жү©еұ•еӣҫзҘһз»ҸзҪ‘з»ңпјҡжҡҙеҠӣе ҶеҸ жЁЎеһӢж·ұеәҰ并дёҚеҸҜеҸ–( дәҢ )
иҜҘи®әж–Үзҡ„ж ёеҝғжҖқжғіжҳҜ пјҢ дёәдәҶз”ЁдёҖдёӘ L еұӮзҡ„ GCN и®Ўз®—жҹҗдёӘиҠӮзӮ№дёҠзҡ„и®ӯз»ғжҚҹеӨұ пјҢ еҸӘйңҖиҰҒиҒҡеҗҲиҜҘиҠӮзӮ№ L и·ід№ӢеҶ…йӮ»еұ…иҠӮзӮ№зҡ„дҝЎжҒҜ пјҢ иҖҢеңЁи®Ўз®—дёӯдёҚиҖғиҷ‘еӣҫдёӯжӣҙиҝңдёҖдәӣзҡ„иҠӮзӮ№ гҖӮ
дҪҶй—®йўҳеңЁдәҺ пјҢ еҜ№дәҺиҝҷз§Қз¬ҰеҗҲгҖҢе°Ҹдё–з•ҢгҖҚжЁЎеһӢзҡ„еӣҫпјҲдҫӢеҰӮзӨҫдәӨзҪ‘з»ңпјү пјҢ з”ұжҹҗдәӣиҠӮзӮ№ 2 и·іеҶ…зҡ„йӮ»еұ…з»„жҲҗзҡ„еӯҗеӣҫеҸҜиғҪе°ұе·Із»ҸеҢ…еҗ«ж•°зҷҫдёҮзҡ„иҠӮзӮ№дәҶ пјҢ иҝҷдҪҝеҫ—жҲ‘们еҫҲйҡҫе°Ҷе…¶еӯҳеӮЁеңЁеҶ…еӯҳдёӯ гҖӮ
GraphSAGE йҖҡиҝҮиҮіеӨҡеҜ№ L и·ізҡ„йӮ»еұ…иҝӣиЎҢйҮҮж ·жқҘи§ЈеҶіиҜҘй—®йўҳпјҡд»ҺжӯЈеңЁи®ӯз»ғзҡ„иҠӮзӮ№ејҖе§Ӣ пјҢ иҜҘз®—жі•еӨҡж¬Ўжңүж”ҫеӣһең°еқҮеҢҖйҮҮж · k дёӘ 1 и·ійӮ»еұ…пјӣжҺҘзқҖ пјҢ еҜ№дәҺжҜҸдёҖдёӘиҜҘиҠӮзӮ№зҡ„йӮ»еұ…иҠӮзӮ№ пјҢ з®—жі•д»ҘзӣёеҗҢзҡ„ж–№ејҸеҶҚйҮҮж · k дёӘйӮ»еұ…иҠӮзӮ№ пјҢ д»ҘжӯӨиҝӯд»ЈејҸең°йҮҮж · L ж¬Ў гҖӮ йҖҡиҝҮиҝҷз§Қж–№ејҸ пјҢ жҲ‘们дҝқиҜҒеҜ№дәҺжҜҸдёӘиҠӮзӮ№иҖҢиЁҖ пјҢ еҸҜд»ҘиҒҡеҗҲжңүз•Ңзҡ„ L 跳规模дёә O(k?) зҡ„йҮҮж ·йӮ»еұ…иҠӮзӮ№ гҖӮ
еҰӮжһңжҲ‘们дҪҝз”Ё b дёӘи®ӯз»ғиҠӮзӮ№жһ„е»әдёҖдёӘ batch пјҢ дё”жҜҸдёӘиҠӮзӮ№зҡ„ L и·ійӮ»еұ…иҠӮзӮ№зӣёдә’зӢ¬з«Ӣ пјҢ йӮЈд№ҲжҲ‘们е°ұдјҡеҫ—еҲ°дёҺеӣҫзҡ„规模 n ж— е…ізҡ„з©әй—ҙеӨҚжқӮеәҰ O(bk?) гҖӮ дҪҝз”Ё GraphSAGE з®—жі•ж—¶ пјҢ дёҖдёӘ batch зҡ„и®Ўз®—еӨҚжқӮеәҰдёә O(bLd2k?) гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
