AnalyticDB向量检索+AI 实战:声纹识别
分析型数据库(AnalyticDB)是阿里云上的一种高并发低延时的PB级实时数据仓库 , 可以毫秒级针对万亿级数据进行即时的多维分析透视和业务探索 , 向量检索和非结构化数据分析是AnalyticDB的进阶功能 。 本文通过声纹识别的例子展示如何快速搭建一套端对端的非结构数据搜索服务 。
01 背 景
近年来 , 随着人工智能对传统行业的赋能改造 , 越来越多的基于人工智能的业务解决方案被提出来 , 声纹识别在保险行业中的身份认证便是一个很好的例子. 声纹识别是根据说话人发音的生理和行为特征 , 自动识别说话人身份的一种生物识别技术 , 对应在电话销售场景下 , 它主要解决以下安全问题:一方面 , 有不法分子窃取电话销售人员账号信息 , 非法获取客户个人信息资料并进行贩卖、泄露 , 严重侵犯了公民个人的信息隐私权 , 另一方面 , 部分行业从业人员利用一些规则漏洞 , 通过套保、骗保等非法手段实施金融诈骗. 针对这些安全问题 , 可以通过实时声纹认证加以解决 , 以电话销售人员为监管核心 , 利用每个人独一无二的声纹进行严密的个人身份认证 , 保证电话销售人员对接客户时是本人注册登录 , 规范电销人员行为 , 从源头上有效规避信息泄露、漏洞利用等风险 。
【AnalyticDB向量检索+AI 实战:声纹识别】02 声纹识别原理
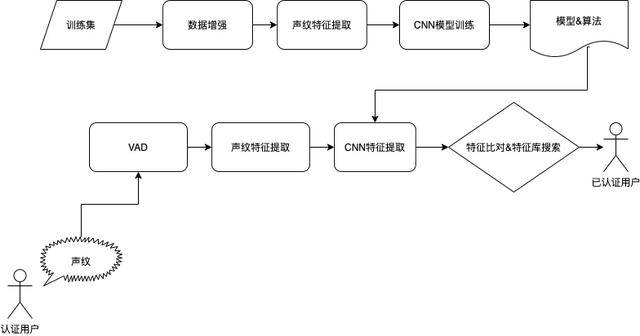 文章插图
文章插图
上图是端对端的深度学习训练和推理过程 。 对比传统声纹识别模型 , 我们的模型在实际使用中优势明显 , 在用户远程身份验证场景 , 通过注册用户说一段话 , 即可轻松快速的确认注册用户身份 , 识别准确率达到95%以上 , 秒级响应 , 实时声纹核身 。 下面简要介绍我们模型的特点 。
2.0 度量学习
实验发现 , 在声纹识别中采用softmax进行网络训练, 用余弦相似度的测试性能往往不如传统声纹识别模型 , 尤其是在鲁棒性上 。 分析发现[6]基于softmax的分类训练 , 为了得到更小的loss , 优化器会增大一些easy samples的L2 length , 减小hard examples 的L2 length , 导致这些样本并没有充分学习 , 特征呈现放射状 , 以MNIST识别任务为例 , 基于softmax学到的特征分布如图3(a)所示. 同类别特征分布并不聚拢 , 在L2 长度上拉长 , 呈放射状 , 且每个类别的间距并不大 , 在verification的任务中 , 会导致相邻的两个类别得分很高 。
为了达到类内聚拢 , 类间分散的效果 , 我们研究了在图像领域中应用较为成功的几种softmax变种 , 包括AM-softmax[4] , arcsoftmax[5]等 , 从图3(b)可以看到 , 基于margin的softmax , 相比纯softmax , 类间的分散程度更大 , 且类内特征更聚拢 , 对声纹1:1比对和1:N搜索的任务友好 。
 文章插图
文章插图
2.1 噪音鲁棒性
在特征提取时 , 对于简单加性噪音 , 我们提出了基于功率谱减法 , 实现噪音抑制;对于其他复杂噪音 , 我们提出了基于降噪自动编码器的噪音补偿模型 , 将带噪语音特征映射到干净语音特征 , 实现噪音消除 。
在模型训练时 , 我们采用数据增强的训练机制 , 将噪音数据通过随机高斯的形式加入到声纹模型的训练中 , 使得训练后的模型对噪音数据具有更好的鲁棒性 。
2.2 短音频鲁棒性
为了提高短音频鲁棒性 , 我们提出了基于短时帧级别的模型训练机制 , 使模型能够在极短的语音时长(约0.5秒)下即可完成声纹识别. 在此基础上 , 我们在模型训练中引入了更多高阶的音频统计信息和正则化方法 , 进一步提升了模型在短语音条件下(2~3秒)的识别精度 。
03 如何使用AnalyticDB搭建声纹对比系统
3.0 创建插件
使用一下SQL来分别创建AnalyticDB的非结构化分析插件OpenAnalytic和向量检索插件fastann 。
推荐阅读












- 支持向量机超参数的可视化解释
- Facebook开源人工智能模型RAG:可检索文档以回答问题
- 信息检索站|5000mAh,65W快充,售价不足三千的骁龙865旗舰
- 信息检索站|真正三年不卡,骁龙865+144Hz,国产首款16G运存旗舰
- 信息检索站|麒麟985强机加量不加价,卖价不足二千七,高达50倍变焦