ж”ҜжҢҒеҗ‘йҮҸжңәи¶…еҸӮж•°зҡ„еҸҜи§ҶеҢ–и§ЈйҮҠ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
гҖҗж”ҜжҢҒеҗ‘йҮҸжңәи¶…еҸӮж•°зҡ„еҸҜи§ҶеҢ–и§ЈйҮҠгҖ‘ж”ҜжҢҒеҗ‘йҮҸжңәпјҲSVMпјүжҳҜдёҖз§Қеә”з”Ёе№ҝжіӣзҡ„жңүзӣ‘зқЈжңәеҷЁеӯҰд№ з®—жі• гҖӮ е®ғдё»иҰҒз”ЁдәҺеҲҶзұ»д»»еҠЎ пјҢ дҪҶд№ҹйҖӮз”ЁдәҺеӣһеҪ’д»»еҠЎ гҖӮ
еңЁиҝҷзҜҮж–Үз« дёӯ пјҢ жҲ‘们е°Ҷж·ұе…ҘжҺўи®Ёж”ҜжҢҒеҗ‘йҮҸжңәзҡ„дёӨдёӘйҮҚиҰҒи¶…еҸӮж•°Cе’Ңgamma пјҢ 并йҖҡиҝҮеҸҜи§ҶеҢ–и§ЈйҮҠе®ғ们зҡ„еҪұе“Қ гҖӮ жүҖд»ҘжҲ‘еҒҮи®ҫдҪ еҜ№з®—жі•жңүдёҖдёӘеҹәжң¬зҡ„зҗҶи§Ј пјҢ 并жҠҠйҮҚзӮ№ж”ҫеңЁиҝҷдәӣи¶…еҸӮж•°дёҠ гҖӮ
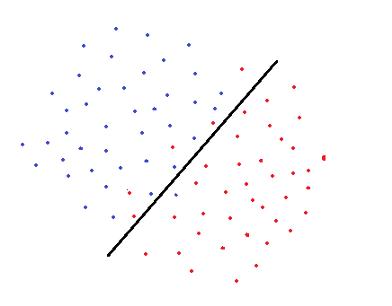
ж”ҜжҢҒеҗ‘йҮҸжңәз”ЁдёҖдёӘеҶізӯ–иҫ№з•ҢжқҘеҲҶзҰ»еұһдәҺдёҚеҗҢзұ»еҲ«зҡ„ж•°жҚ®зӮ№ гҖӮ еңЁзЎ®е®ҡеҶізӯ–иҫ№з•Ңж—¶ пјҢ иҪҜй—ҙйҡ”ж”ҜжҢҒеҗ‘йҮҸжңәпјҲsoft marginжҳҜжҢҮе…Ғи®ёжҹҗдәӣж•°жҚ®зӮ№иў«й”ҷиҜҜеҲҶзұ»пјүиҜ•еӣҫи§ЈеҶідёҖдёӘдјҳеҢ–й—®йўҳ пјҢ зӣ®ж ҮеҰӮдёӢпјҡ
- еўһеҠ еҶізӯ–иҫ№з•ҢеҲ°зұ»пјҲжҲ–ж”ҜжҢҒеҗ‘йҮҸпјүзҡ„и·қзҰ»
- дҪҝи®ӯз»ғйӣҶдёӯжӯЈзЎ®еҲҶзұ»зҡ„зӮ№ж•°жңҖеӨ§еҢ–
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫжҳҫ然 пјҢ иҝҷдёӨдёӘзӣ®ж Үд№Ӣй—ҙжңүдёҖдёӘжҠҳиЎ· пјҢ е®ғжҳҜз”ұCжҺ§еҲ¶зҡ„ пјҢ е®ғдёәжҜҸдёҖдёӘй”ҷиҜҜеҲҶзұ»зҡ„ж•°жҚ®зӮ№еўһеҠ дёҖдёӘжғ©зҪҡ гҖӮ
еҰӮжһңCеҫҲе°Ҹ пјҢ еҜ№иҜҜеҲҶзұ»зӮ№зҡ„жғ©зҪҡеҫҲдҪҺ пјҢ еӣ жӯӨйҖүжӢ©дёҖдёӘе…·жңүиҫғеӨ§й—ҙйҡ”зҡ„еҶізӯ–иҫ№з•ҢжҳҜд»ҘзүәзүІжӣҙеӨҡзҡ„й”ҷиҜҜеҲҶзұ»дёәд»Јд»·зҡ„ гҖӮ
еҪ“CеҖјиҫғеӨ§ж—¶ пјҢ ж”ҜжҢҒеҗ‘йҮҸжңәдјҡе°ҪйҮҸеҮҸе°‘иҜҜеҲҶзұ»ж ·жң¬зҡ„ж•°йҮҸ пјҢ еӣ дёәжғ©зҪҡдјҡеҜјиҮҙеҶізӯ–иҫ№з•Ңе…·жңүиҫғе°Ҹзҡ„й—ҙйҡ” гҖӮ еҜ№дәҺжүҖжңүй”ҷиҜҜеҲҶзұ»зҡ„дҫӢеӯҗ пјҢ жғ©зҪҡжҳҜдёҚдёҖж ·зҡ„ гҖӮ е®ғдёҺеҲ°еҶізӯ–иҫ№з•Ңзҡ„и·қзҰ»жҲҗжӯЈжҜ” гҖӮ