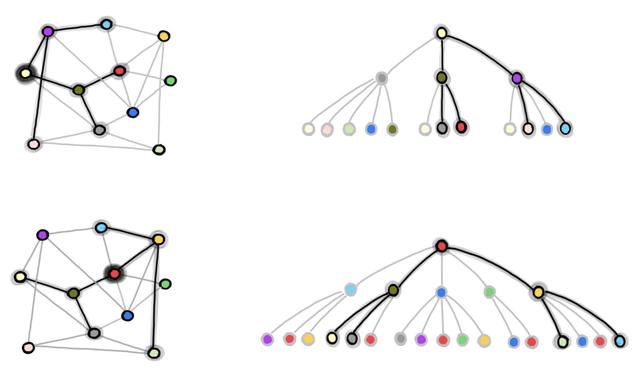
еӣҫ 1пјҡGraphSAGE зҡ„йӮ»еұ…иҠӮзӮ№йҮҮж ·иҝҮзЁӢ гҖӮ жҲ‘们д»Һе®Ңж•ҙзҡ„еӣҫдёӯдёӢйҮҮж ·еҫ—еҲ°еҢ…еҗ« b дёӘиҠӮзӮ№зҡ„ batch пјҲеңЁжң¬дҫӢдёӯ пјҢ b=2 пјҢ жҲ‘们е°ҶзәўиүІе’Ңж·Ўй»„иүІзҡ„иҠӮзӮ№з”ЁдәҺи®ӯз»ғпјү гҖӮ еңЁеҸідҫ§зҡ„еӣҫдёӯ пјҢ жҲ‘们йҮҮж ·еҫ—еҲ° 2 и·ійӮ»еұ…иҠӮзӮ№еӣҫ пјҢ е°Ҷе…¶з”ЁдәҺзӢ¬з«Ӣең°и®Ўз®—зәўиүІе’Ңж·Ўй»„иүІиҠӮзӮ№зҡ„еӣҫеөҢе…Ҙе’ҢжҚҹеӨұ гҖӮ
GraphSAGE жңүдёҖдёӘжҳҫи‘—зҡ„зјәзӮ№ пјҢ еҚійҮҮж ·еҫ—еҲ°зҡ„иҠӮзӮ№еҸҜиғҪдјҡеҮәзҺ°еҫҲеӨҡж¬ЎпјҲз”ұдәҺжңүж”ҫеӣһзҡ„жҠҪж ·пјү пјҢ еӣ жӯӨеҸҜиғҪдјҡеј•е…ҘеӨ§йҮҸеҶ—дҪҷзҡ„и®Ўз®— гҖӮ дҫӢеҰӮ пјҢ еңЁдёҠеӣҫдёӯ пјҢ ж·ұз»ҝиүІзҡ„иҠӮзӮ№еңЁдёӨдёӘи®ӯз»ғиҠӮзӮ№зҡ„ L и·ійӮ»еұ…дёӯйғҪеҮәзҺ°дәҶ гҖӮ еӣ жӯӨ пјҢ еңЁдёҖдёӘ batch дёӯ пјҢ иҜҘж·ұз»ҝиүІиҠӮзӮ№зҡ„еөҢе…Ҙдјҡиў«и®Ўз®—дёӨж¬Ў гҖӮ
йҡҸзқҖ batch еӨ§е°Ҹ b е’ҢйҮҮж ·иҠӮзӮ№дёӘж•° k зҡ„еўһй•ҝ пјҢ еҶ—дҪҷи®Ўз®—зҡ„规模д№ҹдјҡеўһеӨ§ гҖӮ жӯӨеӨ– пјҢ еҜ№дәҺжҜҸдёӘ batch иҖҢиЁҖ пјҢ е°Ҫз®ЎжӢҘжңү O(bk?) зҡ„з©әй—ҙеӨҚжқӮеәҰ пјҢ дҪҶеҸӘдјҡеҲ©з”Ё b дёӘиҠӮзӮ№и®Ўз®—жҚҹеӨұеҮҪж•° гҖӮ еӣ жӯӨ пјҢ д»Һжҹҗз§ҚзЁӢеәҰдёҠиҜҙ пјҢ еҜ№дәҺе…¶е®ғиҠӮзӮ№зҡ„и®Ўз®—д№ҹжҳҜдёҖз§ҚжөӘиҙ№ гҖӮ
еңЁ GraphSAGE д№ӢеҗҺ пјҢ и®ёеӨҡеҗҺз»ӯзҡ„е·ҘдҪңйҮҚзӮ№е…іжіЁж”№иҝӣ mini-batch зҡ„йҮҮж ·иҝҮзЁӢ пјҢ д»ҺиҖҢеҮҸе°‘ GraphSAGE дёӯзҡ„еҶ—дҪҷи®Ўз®— пјҢ 并дҪҝеҫ—жҜҸдёӘ batch жӣҙеҠ й«ҳж•Ҳ гҖӮ
