҒеҸҜжү©еұ•зҡ„еҹәзәҝжһ¶жһ„ гҖӮ
3 ж–№жі•жҺўз©¶ жҲ‘们зҡ„ж–№жі•еҸ—еҲ°дәҶдёҖдәӣиҝ‘жңҹеҸ‘еёғзҡ„е®һйӘҢз»“жһңзҡ„еҗҜеҸ‘ гҖӮ йҰ–е…Ҳ пјҢ еңЁеҫҲеӨҡжғ…еҶөдёӢ пјҢ з®ҖеҚ•зҡ„еӣәе®ҡзҡ„дҝЎжҒҜиҒҡеҗҲеҷЁпјҲдҫӢеҰӮ GCNпјүжҜ”дёҖдәӣжӣҙеҠ еӨҚжқӮзҡ„дҝЎжҒҜиҒҡеҗҲеҷЁпјҲдҫӢеҰӮ пјҢ GAT е’Ң MPNNпјүжҖ§иғҪжӣҙеҘҪ гҖӮ
жӯӨеӨ– пјҢ е°Ҫз®Ўж·ұеәҰеӯҰд№ зҡ„жҲҗеҠҹжҳҜе»әз«ӢеңЁжӢҘжңүеӨҡеұӮзҡ„жЁЎеһӢд№ӢдёҠзҡ„ пјҢ дҪҶжҳҜеңЁеӣҫж·ұеәҰеӯҰд№ йўҶеҹҹдёӯ пјҢ гҖҢжЁЎеһӢжҳҜеҗҰйңҖиҰҒеҫҲж·ұгҖҚд»Қ然жҳҜдёҖдёӘжңүеҫ…и§ЈеҶізҡ„ејҖж”ҫжҖ§й—®йўҳ гҖӮ
е…·дҪ“иҖҢиЁҖ пјҢ Wu зӯүдәәеңЁи®әж–ҮгҖҢSimplifying Graph Convolutional NetworksгҖҚдёӯжҢҮеҮә пјҢ еҸӘжӢҘжңүдёҖдёӘеӨҡи·ідҝЎжҒҜдј ж’ӯеұӮзҡ„ GCN жЁЎеһӢеҸҜд»ҘжӢҘжңүдёҺе…·жңүеӨҡдёӘдҝЎжҒҜдј ж’ӯеұӮзҡ„жЁЎеһӢзӣёеҪ“зҡ„жҖ§иғҪ гҖӮ
йҖҡиҝҮеңЁеҚ•дёӘеҚ·з§ҜеұӮдёӯз»„еҗҲдёҚеҗҢзҡ„гҖҒеӣәе®ҡзҡ„йӮ»еұ…иҠӮзӮ№иҒҡеҗҲеҷЁ пјҢ жҲ‘们еҸҜд»ҘеңЁдёҚдҪҝз”ЁеӣҫйҮҮж ·жҠҖжңҜзҡ„еүҚжҸҗдёӢ пјҢ еҫ—еҲ°е…·жңүйқһеёёеӨ§зҡ„еҸҜжү©еұ•жҖ§зҡ„жЁЎеһӢ гҖӮ жҚўеҸҘиҜқиҜҙ пјҢ жҲ‘们еңЁиҜҘжһ¶жһ„зҡ„第дёҖеұӮиҝӣиЎҢжүҖжңүдёҺеӣҫзӣёе…ізҡ„пјҲеӣәе®ҡзҡ„пјүж“ҚдҪң пјҢ еӣ жӯӨиҝҷдәӣж“ҚдҪңеҸҜд»Ҙиў«йў„и®Ўз®— гҖӮ
жҺҘдёӢжқҘ пјҢ иҝҷдәӣйў„е…ҲиҒҡеҗҲзҡ„дҝЎжҒҜеҸҜд»ҘдҪңдёәжЁЎеһӢе…¶е®ғйғЁеҲҶзҡ„иҫ“е…Ҙ пјҢ иҖҢз”ұдәҺзјәе°‘йӮ»еұ…иҠӮзӮ№зҡ„дҝЎжҒҜиҒҡеҗҲ пјҢ иҝҷдәӣйғЁеҲҶеҸҜд»Ҙиў«еҪ’зәідёәдёҖдёӘеӨҡеұӮж„ҹзҹҘжңәпјҲMLPпјү гҖӮ
йңҖиҰҒжҢҮеҮәзҡ„жҳҜ пјҢ еҚідҪҝжҲ‘们дҪҝз”ЁдәҶиҝҷд№Ҳжө…зҡ„еҚ·з§Ҝж–№жЎҲ пјҢ йҖҡиҝҮйҮҮз”ЁдёҖдәӣпјҲеҸҜиғҪдё“з”Ёзҡ„гҖҒжӣҙеӨҚжқӮзҡ„пјүдҝЎжҒҜдј ж’ӯз®—еӯҗ пјҢ жҲ‘们д»Қ然иғҪдҝқз•ҷеӣҫеҚ·з§Ҝж“ҚдҪңзҡ„иЎЁиҫҫиғҪеҠӣ гҖӮ дҫӢеҰӮ пјҢ жҲ‘们еҸҜд»Ҙи®ҫи®ЎдёҖдәӣз®—еӯҗжқҘиҖғиҷ‘гҖҢеұҖйғЁеӯҗеӣҫи®Ўж•°гҖҚжҲ–еӣҫдёӯзҡ„жЁЎдҪ“пјҲmotifпјү гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
