Pythonж•°жҚ®еӨ„зҗҶпјҢpandas з»ҹи®Ўиҝһз»ӯеҒңиҪҰж—¶й•ҝ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е®ҡжңҹжүҫдәӣз®ҖеҚ•з»ғд№ дҪңдёә pandas дё“ж Ҹзҡ„з»ғд№ йўҳ
зҹҘиҜҶзӮ№
- DataFrame.apply д»ҘеҸҠ axis зҡ„зҗҶи§Ј
- еҲҶз»„и®Ўж•°
- DataFrame.iloc еҲҮзүҮ
 ж–Үз« жҸ’еӣҫ
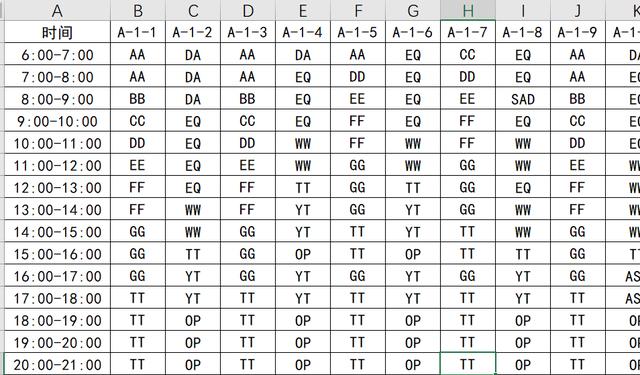
ж–Үз« жҸ’еӣҫ- жҜҸиЎҢиЎЁзӨәжҹҗж—¶й—ҙж®ө(жҖ»жҳҜ1дёӘе°Ҹж—¶)жҜҸдёӘеҒңиҪҰдҪҚеҒңж”ҫжҳҜйӮЈиҫҶиҪҰ(еҶ…е®№и§ҶдёәиҪҰзүҢеҗ§)
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫе…ұ2дёӘйңҖжұӮпјҡ
йңҖжұӮ1пјҡеҒңиҪҰж¬Ўж•°(и“қиүІиЎҢ)пјҡдёҖеӨ©дёӯ пјҢ жҜҸдёӘеҒңиҪҰдҪҚеҲҶеҲ«жңүеӨҡе°‘дёҚеҗҢзҡ„иҪҰеҒңж”ҫ пјҢ еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ- еҲҶеҲ«жңү8иҫҶдёҚеҗҢиҪҰзүҢ пјҢ еӣ жӯӨиҝҷдёӘеҒңиҪҰдҪҚзҡ„"еҒңиҪҰж¬Ўж•°"жҳҜ8
- е°ұз®—еҗҢдёҖеӨ©жңүзӣёеҗҢзҡ„иҪҰеңЁдёҚеҗҢж—¶ж®өеҒңж”ҫ пјҢ еҸӘз®—дёҖж¬Ў
еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
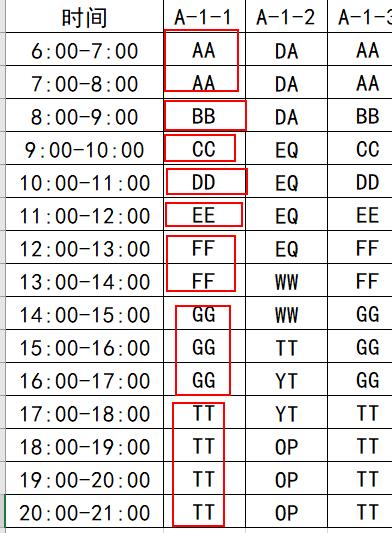
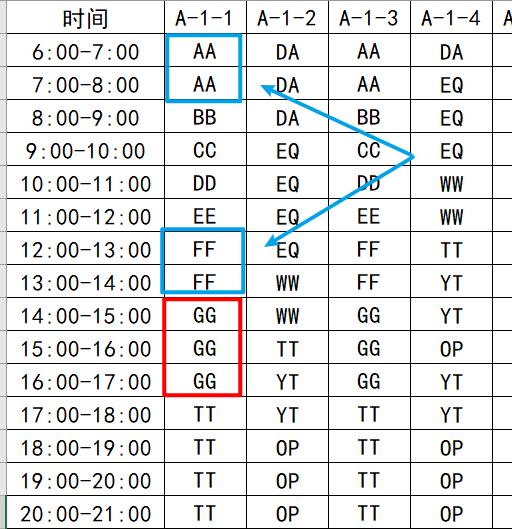
ж–Үз« жҸ’еӣҫ- 第дёҖдёӘеҒңиҪҰдҪҚдёӯ пјҢ иҝһз»ӯеҮәзҺ°3ж¬Ўзҡ„еҢәеҹҹеҸӘжңүдёҖдёӘ(3дёӘ"GG")пјҢ еӣ жӯӨиҝҷдёӘеҒңиҪҰдҪҚ"иҝһз»ӯеҒңиҪҰ3е°Ҹж—¶"з»“жһңжҳҜ1
- еҗҢзҗҶ пјҢ "иҝһз»ӯеҒңиҪҰ2е°Ҹж—¶"з»“жһңжҳҜ2(еҲҶеҲ«жҳҜ"AA"дёҺ"FF")
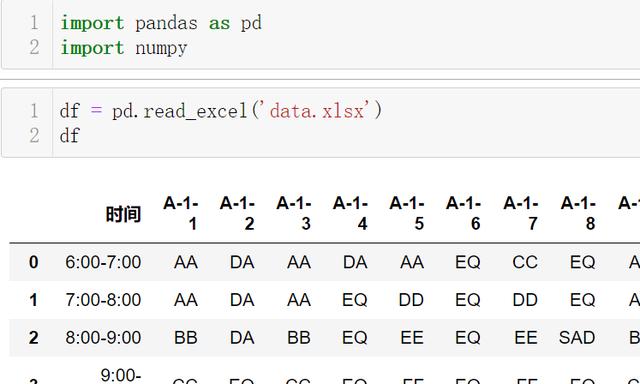 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫйңҖжұӮ1жҢүзҗҶи§Ј пјҢ еҸҜд»ҘжҸҸиҝ°дёә"дёҚеҗҢиҪҰзүҢж•°йҮҸ" пјҢ зӣёеҪ“дәҺеҺ»йҮҚеӨҚеҗҺзҡ„иҪҰзүҢж•° гҖӮ
еӣ жӯӨд»Јз Ғйқһеёёз®ҖеҚ•пјҡ
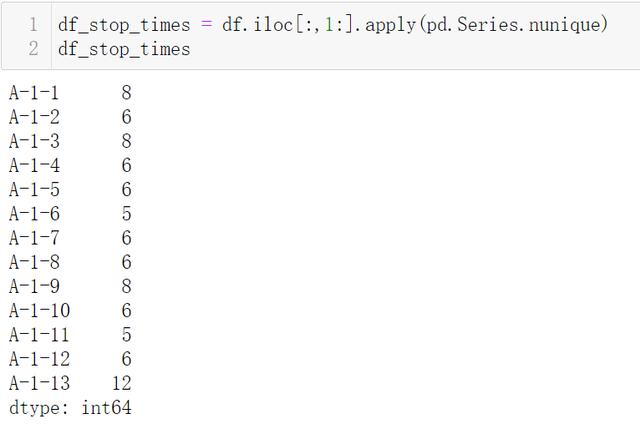 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ- df.ilocпјҢ з”ұдәҺ第дёҖеҲ—жҳҜ"ж—¶й—ҙ" пјҢ дёҚжҳҜйңҖиҰҒзҡ„ж•°жҚ® пјҢ йҖҡиҝҮеҲҮзүҮиҺ·еҸ–第дёҖеҲ—еҲ°жңҖеҗҺзҡ„жүҖжңүеҲ—
