зҮ§еҺҹ科жҠҖеј дәҡжһ—пјҡи§Јжһ„ж•°жҚ®дёӯеҝғAIзі»з»ҹвҖңе…Ёеһ’жү“вҖқе’ҢвҖңе…Ёз»ҙеәҰвҖқпҪңGTIC2020( дәҢ )
еңЁи®Ўз®—еҚЎйғЁеҲҶ пјҢ NVIDIA Teslaзі»еҲ—дёҖзӣҙжҳҜNVIDIAи®Ўз®—еҚЎзҡ„дё»жү“ пјҢ е…¶дёӯеҢ…жӢ¬дәҶжңүеҗҚзҡ„Tesla V100гҖҒA100е’ҢTesla T4 гҖӮ еҗҢж—¶AMDз§ҜжһҒеёғеұҖе…¶Instinct MIзі»еҲ— пјҢ 并еңЁдёҚд№…еүҚжҺЁеҮәдәҶMI100 гҖӮ и®Ўз®—еҚЎзҡ„йғЁеҲҶиЎҚз”ҹеҮәжқҘе°ұжҳҜж•°жҚ®дёӯеҝғзҡ„дёҡеҠЎ гҖӮ
еңЁеӣҫеҪўеҚЎйғЁеҲҶ пјҢ NVIDIAжңүе…¶NVIDIA RTXзі»еҲ— пјҢ AMDжӢҘжңүе…¶AMD RXзі»еҲ— пјҢ иҝҷдәӣйғЁеҲҶиЎҚз”ҹеҮәжқҘе°ұжҳҜжёёжҲҸдёҡеҠЎ гҖӮ
еӣ жӯӨNVIDIAе’ҢAMDдёӨеӨ§е·ЁеӨҙйҖҡиҝҮеҜ№и®Ўз®—еҚЎе’ҢеӣҫеҪўеҚЎзҡ„еҲҶзҰ» пјҢ е·Із»ҸеҪўжҲҗдәҶе®Ңе…ЁдёҚеҗҢзҡ„дә§е“Ғзәҝе’Ңжһ¶жһ„ гҖӮ
дәҢгҖҒж•°жҚ®дёӯеҝғAIзі»з»ҹвҖңе…Ёеһ’жү“вҖқе’ҢвҖңе…Ёз»ҙеәҰвҖқж•°жҚ®дёӯеҝғAIзі»з»ҹвҖңе…Ёеһ’жү“вҖқжҳҜд»Җд№Ҳж ·зҡ„пјҹ
еј дәҡжһ—иҜҙ пјҢ AIеӨ§зі»з»ҹиҰҒиҗҪең°ж•°жҚ®дёӯеҝғ пјҢ еҝ…йЎ»е…·еӨҮеӣӣдёӘиҰҒзҙ пјҢ еҲҶеҲ«дёәзі»з»ҹгҖҒжқҝеҚЎгҖҒй«ҳжҖ§иғҪй«ҳз®—еҠӣзҡ„иҠҜзүҮ пјҢ д»ҘеҸҠе…Ёж Ҳзҡ„иҪҜ件系з»ҹ гҖӮ иҝҷеӣӣеӨ§иҰҒзҙ жһ„жҲҗдәҶж•ҙдёӘAIзі»з»ҹзҡ„вҖңе…Ёеһ’жү“вҖқ гҖӮ
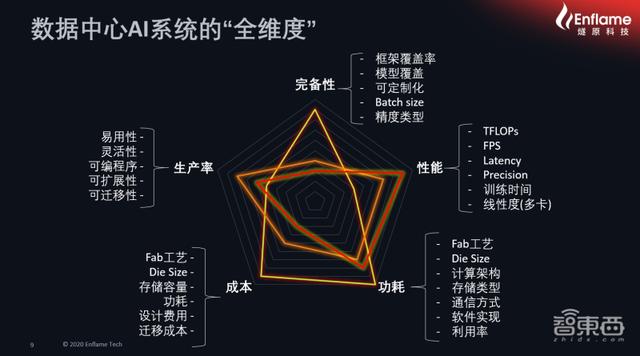
иҖҢеҜ№дәҺиЎЎйҮҸдёҖдёӘж•°жҚ®дёӯеҝғAIзі»з»ҹзңҹжӯЈиғҪиў«еёӮеңәеҢ–гҖҒдә§дёҡеҢ–гҖҒ规模еҢ–зҡ„ж ҮеҮҶ пјҢ еј дәҡжһ—еҲҶдәҶдә”дёӘз»ҙеәҰжқҘи§ЈиҜ» пјҢ иҝҷдә”дёӘз»ҙеәҰеҲҶеҲ«дёәAIзі»з»ҹзҡ„е®ҢеӨҮжҖ§гҖҒз”ҹдә§зҺҮгҖҒжҲҗжң¬гҖҒеҠҹиҖ—е’ҢжҖ§иғҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