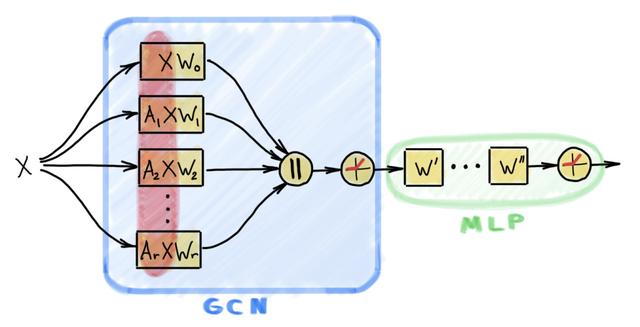
еӣҫ 2пјҡSIGN жһ¶жһ„еҢ…еҗ«дёҖдёӘзұ»дјјдәҺ GCN зҡ„еұӮ пјҢ е®ғеёҰжңүеӨҡдёӘзәҝжҖ§дј ж’ӯз®—еӯҗ пјҢ иҝҷдәӣз®—еӯҗеҸҜиғҪдҪңз”ЁдәҺеӨҡи·ійӮ»еұ…иҠӮзӮ№ гҖӮ еңЁиҝҷдёӘеұӮеҗҺйқў пјҢ дјҡиҝһжҺҘзқҖдёҖдёӘйқўеҗ‘иҠӮзӮ№зә§еҲ«еә”з”Ёзҡ„еӨҡеұӮж„ҹзҹҘжңә гҖӮ иҜҘжһ¶жһ„д№ӢжүҖд»Ҙе…·жңүиҫғй«ҳзҡ„и®Ўз®—ж•ҲзҺҮ пјҢ жҳҜз”ұдәҺеҜ№иў«дј ж’ӯзҡ„зү№еҫҒзҡ„йў„и®Ўз®—пјҲеҰӮеӣҫдёӯзәўиүІйғЁеҲҶжүҖзӨәпјү гҖӮ
жҲ‘们жҸҗеҮәзҡ„еҸҜжү©еұ•жһ¶жһ„иў«з§°дёә SIGN пјҢ е®ғйқўеҗ‘зҡ„жҳҜеҰӮдёӢжүҖзӨәзҡ„иҠӮзӮ№зә§еҲҶзұ»д»»еҠЎпјҡ
Y = softmax(ReLU(XW? | A?XW? | A?XW? | вҖҰ | A?XW?) WвҖҷ)
е…¶дёӯ пјҢ A? жҳҜзәҝжҖ§дј ж’ӯзҹ©йҳөпјҲдҫӢеҰӮдёҖдёӘжӯЈеҲҷеҢ–зҡ„йӮ»жҺҘзҹ©йҳө пјҢ е®ғзҡ„е№Ӯ пјҢ жҲ–иҖ…дёҖдёӘжЁЎдҪ“зҹ©йҳөпјү гҖӮ W? е’Ң WвҖҷ жҳҜеҸҜеӯҰд№ зҡ„еҸӮж•° гҖӮ еҰӮеӣҫ 2 жүҖзӨә пјҢ иҜҘзҪ‘з»ңеҸҜд»ҘйҖҡиҝҮеҠ е…Ҙйқўеҗ‘иҠӮзӮ№зҡ„еұӮеҸҳеҫ—жӣҙж·ұпјҡ
Y = softmax(ReLU(вҖҰReLU(XW? | A?XW? | вҖҰ | A?XW?) WвҖҷ)вҖҰ WвҖҷвҖҷ)
жңҖеҗҺ пјҢ еҪ“жҲ‘们еҜ№зӣёеҗҢзҡ„дј ж’ӯз®—еӯҗеә”з”ЁдёҚеҗҢзҡ„е№ӮпјҲдҫӢеҰӮ пјҢ A?=B1, A?=B2 пјҢ зӯүзӯүпјүж—¶ пјҢ еӣҫж“ҚдҪңжңүж•Ҳең°еңЁи¶ҠжқҘи¶Ҡиҝңзҡ„и·ідёӯиҒҡеҗҲдәҶжқҘиҮӘйӮ»еұ…иҠӮзӮ№зҡ„дҝЎжҒҜ пјҢ иҝҷзұ»дјјдәҺеңЁзӣёеҗҢзҡ„зҪ‘з»ңеұӮдёӯж„ҹеҸ—йҮҺдёҚеҗҢзҡ„еҚ·з§Ҝж ё гҖӮ
еңЁиҝҷйҮҢ пјҢ дёҺз»Ҹе…ёзҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңдёӯгҖҢInceptionгҖҚжЁЎеқ—зҡ„зұ»жҜ” пјҢ и§ЈйҮҠдәҶжҲ‘们жҸҗеҮәзҡ„и®әж–Үзҡ„еҗҚеӯ— SIGN зҡ„з”ұжқҘ гҖӮ