еңЁиҝҷдәӣдҫӢеӯҗд№ӢеҗҺдјҡжӣҙеҠ жё…жҘҡ гҖӮ и®©жҲ‘们йҰ–е…ҲеҜје…Ҙеә“并еҲӣе»әдёҖдёӘеҗҲжҲҗж•°жҚ®йӣҶ гҖӮ
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt%matplotlib inlinefrom sklearn.svm import SVCfrom sklearn.datasets import make_classificationX, y = make_classification(n_samples=200, n_features=2,n_informative=2, n_redundant=0, n_repeated=0, n_classes=2,random_state=42)plt.figure(figsize=(10,6))plt.title("Synthetic Binary Classification Dataset", fontsize=18)plt.scatter(X[:,0], X[:,1], c=y, cmap='cool')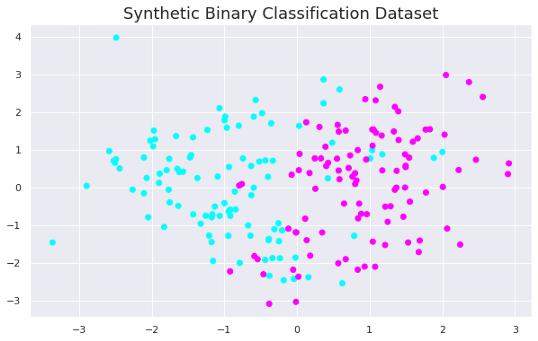 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫжҲ‘们е…Ҳи®ӯз»ғдёҖдёӘеҸӘйңҖи°ғж•ҙCзҡ„зәҝжҖ§ж”ҜжҢҒеҗ‘йҮҸжңә пјҢ 然еҗҺе®һзҺ°дёҖдёӘRBFж ёзҡ„ж”ҜжҢҒеҗ‘йҮҸжңә пјҢ еҗҢж—¶и°ғж•ҙgammaеҸӮж•° гҖӮ
жҲ‘们зҺ°еңЁеҸҜд»ҘеҲӣе»әдёӨдёӘдёҚеҗҢCеҖјзҡ„зәҝжҖ§SVMеҲҶзұ»еҷЁ гҖӮ
clf = SVC(C=0.1, kernel='linear').fit(X, y)plt.figure(figsize=(10,6))plt.title("Linear kernel with C=0.1", fontsize=18)plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='cool')plot_svc_decision_function(clf)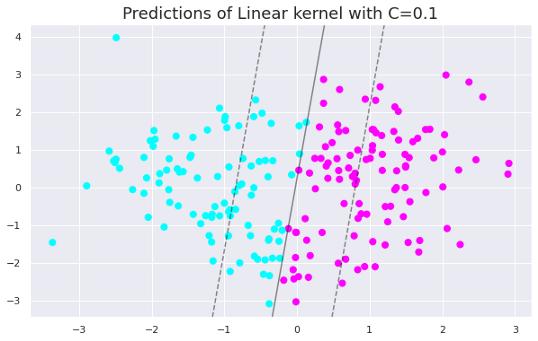 ж–Үз« жҸ’еӣҫ
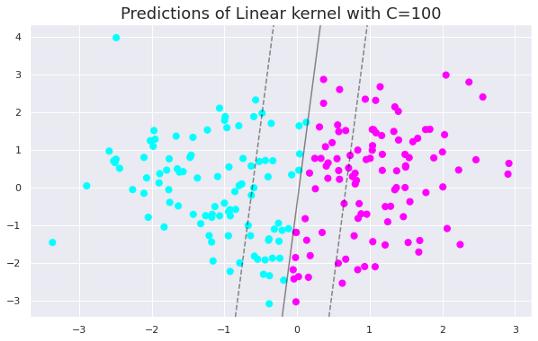
ж–Үз« жҸ’еӣҫеҸӘйңҖе°ҶCеҖјжӣҙж”№дёә100еҚіеҸҜз”ҹжҲҗд»ҘдёӢз»ҳеӣҫ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫеҪ“жҲ‘们еўһеҠ CеҖјж—¶ пјҢ й—ҙйҡ”дјҡеҸҳе°Ҹ гҖӮ еӣ жӯӨ пјҢ дҪҺCеҖјзҡ„жЁЎеһӢжӣҙе…·жҷ®йҒҚжҖ§ гҖӮ йҡҸзқҖж•°жҚ®йӣҶзҡ„еўһеӨ§ пјҢ иҝҷз§Қе·®ејӮеҸҳеҫ—жӣҙеҠ жҳҺжҳҫ гҖӮ
зәҝжҖ§ж ёзҡ„и¶…еҸӮж•°еҸӘиҫҫеҲ°дёҖе®ҡзЁӢеәҰдёҠзҡ„еҪұе“Қ гҖӮ еңЁйқһзәҝжҖ§еҶ…ж ёдёӯ пјҢ и¶…еҸӮж•°зҡ„еҪұе“ҚжӣҙеҠ жҳҺжҳҫ гҖӮ
