内容推荐算法:异构行为序列建模探索( 四 )
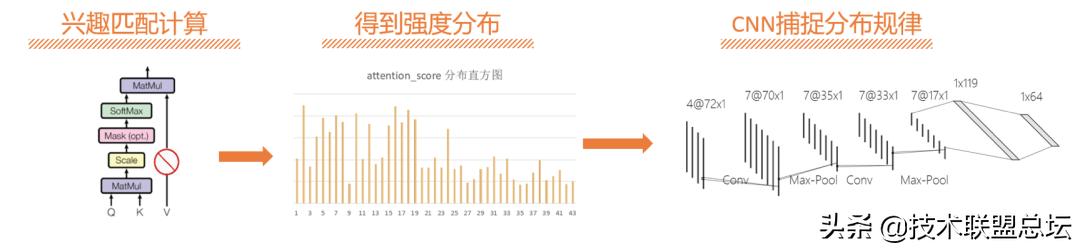
兴趣强度的分布可以用直方图作可视化(图2-4 , 中间部分) ,那么怎么样的分布会倾向于较高的ctr呢? 是整体偏高但平缓 ,还是少数几个柱子鹤立鸡群的观感呢? 类比于图像特征的捕捉 ,我们用CNN作后续的特征提取 。
 文章插图
文章插图
图2-4.兴趣匹配强度 完整设计
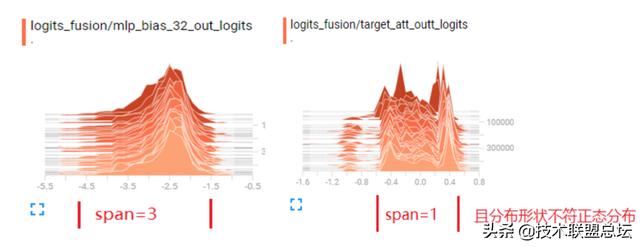
? auxiliary loss 设计验证了兴趣匹配强度建模的有效性后 ,将其作为子模块迁回原有网络参与训练 ,再次遗憾地发现attention可视化分布中的对角线再次消失 ,离线指标也涨幅有限 。
 文章插图
文章插图
图2-5.添加辅助loss前 ,兴趣匹配强度参与logits加和 ,其值域跨度和分布形状皆不符预期 ,体现不出异构序列的应有贡献
模型可能也会偷懒,bias及prefer类特征规律性强 ,容易学习 ,就放弃了兴趣匹配子模块的学习 。 此时就要用 图2-1中In_CTR架构的loss处理方法 ,在其参与logits加和的同时 ,也为其独立出一个loss ,并分配合适的权重(实验中为0.65 ,较为激进) 。 再次试验并观察logits分布 ,符合预期 。
文末小总与展望用户行为序列是其兴趣与意图的原始表达 , 重要性等同于搜索场景下的query输入 。 商品行为作为异构序列 , 如何在跨domain的洋淘推荐中建模? 围绕这一挑战 , 我们创新性地提出了:
- In_Match , 用序列生成的task训练decoder , 抽取其顶层输出向量作内容召回 , 召回效果超越内容协同;
- In_CTR , 将motivation由常规的序列兴趣的直接表达转换为序列兴趣的匹配程度 , 并根据这一先验设想设计了辅助loss , 鼓励模型有所侧重地去学习 , 最终离在线指标上都有斩获 。
推荐阅读
















- 金士顿发布Workflow Station - 为内容创作者设计的模块化底座
- 目前配置全性价比高的手机,我只推荐五款,闭着眼买都不会错
- 向日葵远程控制企业版客户端更新升级,优化远控UI适配SADDC内核算法
- 微软调侃WhatsApp隐私策略调整 并推荐用户迁移至Skype
- 玩转光追大作最低需要什么配置?快来看小狮子的推荐
- 身边噪音烟消云散 三款颈挂式降噪蓝牙耳机推荐
- 爽玩光追大作,RTX 3060Ti性价比电脑推荐
- 多多|拼多多:知乎账号内容系供应商员工自行发布,不代表公司态度
- “记”兴之作 智能手写本推荐——柔宇RoWrite 2
- 小米11再开售,小米有品推荐这3款手机配件