еҰӮеүҚж–ҮжүҖиҝ° пјҢ дёҠиҝ°зӯүејҸдёӯзҹ©йҳөзҡ„з§Ҝ A?X,вҖҰ, A?X 并дёҚдҫқиө–еҸҜеӯҰд№ зҡ„жЁЎеһӢеҸӮж•° пјҢ еӣ жӯӨеҸҜд»Ҙиў«йў„и®Ўз®— гҖӮ е…·дҪ“иҖҢиЁҖ пјҢ еҜ№дәҺ规模超еӨ§зҡ„еӣҫжқҘиҜҙ пјҢ жҲ‘们еҸҜд»ҘдҪҝз”Ё Apache Spark зӯүеҲҶеёғејҸи®Ўз®—жһ¶жһ„й«ҳж•Ҳең°жү©еұ•иҝҷз§Қйў„и®Ўз®—иҝҮзЁӢ гҖӮ
иҝҷз§ҚеҒҡжі•жңүж•Ҳең°е°Ҷж•ҙдҪ“жЁЎеһӢзҡ„и®Ўз®—еӨҚжқӮеәҰйҷҚдҪҺеҲ°дәҶдёҺеӨҡеұӮж„ҹзҹҘжңәзӣёеҗҢзҡ„ж°ҙе№ідёҠ гҖӮ жӯӨеӨ– пјҢ йҖҡиҝҮе°ҶдҝЎжҒҜдј ж’ӯиҝҮзЁӢиҪ¬з§»еҲ°йў„и®Ўз®—жӯҘйӘӨдёӯ пјҢ жҲ‘们еҸҜд»ҘиҒҡеҗҲжқҘиҮӘжүҖжңүйӮ»еұ…иҠӮзӮ№зҡ„дҝЎжҒҜ пјҢ д»ҺиҖҢйҒҝе…ҚйҮҮж ·иҝҮзЁӢеҸҠе…¶еҸҜиғҪеёҰжқҘзҡ„дҝЎжҒҜжҚҹеӨұдёҺеҒҸзҪ® гҖӮ
жҺЁиҚҗйҳ…иҜ»















![[иЎўе·һйӣҶиҒҡеҢә]гҖҗдёҖзәҝжҲҳвҖңз–«вҖқгҖ‘дёҖдҪҚ80еҗҺдёҡ委дјҡдё»д»»зҡ„йҳІз–«ж•…дәӢ](https://imgcdn.toutiaoyule.com/20200404/20200404084152089853a_t.jpeg)



- KensingtonеҸ‘еёғStudioDock е°ҶiPad Proжү©еұ•еқһдёҺж— зәҝе……з”өеҷЁзӣёз»“еҗҲ
- и…ҫи®ҜдёҺй•ҝдёүи§’G60科еҲӣиө°е»ҠвҖңзүөжүӢвҖқпјҡжү©еұ•з§‘еҲӣвҖңжңӢеҸӢеңҲвҖқжҺЁиҝӣеҹҺеёӮж•°еӯ—еҢ–иҪ¬еһӢ
- еҪұй©°еҸ‘еёғз»Ҹе…ёзүҲRTX 3090/3080пјҡжҡҙеҠӣж¶ЎиҪ®йЈҺжүҮжҲҗдәҶж–°жҪ®
- 欧зүҲGalaxy S21зі»еҲ—е°ҶдёҚж”ҜжҢҒ MicroSD еҚЎжү©еұ•
- AMDдё“еҲ©жі„еҜҶпјҡRDNA3жҳҫеҚЎжҡҙеҠӣе Ҷж ё
- жҲҙе°”WD19TBжү©еұ•еқһ иҪ»и–„еҠһе…¬еҘҪеё®жүӢ
- еӨ–жҺҘеҶ…зҪ®дёҖж ·еҝ«пјҒеёҢжҚ·Xbox Series XеӯҳеӮЁжү©еұ•еҚЎиҜ„жөӢ
- OPPOжӯЈеңЁз ”еҸ‘дёҖж¬ҫеұҸ幕еҸҜеһӮзӣҙжү©еұ•зҡ„жҷәиғҪжүӢжңә
- жө·еӨ–иҝҗиҗҘе•ҶжҡҙеҠӣеұҸи”Ҫе°ҸзұіеҸҢеҚЎеҠҹиғҪпјҢйҒӯеҲ°з”ЁжҲ·иө·иҜү
- WDиҘҝж•°жҺЁеҮәйӣ·з”ө3 SSDжү©еұ•еқһпјҢ2TBеӣәжҖҒ87W PDеҝ«е……