- .applyпјҢ жіЁж„ҸеҸӮж•° axis й»ҳи®Өдёә0 пјҢ иЎЁзӨәж•°жҚ®иЎЁжҜҸдёҖеҲ—дҪңдёәеӨ„зҗҶеҚ•дҪҚ
- pd.Series.nunique е°ұжҳҜеҺ»йҮҚи®Ўж•°
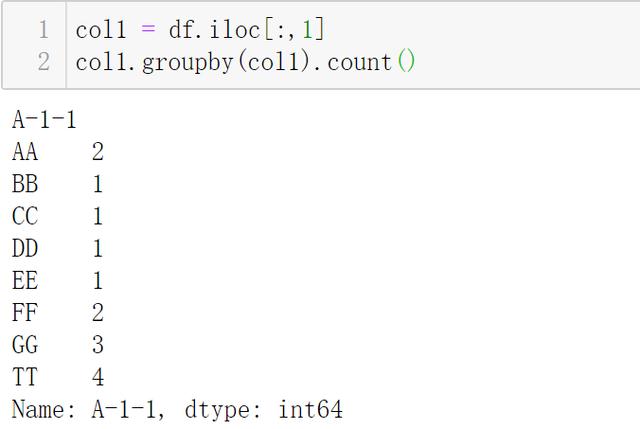 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ- жҲ‘иҝҷеҸӘиҖғиҷ‘дёҖеҲ—зҡ„еӨ„зҗҶжғ…еҶө пјҢ еӣ дёәжүҖжңүеҲ—жү№йҮҸеӨ„зҗҶеҸӘйңҖиҰҒи°ғз”Ё apply еҚіеҸҜ
- иҝҷйҮҢеҗҢж ·еҸҜд»ҘдҪҝз”Ё Series.value_counts() еҒҡеҲ°дёҖж ·зҡ„ж•Ҳжһң
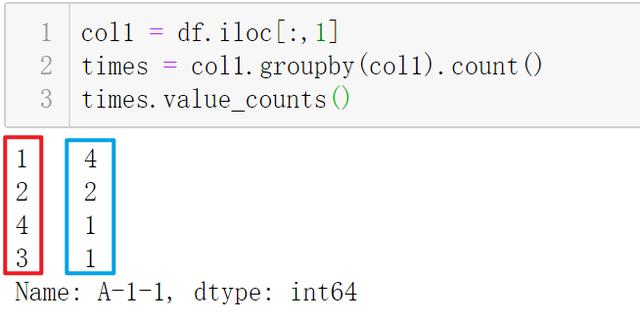 ж–Үз« жҸ’еӣҫ
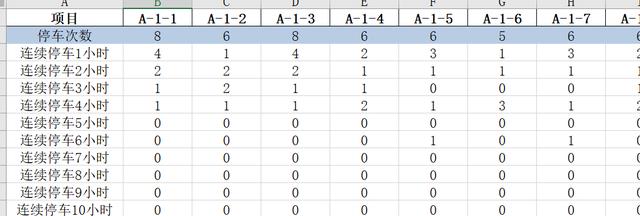
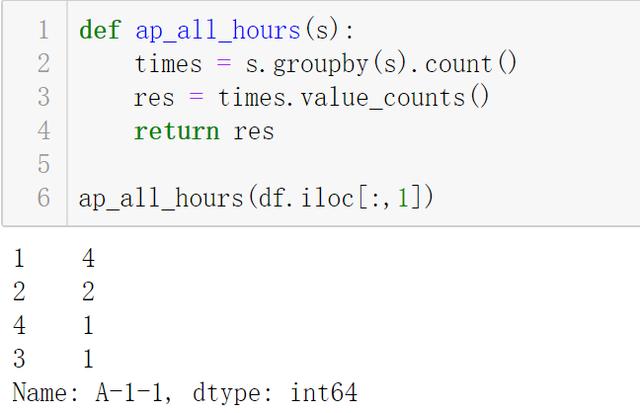
ж–Үз« жҸ’еӣҫ- иЎҢ3пјҡжҢүд№ӢеүҚзҡ„еӨ„зҗҶ пјҢ з»ҹи®Ўж¬Ўж•°
- жіЁж„ҸжӯӨж—¶з»“жһңжҳҜдёҖдёӘ Series пјҢ index(дёҠеӣҫзәўжЎҶ) жҳҜ"иҝһз»ӯnе°Ҹж—¶еҒңиҪҰ" гҖӮ value(дёҠеӣҫи“қжЎҶ) жҳҜиҝһз»ӯnе°Ҹж—¶еҒңиҪҰеҮәзҺ°зҡ„ж¬Ўж•°
 ж–Үз« жҸ’еӣҫ
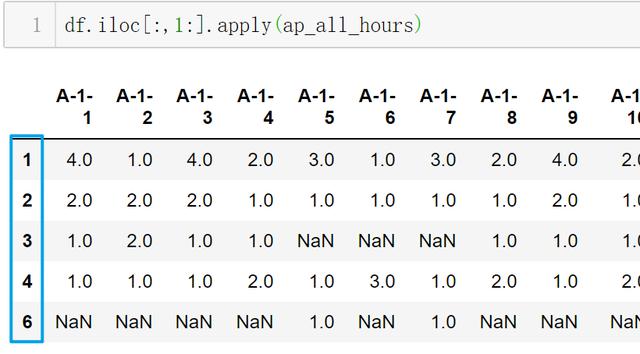
ж–Үз« жҸ’еӣҫ- иЎҢ6пјҡйҖүеҮәдёҖеҲ—жү§иЎҢзңӢзңӢж•Ҳжһң
