Pandas的crosstab函数( 四 )
 文章插图
文章插图
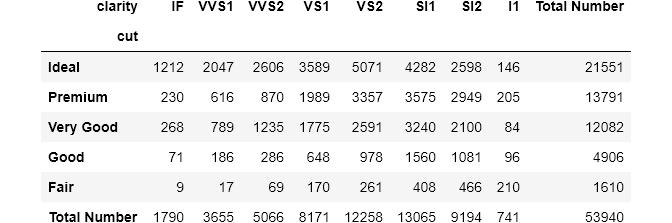
右下角的单元格将始终包含观察的总数 , 或者如果“normalize”设置为True , 则为1:
pd.crosstab(index=diamonds['cut'],columns=diamonds['clarity'],margins=True,margins_name='Total Percentage',normalize=True)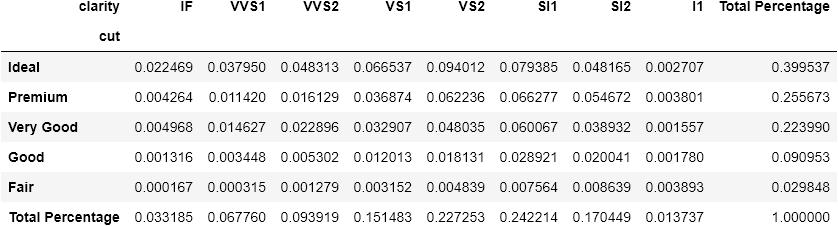 文章插图
文章插图
请注意 , 如果将margins设置为True , 则热图是无用的 。
Pandas crosstab() , 多组对于index和columns参数 , 可以传递多个变量 。 结果将是一个具有多级索引的数据帧 。 这次我们插入所有的分类变量:
pd.crosstab(index=[diamonds['cut'], diamonds['clarity']],columns=diamonds['color'])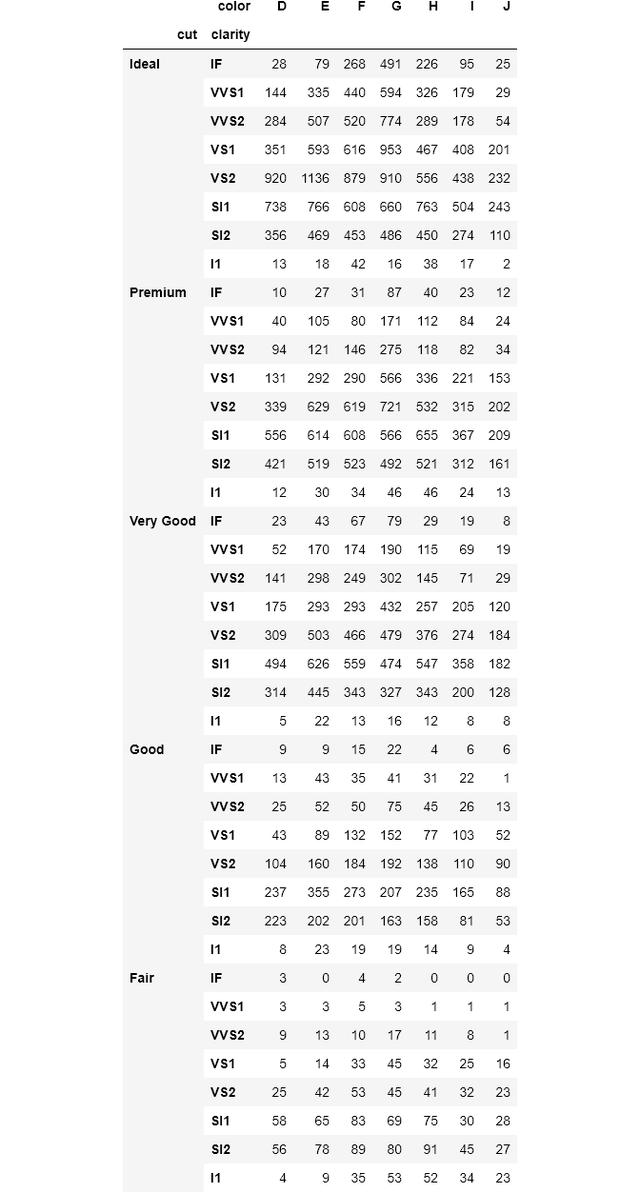 文章插图
文章插图
对于index , 我传递了color和cut 。 如果我把它们传递给列 , 结果将是一个包含40列的数据帧 。 如果你注意的话 , 多级索引如预期的那样命名为cut和clear 。 对于存在多级索引或列名的情况 , crosstab()有方便的参数来更改它们的名称:
pd.crosstab(index=[diamonds['cut'], diamonds['clarity']],columns=diamonds['color'],rownames=['Diamond Cut', 'Clarity']).head()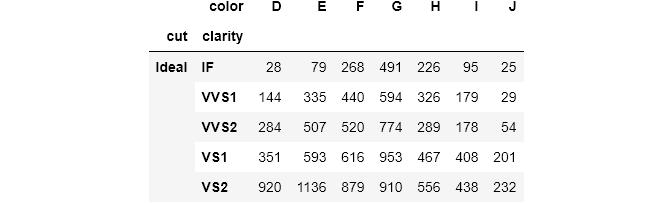 文章插图
文章插图
传递相应名称的列表 , 以将索引名称更改为行名称 。 这个过程对于控制列名的colnames是相同的 。
有一件事让我很惊讶 , 如果你把多个函数传递给aggfunc , pandas就会抛出一个错误 。 同样 , StackOverflow上的伙计们认为这是一个bug , 而且已经有6年多没有解决过了 。
最后要注意的是 , 在pivot_table()和crosstab()中 , 都有一个dropna参数 , 如果设置为True , 则会删除包含所有nan的列或行 。
推荐阅读









![[德斯]82284.6欧元起售 新款梅赛德斯-AMG E级开启预定](https://k-static.6789.com/uploads/auto-pic/202007/07/1594089939_69902300.jpg)










- 不常见的Pandas小窍门:我打赌一定有你不知道的
- countif函数的四种另类经典用法,我不说没人告诉你
- Pandas的SettingWithCopyWarning
- 让人头痛的Generator 函数的异步应用真的有用吗?
- PowerQuery 表达式计算函中调用其他函数的方法
- Python中文速查表-Pandas 基础
- Pandas教程
- 函数逸闻之大小写
- Java函数式编码结构-好程序员
- Python数据处理,pandas 统计连续停车时长