GammaжҳҜз”ЁдәҺйқһзәҝжҖ§ж”ҜжҢҒеҗ‘йҮҸжңәзҡ„и¶…еҸӮж•° гҖӮ жңҖеёёз”Ёзҡ„йқһзәҝжҖ§ж ёеҮҪж•°д№ӢдёҖжҳҜеҫ„еҗ‘еҹәеҮҪж•°пјҲRBFпјү гҖӮ RBFзҡ„GammaеҸӮж•°жҺ§еҲ¶еҚ•дёӘи®ӯз»ғзӮ№зҡ„еҪұе“Қи·қзҰ» гҖӮ
gammaеҖјиҫғдҪҺиЎЁзӨәзӣёдјјеҚҠеҫ„иҫғеӨ§ пјҢ иҝҷдјҡеҜјиҮҙе°ҶжӣҙеӨҡзҡ„зӮ№з»„еҗҲеңЁдёҖиө· гҖӮ еҜ№дәҺgammaеҖјиҫғй«ҳзҡ„жғ…еҶө пјҢ зӮ№д№Ӣй—ҙеҝ…йЎ»йқһеёёжҺҘиҝ‘ пјҢ жүҚиғҪе°Ҷе…¶и§ҶдёәеҗҢдёҖз»„пјҲжҲ–зұ»пјү гҖӮ еӣ жӯӨ пјҢ е…·жңүйқһеёёеӨ§gammaеҖјзҡ„жЁЎеһӢеҫҖеҫҖиҝҮжӢҹеҗҲ гҖӮ
и®©жҲ‘们з»ҳеҲ¶дёүдёӘдёҚеҗҢgammaеҖјзҡ„ж”ҜжҢҒеҗ‘йҮҸжңәзҡ„йў„жөӢеӣҫ гҖӮ
clf = SVC(C=1, kernel='rbf', gamma=0.01).fit(X, y)y_pred = clf.predict(X)plt.figure(figsize=(10,6))plt.title("Predictions of RBF kernel with C=1 and Gamma=0.01", fontsize=18)plt.scatter(X[:, 0], X[:, 1], c=y_pred, s=50, cmap='cool')plot_svc_decision_function(clf)
жҺЁиҚҗйҳ…иҜ»
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- й»‘йІЁ4proд»Җд№Ҳж—¶еҖҷеҮәеӨҡе°‘й’ұпјҢй»‘йІЁ4proд»·ж јеҸӮж•°д»Ӣз»Қ
- зәўзұіk40proе’Ңiqooneo3е“ӘдёӘеҘҪжҖ§д»·жҜ”й«ҳ еҸӮж•°еҜ№жҜ”еҢәеҲ«иҜ„жөӢ
- JBLжҺЁеҮәSA750з«ӢдҪ“еЈ°еҠҹж”ҫпјҡж”ҜжҢҒAirplay 2 е”®д»·3000зҫҺе…ғ
- зҙўе°је…¬еёғ2021е№ҙз”өи§Ҷйҳөе®№пјҡж”ҜжҢҒ4K 120Hz й…Қе…Ёж–°XRиҠҜзүҮ
- дёҖеҠ йҰ–ж¬ҫеҸҜз©ҝжҲҙи®ҫеӨҮOnePlus Bandж¶ҲжҒҜжұҮжҖ»пјҡд»·ж јгҖҒеҸӮж•°гҖҒеҠҹиғҪе…ЁжҸӯз§ҳ
- дёүжҳҹзҺҜдҝқз”өи§ҶйҒҘжҺ§еҷЁд»Ӣз»ҚпјҡиһҚе…ҘеҶҚз”ҹеЎ‘ж–ҷ ж”ҜжҢҒеӨӘйҳіиғҪе……з”ө
- иҚЈиҖҖV40жӯЈејҸеҫ—еҲ°зЎ®и®ӨпјҒеҸӮж•°й…ҚзҪ®д№ҹеҹәжң¬зЎ®е®ҡпјҒе”®д»·жҲ–е°ҶжҳҜжғҠе–ң
- еҚҺдёәз•…дә«20seе’Ңзәўзұіnote9е“ӘдёӘеҘҪеҢәеҲ«еңЁе“Ә еҸӮж•°еҜ№жҜ”иҜ„жөӢ
- realmev15е’Ңrealmev3еҢәеҲ«еҸӮж•°еҜ№жҜ” е“ӘдёӘеҘҪжҖ§д»·жҜ”й«ҳ
- зәўзұіk40proе’ҢиҚЈиҖҖ30еҢәеҲ«е“ӘдёӘеҘҪ дёҚеҗҢзӮ№еҜ№жҜ”еҸӮж•°й…ҚзҪ®и°ҒеҘҪ
















