FlinkжөҒеӨ„зҗҶеә”з”ЁеңЁIDEAдёӯзҡ„жү§иЎҢжөҒзЁӢеҲҶжһҗ
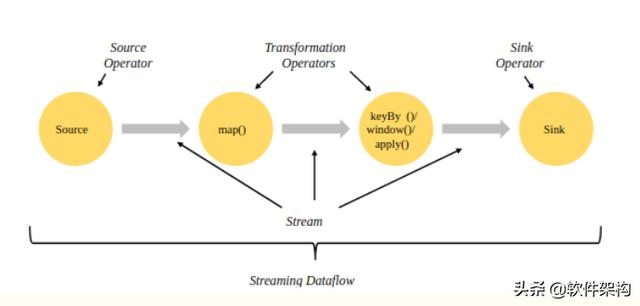
гҖҗFlinkжөҒеӨ„зҗҶеә”з”ЁеңЁIDEAдёӯзҡ„жү§иЎҢжөҒзЁӢеҲҶжһҗгҖ‘FlinkжөҒејҸи®Ўз®—зҡ„ж ёеҝғжҰӮеҝөе°ұжҳҜе°Ҷж•°жҚ®д»Һиҫ“е…ҘжөҒдёҖдёӘдёӘдј йҖ’з»ҷoperatorиҝӣиЎҢй“ҫејҸеӨ„зҗҶ пјҢ жңҖеҗҺдәӨз»ҷиҫ“еҮәжөҒзҡ„иҝҮзЁӢ гҖӮ еҜ№ж•°жҚ®зҡ„жҜҸдёҖж¬ЎеӨ„зҗҶеңЁйҖ»иҫ‘дёҠжҲҗдёәдёҖдёӘoperatorпјҲз®—еӯҗпјү гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
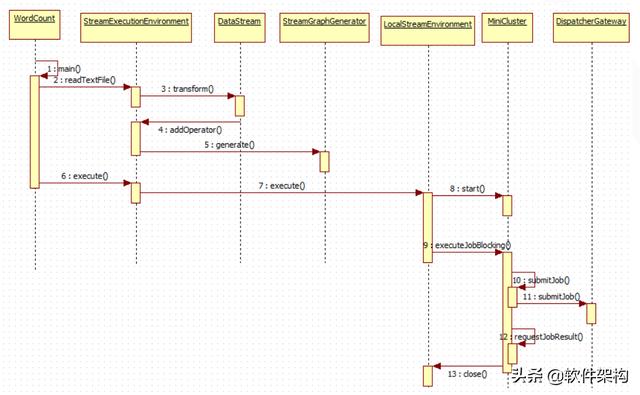
Flinkз»Ҹе…ёзӨәдҫӢWordCountжөҒеӨ„зҗҶеә”з”Ё-ж•ҙдёӘжү§иЎҢжөҒзЁӢеҰӮдёӢеӣҫжүҖзӨәпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
第1~4жӯҘпјҡmainж–№жі•иҜ»еҸ–ж–Ү件 пјҢ еўһеҠ з®—еӯҗпјӣ
第5жӯҘпјҡдә§з”ҹStreamGraph пјҢ д»ҺиҖҢеҸҜд»Ҙеҫ—еҲ°JobGraph пјҢ еҚіе°ҶStreamзЁӢеәҸиҪ¬жҚўжҲҗJobGraphпјӣ
第6~8жӯҘпјҡLocalEnvironment жҳҜжң¬ең°жү§иЎҢд»»еҠЎзҡ„зҺҜеўғ пјҢ иҙҹиҙЈеҗҜеҠЁMiniCluster пјҢ еңЁжң¬ең°жү§иЎҢFlinkд»»еҠЎ гҖӮ MiniClusterеҸҜд»ҘзңӢеҒҡжҳҜеҶ…еөҢзҡ„FlinkиҝҗиЎҢж—¶зҺҜеўғ пјҢ жүҖжңүзҡ„组件йғҪеңЁзӢ¬з«Ӣзҡ„жң¬ең°зәҝзЁӢдёӯиҝҗиЎҢ гҖӮ MiniClusterзҡ„еҗҜеҠЁе…ҘеҸЈеңЁLocalStreamEnvironment#execute(jobName)дёӯ гҖӮ
第9~12жӯҘпјҡжү§иЎҢjobпјӣ
第13жӯҘпјҡе…ій—ӯжү§иЎҢжөҒзЁӢпјӣ
жҺЁиҚҗйҳ…иҜ»
















- NVIDIA 5nmжһ¶жһ„зҢӣж–ҷпјҡжөҒеӨ„зҗҶеҷЁи¶…1.84дёҮдёӘ
- FlinkSQL еҠЁжҖҒеҠ иҪҪ UDF е®һзҺ°жҖқи·Ҝ
- 18432дёӘжөҒеӨ„зҗҶеҷЁ зҪ‘дј дёӢдёҖд»ЈNеҚЎжҖ§иғҪејәеӨ§
- дёҮеӯ—е№Іиҙ§иҝҳеҺҹзҫҺеӣўFlinkе®һж—¶ж•°д»“е»әи®ҫ
- зҪ‘жҳ“дә‘йҹід№җеҹәдәҺFlinkе®һж—¶ж•°д»“е®һи·ө
- flinkж¶Ҳиҙ№kafkaзҡ„offsetдёҺcheckpoint
- е”Ҝе“Ғдјҡе®һж—¶е№іеҸ°жһ¶жһ„-FlinkгҖҒSparkгҖҒStorm
- Apache HudiдёҺApache FlinkйӣҶжҲҗ
- Flinkзҡ„DataSetеҹәжң¬з®—еӯҗжҖ»з»“
- Flinkдёӯparallelism并иЎҢеәҰе’Ңslotж§ҪдҪҚзҡ„зҗҶи§Ј