Pandas的crosstab函数
介绍我很喜欢DataCamp上的“Seaborn中间数据可视化”(Intermediate Data Visualization with Seaborn)这个课程 。 它教给新手非常棒的图表和方法 。 但说到热图 , 课程的老师不知怎么地引入了一个全新的pandas函数crosstab 。 然后 , 很快说:“crosstab是一个计算交叉表的有用函数…”
我就在那里不理解了 。 显然 , 我的第一反应是查看函数的文档 。 我刚开始觉得我可以处理Matplotlib的任何文档 , 但是…我错了 。 .
在本文的最后一部分中 , 我讨论了为什么有些课程不教你像crosstab这样的高级函数 。 因为如果不在具体的环境下很难使用这样的函数 , 同时又保持示例的初学者级别 。
此外 , 大多数课程使用小型或玩具数据集 。 在更复杂的数据科学环境中 , 这些复杂函数的好处更为明显 , 并且经常被更有经验的pandas用户使用 。
在这篇文章中 , 我将教你如何使用crosstab以及如何在其他类似函数中选择它 。
目录
- 简介
- 设置
- crosstab基础知识
- Pandas crosstab()与pivot_table()和groupby()的比较
- Pandas crosstab()的进一步定制
- Pandas crosstab() , 多个组
# 导入必要的库import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport numpy as np# 忽略警告import warningswarnings.filterwarnings('ignore')# 启用多单元输出from IPython.core.interactiveshell import InteractiveShellInteractiveShell.ast_node_interactivity = 'all'对于示例数据 , 我将使用Seaborn内置的diamonds数据集 。 它足够大 , 并且有一些可以用crosstab()的变量:diamonds = sns.load_dataset('diamonds')diamonds.head()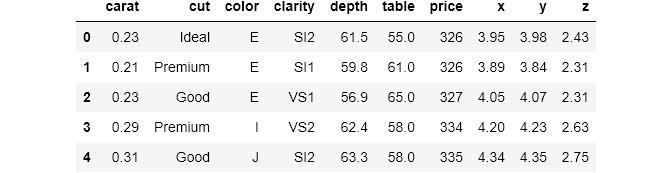 文章插图
文章插图crosstab()基础知识【Pandas的crosstab函数】与许多计算分组汇总统计信息的函数一样 , crosstab()可以处理分类数据 。 它可用于将两个或多个变量分组 , 并为每组的给定值执行计算 。 当然 , 使用groupby()或pivot_table()可以执行此类操作 , 但正如我们稍后将要看到的 , crosstab()为你的日常工作流程带来了许多好处 。
函数接受两个或多个列表、pandas series 或dataframe , 默认情况下返回每个组合的频率 。 我总是喜欢从一个例子开始 , 这样你可以更好地理解定义 , 然后我将继续解释语法 。
crosstab()总是返回一个数据帧 , 下面是一个例子 。 dataframe是diamonds中两个变量的交叉表:cut和color 。 交叉表表示取一个变量 , 将其组显示为index , 取另一个变量 , 将其组显示为columns 。
pd.crosstab(index=diamonds['cut'], columns=diamonds['color'])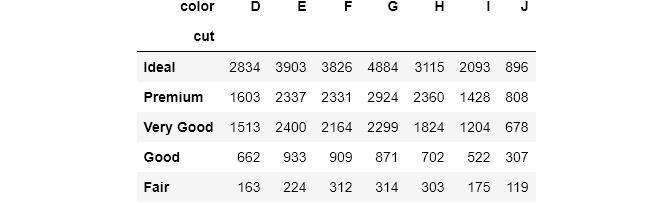 文章插图
文章插图语法相当简单 。 index用于对变量进行分组 , 并将其显示为index(行) , 对于列也是如此 。 如果没有给定聚合函数 , 则每个单元格将计算每个组合中的观察数 。 例如 , 左上角的单元格告诉我们 , 有2834颗颜色代码为D而且是理想切割的钻石 ,。
接下来 , 我们要查看每个组合的平均价格 。 crosstab()提供values参数来引入第三个要聚合的数值变量:
pd.crosstab(index=diamonds['cut'],columns=diamonds['color'],values=diamonds['price'],aggfunc=np.mean).round(0)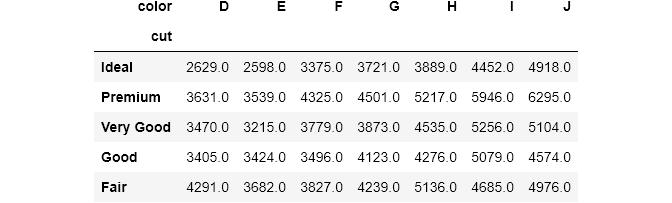 文章插图
文章插图现在 , 每个单元格包含了cut和color组合的平均价格 。 为了说明我们要计算平均价格 , 我们将price列传递给values 。 请注意 , 始终必须同时使用values和aggfunc 。 否则 , 你将得到一个错误 。 我还使用round()将答案四舍五入 。
推荐阅读

















- 不常见的Pandas小窍门:我打赌一定有你不知道的
- countif函数的四种另类经典用法,我不说没人告诉你
- Pandas的SettingWithCopyWarning
- 让人头痛的Generator 函数的异步应用真的有用吗?
- PowerQuery 表达式计算函中调用其他函数的方法
- Python中文速查表-Pandas 基础
- Pandas教程
- 函数逸闻之大小写
- Java函数式编码结构-好程序员
- Python数据处理,pandas 统计连续停车时长