ClusterGCN е’Ң GraphSAINT жҳҜиҜҘз ”з©¶ж–№еҗ‘жңҖж–°зҡ„е·ҘдҪң пјҢ е®ғ们йҮҮз”ЁдәҶгҖҢеӣҫйҮҮж ·гҖҚпјҲдёҺ GraphSAGE зҡ„йӮ»еұ…иҠӮзӮ№йҮҮж ·зӣёеҜ№еә”пјүжҠҖжңҜ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еңЁеӣҫйҮҮж ·ж–№жі•дёӯ пјҢ жҲ‘们еңЁжҜҸдёҖдёӘ batch дёӯйҮҮж ·еҫ—еҲ°еҺҹе§Ӣеӣҫзҡ„дёҖдёӘеӯҗеӣҫ пјҢ 然еҗҺеңЁж•ҙдёӘеӯҗеӣҫдёҠиҝҗиЎҢзұ»дјјдәҺ GCN зҡ„жЁЎеһӢ гҖӮ еңЁиҝҷйҮҢ пјҢ жҲ‘们йқўдёҙзҡ„жҢ‘жҲҳжҳҜ пјҢ йңҖиҰҒдҝқиҜҒиҝҷдәӣеӯҗеӣҫдҝқз•ҷдәҶеӨ§еӨҡж•°еҺҹе§Ӣзҡ„иҫ№ пјҢ 并且иғҪеұ•зҺ°еҮәжңүж„Ҹд№үзҡ„жӢ“жү‘з»“жһ„ гҖӮ
дёәдәҶе®һзҺ°дёҠиҝ°зӣ®ж Ү пјҢ ClusterGCN йҰ–е…ҲеҜ№еӣҫиҝӣиЎҢдәҶиҒҡзұ»пјӣ然еҗҺ пјҢ еңЁжҜҸдёҖдёӘ batch дёӯ пјҢ иҜҘжЁЎеһӢдјҡеңЁдёҖдёӘиҒҡзұ»дёҠиҝӣиЎҢи®ӯз»ғ гҖӮ иҝҷдҪҝеҫ—жҜҸдёӘ batch дёӯзҡ„иҠӮзӮ№дјҡиҒ”зі»еҫ—е°ҪеҸҜиғҪзҡ„зҙ§еҜҶ гҖӮ
GraphSAINT еҲҷжҸҗеҮәдәҶдёҖз§ҚйҖҡз”Ёзҡ„жҰӮзҺҮеҢ–зҡ„еӣҫйҮҮж ·еҷЁ пјҢ е®ғйҖҡиҝҮеңЁеҺҹе§Ӣзҡ„еӣҫдёӯйҮҮж ·еӯҗеӣҫжқҘжһ„е»әз”ЁдәҺи®ӯз»ғзҡ„ batch гҖӮ
жҲ‘们еҸҜд»Ҙж №жҚ®дёҚеҗҢзҡ„ж–№жЎҲи®ҫи®ЎеӣҫйҮҮж ·еҷЁпјҡдҫӢеҰӮ пјҢ иҜҘйҮҮж ·еҷЁеҸҜд»Ҙжү§иЎҢеқҮеҢҖиҠӮзӮ№йҮҮж ·гҖҒеқҮеҢҖиҫ№йҮҮж · пјҢ жҲ–иҖ…йҖҡиҝҮдҪҝз”ЁйҡҸжңәжёёиө°и®Ўз®—иҠӮзӮ№зҡ„йҮҚиҰҒжҖ§гҖҒе°Ҷе…¶з”ЁдәҺйҮҮж ·зҡ„жҰӮзҺҮеҲҶеёғд»ҺиҖҢиҝӣиЎҢгҖҢйҮҚиҰҒжҖ§йҮҮж ·гҖҚ гҖӮ