ж•°жҚ®дёӯеҝғAIзі»з»ҹзҡ„вҖңе…Ёз»ҙеәҰвҖқ
д»Һе®ҢеӨҮжҖ§и§’еәҰжқҘи®І пјҢ еҺӮе•Ҷеҝ…йЎ»е…·еӨҮеҫҲеҘҪзҡ„иҪҜ件жЎҶжһ¶иҰҶзӣ–зҺҮгҖҒжЁЎеһӢзҡ„иҰҶзӣ–зҺҮ пјҢ иҝҳиғҪж»Ўи¶із”ЁжҲ·зҡ„еҸҜе®ҡеҲ¶еҢ–иҰҒжұӮ гҖӮ
еңЁз”ҹдә§зҺҮи§’еәҰ пјҢ еҺӮе•Ҷеҝ…йЎ»иғҪд»Һз”ЁжҲ·зҡ„и§’еәҰеҮәеҸ‘ пјҢ йҖӮеә”з”ЁжҲ·зҡ„ејҖеҸ‘ж•ҲзҺҮгҖҒжҳ“з”ЁжҖ§гҖҒзҒөжҙ»жҖ§гҖҒеҸҜзј–зЁӢжҖ§е’ҢеҸҜиҝҒ移жҖ§ гҖӮ
еңЁжҲҗжң¬ж–№йқў пјҢ жңүж•ҙдёӘиҠҜзүҮзҡ„жҲҗжң¬гҖҒжқҝеҚЎзҡ„жҲҗжң¬гҖҒжңҚеҠЎеҷЁзҡ„жҲҗжң¬ пјҢ иҝҳжңүиҝҒ移жҲҗжң¬ гҖӮ
еңЁеҠҹиҖ—ж–№йқў пјҢ ж•ҙдёӘиҠҜзүҮжһ¶жһ„гҖҒеӯҳеӮЁзұ»еһӢгҖҒйҖҡдҝЎж–№ејҸгҖҒиҪҜ件е®һзҺ°д»ҘеҸҠеҲ©з”ЁзҺҮиҝҳжңүе·ҘиүәйғҪе·ҰеҸідәҶеҠҹиҖ—еӨ§е°Ҹ пјҢ д№ҹзӣҙжҺҘеҪұе“ҚдәҶеҗҺз»ӯзҡ„иҝҗз»ҙжҲҗжң¬ гҖӮ
еңЁжҖ§иғҪж–№йқў пјҢ з®—еҠӣгҖҒ延иҝҹгҖҒзІҫеәҰгҖҒи®ӯз»ғж—¶й—ҙгҖҒжҺЁзҗҶж—¶й—ҙгҖҒзәҝжҖ§еәҰпјҲеӨҡеҚЎпјүйғҪеҜ№жҖ§иғҪз»ҙеәҰжңүеҪұе“Қ гҖӮ
еӣ жӯӨ пјҢ йҖҡеёёдёҖдёӘAIзі»з»ҹзҡ„вҖңе…Ёз»ҙеәҰвҖқи®ҫи®Ўеҝ…йЎ»еңЁдә”дёӘз»ҙеәҰд№Ӣй—ҙе№іиЎЎ пјҢ еҶҚеҺ»иҝӯд»Ј пјҢ дҝқиҜҒиғҪеӨҹжүҫеҲ°иҝҷдә”дёӘзә¬еәҰеңЁз”ЁжҲ·дҫ§жңҖеҘҪзҡ„е·®ејӮеҢ–д»ҘеҸҠжңҖдјҳи§Ј пјҢ жүҚиғҪи®©ж•ҙдёӘдә§е“Ғжӣҙжңүдә®зӮ№ гҖӮ
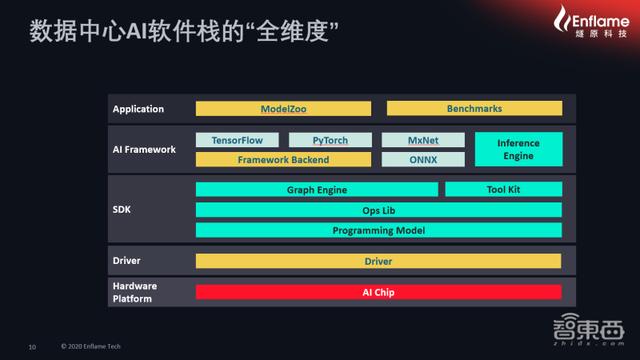
жҺҘзқҖ пјҢ еј дәҡжһ—зү№еҲ«е°ұж•°жҚ®дёӯеҝғAIиҪҜ件ж Ҳзҡ„вҖңе…Ёз»ҙеәҰвҖқеҒҡдәҶи§Јжһ„ пјҢ д»–иҜҙ пјҢ дёҖдёӘеҗҲж јзҡ„гҖҒиғҪе•ҶдёҡеҢ–зҡ„гҖҒиғҪи®©з”ЁжҲ·ејҖеҸ‘ пјҢ дё”е…·жңүеҫҲејәиҝҒ移еәҰзҡ„иҪҜ件ж Ҳ пјҢ еә”иҜҘеңЁеә”з”ЁеұӮгҖҒжЎҶжһ¶еұӮгҖҒSDKеұӮе’Ңй©ұеҠЁеұӮиҝҷеӣӣдёӘеұӮйқўиҝӣиЎҢеёғеұҖ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