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ- жіЁж„Ҹ иЎҢзҙўеј•(и“қжЎҶ) жҳҜ"иҝһз»ӯnе°Ҹж—¶еҒңиҪҰ"
reindex е°ұжҳҜдёәдәҶиҝҷз§ҚеңәжҷҜиҖҢи®ҫи®Ўпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ- иЎҢ4пјҡйЎәжүӢжҠҠз©әеҖјеЎ«жҲҗ 0
жҺЁиҚҗйҳ…иҜ»
- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘
- 2021е№ҙJavaе’ҢPythonзҡ„еә”з”Ёи¶ӢеҠҝдјҡжңүд»Җд№ҲеҸҳеҢ–пјҹ
- йқһи®Ўз®—жңәдё“дёҡзҡ„жң¬з§‘з”ҹпјҢжғіеҲ©з”ЁеҜ’еҒҮеӯҰд№ PythonпјҢиҜҘжҖҺд№Ҳе…ҘжүӢ
- з”ЁPythonеҲ¶дҪңеӣҫзүҮйӘҢиҜҒз ҒпјҢиҝҷдёүиЎҢд»Јз Ғе®ҢдәӢе„ҝ
- еҺҶж—¶ 1 дёӘжңҲпјҢеҒҡдәҶ 10 дёӘ Python еҸҜи§ҶеҢ–еҠЁеӣҫпјҢз”Ёеҝғдё”зІҫзҫҺ...
- дёәдҪ•еңЁдәәе·ҘжҷәиғҪз ”еҸ‘йўҶеҹҹPythonеә”з”ЁжҜ”иҫғеӨҡ
- еҜ№дәҺйқһи®Ўз®—жңәдё“дёҡзҡ„еҗҢеӯҰжқҘиҜҙпјҢиҜҘйҖүжӢ©еӯҰд№ PythonиҝҳжҳҜC
- еӯҰд№ е®ҢPythonд№ӢеҗҺпјҢеҰӮдҪ•еҗ‘дәәе·ҘжҷәиғҪйўҶеҹҹеҸ‘еұ•

