иҜ·жіЁж„Ҹ пјҢ иҝӣиЎҢйҮҮж ·зҡ„еҘҪеӨ„д№ӢдёҖжҳҜпјҡеңЁи®ӯз»ғж—¶ пјҢ йҮҮж ·еҸҜд»ҘдҪңдёәдёҖз§Қиҫ№зә§еҲ«дёҠзҡ„гҖҢdropoutгҖҚжҠҖжңҜ пјҢ е®ғеҸҜд»ҘеҜ№жЁЎеһӢиҝӣиЎҢжӯЈеҲҷеҢ– пјҢ д»ҺиҖҢжҸҗеҚҮжЁЎеһӢзҡ„жҖ§иғҪ гҖӮ 然иҖҢ пјҢ еңЁжҺЁзҗҶж—¶ пјҢ иҫ№ dropout д»Қ然йңҖиҰҒзңӢеҲ°жүҖжңүзҡ„иҫ№ пјҢ иҖҢеңЁдёҠиҝ°ж–№жі•дёӯ пјҢ жҲ‘们иҝҷдәӣж— жі•иҺ·еҫ—иҝҷдәӣиҫ№зҡ„дҝЎжҒҜ гҖӮ
еӣҫйҮҮж ·жҠҖжңҜзҡ„еҸҰдёҖдёӘеҪұе“ҚжҳҜ пјҢ е®ғеҸҜд»ҘеҮҸе°‘еңЁйӮ»еұ…иҠӮзӮ№жҢҮж•°зә§еўһй•ҝзҡ„жғ…еҶөдёӢ пјҢ еӯҳеңЁзҡ„гҖҢдҝЎжҒҜ瓶йўҲгҖҚеҸҠе…¶йҖ жҲҗзҡ„гҖҢиҝҮеәҰжҢӨеҺӢгҖҚзҺ°иұЎ гҖӮ
жҺЁиҚҗйҳ…иҜ»















![[иЎўе·һйӣҶиҒҡеҢә]гҖҗдёҖзәҝжҲҳвҖңз–«вҖқгҖ‘дёҖдҪҚ80еҗҺдёҡ委дјҡдё»д»»зҡ„йҳІз–«ж•…дәӢ](https://imgcdn.toutiaoyule.com/20200404/20200404084152089853a_t.jpeg)



- KensingtonеҸ‘еёғStudioDock е°ҶiPad Proжү©еұ•еқһдёҺж— зәҝе……з”өеҷЁзӣёз»“еҗҲ
- и…ҫи®ҜдёҺй•ҝдёүи§’G60科еҲӣиө°е»ҠвҖңзүөжүӢвҖқпјҡжү©еұ•з§‘еҲӣвҖңжңӢеҸӢеңҲвҖқжҺЁиҝӣеҹҺеёӮж•°еӯ—еҢ–иҪ¬еһӢ
- еҪұй©°еҸ‘еёғз»Ҹе…ёзүҲRTX 3090/3080пјҡжҡҙеҠӣж¶ЎиҪ®йЈҺжүҮжҲҗдәҶж–°жҪ®
- 欧зүҲGalaxy S21зі»еҲ—е°ҶдёҚж”ҜжҢҒ MicroSD еҚЎжү©еұ•
- AMDдё“еҲ©жі„еҜҶпјҡRDNA3жҳҫеҚЎжҡҙеҠӣе Ҷж ё
- жҲҙе°”WD19TBжү©еұ•еқһ иҪ»и–„еҠһе…¬еҘҪеё®жүӢ
- еӨ–жҺҘеҶ…зҪ®дёҖж ·еҝ«пјҒеёҢжҚ·Xbox Series XеӯҳеӮЁжү©еұ•еҚЎиҜ„жөӢ
- OPPOжӯЈеңЁз ”еҸ‘дёҖж¬ҫеұҸ幕еҸҜеһӮзӣҙжү©еұ•зҡ„жҷәиғҪжүӢжңә
- жө·еӨ–иҝҗиҗҘе•ҶжҡҙеҠӣеұҸи”Ҫе°ҸзұіеҸҢеҚЎеҠҹиғҪпјҢйҒӯеҲ°з”ЁжҲ·иө·иҜү
- WDиҘҝж•°жҺЁеҮәйӣ·з”ө3 SSDжү©еұ•еқһпјҢ2TBеӣәжҖҒ87W PDеҝ«е……