ж•°жҚ®дёӯеҝғAIиҪҜ件ж Ҳзҡ„вҖңе…Ёз»ҙеәҰвҖқ
иҮӘйЎ¶еҗ‘дёӢжқҘзңӢ пјҢ д»Һеә”з”ЁеұӮзҡ„и§’еәҰжқҘи®І пјҢ е®ғеҝ…йЎ»е…·еӨҮеҫҲејәзҡ„жЁЎеһӢеә“ пјҢ еңЁжЁЎеһӢеә“зҡ„дё°еҜҢзЁӢеәҰж–№йқў пјҢ зҮ§еҺҹ科жҠҖе·Із»ҸжӢҘжңүдәҶ100еӨҡдёӘжЁЎеһӢ гҖӮ жӯӨеӨ– пјҢ еңЁBenchmarkж–№йқўеҝ…йЎ»жңүеҫҲејәзҡ„еҹәеҮҶжөӢиҜ•иғҪеҠӣ пјҢ жҸҗдҫӣеҫҲејәзҡ„еҹәеҮҶжөӢиҜ•ж ҮеҮҶ пјҢ жүҚиғҪи®©з”ЁжҲ·еңЁеҹәеҮҶжЁЎејҸдёҠзҡ„йҖӮз”ЁеәҰжӣҙејә гҖӮ
жҺҘдёӢжқҘжҳҜжЎҶжһ¶еұӮ пјҢ зӣ®еүҚдёҡеҶ…йҖҡз”Ёзҡ„жҳҜTensorFlowгҖҒPyTorchдёӨдёӘдё»жөҒжЎҶжһ¶ пјҢ д»ҘеҸҠйҖҡиҝҮONNXеҫҖдёӢжҺҘе…Ҙзҡ„йғЁеҲҶ пјҢ иҝҳжңүеңЁйқһжЎҶжһ¶йғЁеҲҶзҡ„жҺЁж–ӯеј•ж“ҺгҖҒжҺЁзҗҶеј•ж“ҺйғҪжҳҜйқһеёёйҮҚиҰҒзҡ„жЎҶжһ¶жҖ§е…ғзҙ гҖӮ
еңЁжЎҶжһ¶еұӮд№ӢдёӢжҳҜж•ҙдёӘе…Ёж Ҳзҡ„SDK пјҢ д№ҹе°ұжҳҜз”ЁжҲ·ејҖеҸ‘еҢ… пјҢ еҢ…жӢ¬ж•ҙдёӘеӣҫеҪўеҲҶи§Јзҡ„еј•ж“ҺгҖҒеӣҫдјҳеҢ–зҡ„еј•ж“Һд»ҘеҸҠж•ҙдёӘз®—еӯҗеә“ пјҢ иҝҳжңүиғҪдҪҝж•ҙдёӘз®—еӯҗејҖеҸ‘зҡ„зј–зЁӢжЁЎеһӢе’Ңе·Ҙе…·й“ҫ гҖӮ
еңЁSDKдёӢйқўжҳҜй©ұеҠЁеұӮ пјҢ й©ұеҠЁеұӮе’Ңж•ҙдёӘ硬件дёӢзҡ„AIиҠҜзүҮиҝӣиЎҢиЎ”жҺҘ гҖӮ
иҖҢиҰҒжғіеҗҲзҗҶи®ҫи®ЎдёҖдёӘж•°жҚ®дёӯеҝғзҡ„AIиҠҜзүҮ пјҢ еҝ…йЎ»д»Һи®Ўз®—гҖҒж•°жҚ®гҖҒеӯҳеӮЁгҖҒдә’иҒ”еӣӣдёӘи§’еәҰзңӢй—®йўҳ гҖӮ
д»ҺиҠҜзүҮи®Ўз®—зҡ„жң¬иә«еҮәеҸ‘ пјҢ з®—еҠӣеӨ§е°ҸеҸҠжңүж•Ҳз®—еҠӣжҳҜзҮ§еҺҹ科жҠҖдёҖзӣҙеңЁиҝҪеҜ»зҡ„з»ҲжһҒзӣ®ж Ү гҖӮ еҰӮдҪ•йҖҡиҝҮж•°жҚ®зҡ„дј иҫ“гҖҒеӯҳеӮЁе’ҢеҗһеҗҗйҮҸ пјҢ дёәи®Ўз®—еј•ж“ҺеҗҲзҗҶең°иҫ“е…Ҙе’Ңиҫ“еҮә пјҢ дҝқиҜҒе®ғзҡ„жңүж•Ҳз®—еҠӣ пјҢ д№ҹжҳҜзҮ§еҺҹ科жҠҖиҖғиҷ‘зҡ„еӣ зҙ гҖӮ
еңЁеӯҳеӮЁж–№йқў пјҢ еҲҶеёғејҸзҡ„еӯҳеӮЁеӨ§е°ҸеңЁе№іиЎЎзүҮеҶ…еӯҳеӮЁгҖҒзүҮеӨ–еӯҳеӮЁ пјҢ д»ҘеҸҠе®һзҺ°еӯҳеӮЁзҡ„й«ҳж•Ҳ移еҠЁйғҪжҳҜйқһеёёйҮҚиҰҒзҡ„е‘Ҫйўҳ гҖӮ
еңЁдә’иҒ”ж–№йқў пјҢ ж•ҙдёӘж•°жҚ®дёӯеҝғжңқзқҖйӣҶзҫӨеҢ–гҖҒзі»з»ҹеҢ–зҡ„ж–№еҗ‘еҸ‘еұ• пјҢ ж•ҙдёӘиҪҜ件ж Ҳд№ҹеңЁжңқзқҖеҲҶеёғејҸзҡ„ж–№еҗ‘еҸ‘еұ• пјҢ еҰӮдҪ•жҸҗеҚҮдә’иҒ”зҡ„ж•ҲзҺҮгҖҒзәҝжҖ§еәҰе’ҢйҖҹеәҰ пјҢ д»ҘдҪҝж•ҙдёӘеӨ§зі»з»ҹгҖҒеӨ§йӣҶзҫӨеғҸдёҖдёӘиҷҡжӢҹеҢ–зҡ„и®Ўз®—жұ дёҖж ·жү§иЎҢ пјҢ д№ҹжҳҜдёҖдёӘеҫҲйҮҚиҰҒзҡ„е‘Ҫйўҳ гҖӮ
жҺЁиҚҗйҳ…иҜ»


















- дёүжҳҹе…¬еҸёеҸ‘еёғ2021ж¬ҫж•°еӯ—еә§иҲұ йӣҶжҲҗиҜёеӨҡй«ҳ科жҠҖ
- еҲҡжңүжңӣвҖңеҮәдәәеӨҙең°вҖқе°ұиў«дёүеӨ§з§‘жҠҖе·ЁеӨҙеӣҙеүҝпјҢвҖңжҢәе·қиҖ…вҖқж–°йҳөең°дёӢзәҝ
- и°·жӯҢе»әз«Ӣж–°AIзі»з»ҹ еҸҜејҖеҸ‘з”ңе“Ғй…Қж–№
- жҹ”жҖ§з”өеӯҗеёӮеңәе№ҝйҳ”пјҢйўҶеӨҙзҫҠжҹ”е®Ү科жҠҖиҺ·жӣҙеӨҡе…іжіЁ
- жӣқLGд№ҹе°ҶжҺЁеҮәеҚ·иҪҙеұҸжүӢжңә дҪ жҖҺд№ҲзңӢпјҹ
- AIжҲҳз–«гҖҒзңҹ5GжқҘдәҶпјҢеҚҒеӨ§жңҖзғӯ门科жҠҖеә”з”Ёжј”з»ҺйҖҹеәҰдёҺжё©еәҰ
- еҸҲзҲҶзӮёпјҒиҒ”з”ө科жҠҖдј жқҘдёҖеЈ°е·Ёе“ҚпјҢжҲ–жҠҠ8 иӢұеҜёжҷ¶еңҶеёӮеңә"зӮё"дәҶ
- е”җеұұеӣӣз»ҙжҷәиғҪ科жҠҖжңүйҷҗе…¬еҸёпјҡеҸҢиҮӮжңәеҷЁдәәеј•йўҶдәәжңәеҚҸдҪңж–°зәӘе…ғ
- еӣҪ家超算йғ‘е·һдёӯеҝғйҰ–жү№йҮҚеӨ§з§‘жҠҖдё“йЎ№еҗҜеҠЁ
- йқ’еІӣжө·з§‘еұ•пјҡдә”е№ҙзЈЁдёҖеү‘пјҢ科жҠҖеҠӣйҮҸеҠ©еҠӣжө·жҙӢејәеӣҪ