Linuxзі»з»ҹзҪ‘з»ңжҖ§иғҪе®һдҫӢеҲҶжһҗ( еӣӣ )
1гҖҒ NetBench
дёӢеӣҫжүҖзӨәдёә LinuxеҶ…ж ёдёҺ Sambaзҡ„еҗ„з§Қеўһејәе’Ңи°ғдјҳжңәеҲ¶з»ҷ NetBenchеҹәеҮҶзЁӢеәҸеҗһеҗҗзҺҮеёҰжқҘзҡ„жҖ§иғҪж”№иҝӣ гҖӮ иҝҷдәӣжөӢиҜ•зҡ„硬件жү§иЎҢзҺҜеўғжҳҜз”ұ 4дёӘ 1.5GHz P4еӨ„зҗҶеҷЁгҖҒ 4дёӘеҚғе…ҶдҪҚд»ҘеӨӘзҪ‘йҖӮй…ҚеҷЁгҖҒ 2GBеҶ…еӯҳд»ҘеҸҠ 14дёӘ 15krpm SCSIзЈҒзӣҳжһ„жҲҗзҡ„ Pentium 4зі»з»ҹ гҖӮжүҖжңүжөӢиҜ•йғҪдҪҝз”Ё SUSE 8.0зүҲжң¬ гҖӮжҜҸж¬ЎеҗҺз»ӯжөӢиҜ•йғҪдјҡеҢ…еҗ«дёҖдёӘж–°зҡ„еҶ…ж ёгҖҒ и°ғдјҳжҲ– SambaеҸҳеҢ– гҖӮ жүҖжңүжөӢиҜ•йғҪдҪҝз”ЁZiff-Davisзҡ„ NetBench Enterprise Disk SuiteеҹәеҮҶзЁӢеәҸгҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
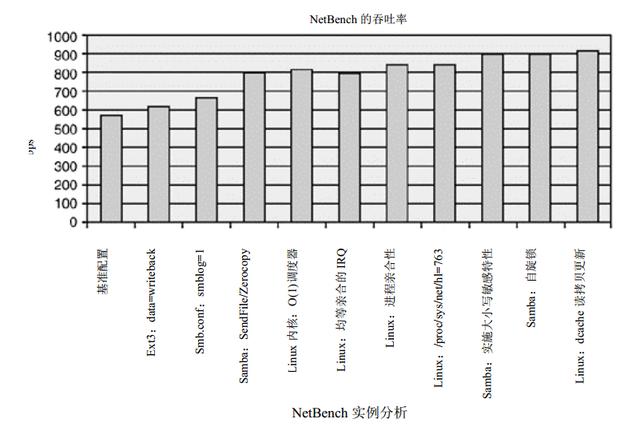
дёӢйқўжҸҸиҝ°дәҶдёҠеӣҫдёӯеҗ„еҲ—зҡ„еҗҚз§°пјҡ
- еҹәеҮҶй…ҚзҪ®(Baseline) гҖӮ д»ЈиЎЁдәҶ SUSE LinuxдјҒдёҡзә§жңҚеҠЎеҷЁ 8.0зүҲжң¬(SUSE SLES 8)зҡ„дёҖдёӘе№ІеҮҖе®үиЈ… пјҢ жңӘеҜ№жҖ§иғҪй…ҚзҪ®иҝӣиЎҢд»»дҪ•дҝ®ж”№ гҖӮ
- data=http://kandian.youth.cn/index/writeback гҖӮеҜ№дёҖдёӘ Ext3й»ҳи®ӨжҢӮжҺҘйҖүйЎ№зҡ„й…ҚзҪ®еҠ д»Ҙж”№еҠЁ пјҢ е°Ҷ/dataж–Ү件系з»ҹ(жҸҗдҫӣдәҶ Sambaе…ұдә«)д»Һ orderedж”№дёәwriteback гҖӮ иҝҷжһҒеӨ§ж”№иҝӣдәҶж–Ү件系з»ҹеңЁе…ғж•°жҚ®еҜҶйӣҶзҡ„е·ҘдҪңиҙҹиҚ·дёӢзҡ„жҖ§иғҪ пјҢ дҫӢеҰӮжң¬дҫӢ гҖӮ
- smblog=1 гҖӮ Sambaж—Ҙеҝ—зә§еҲ«д»Һ 2ж”№дёә 1 пјҢ д»ҘеҮҸе°‘еҜ№ Sambaж—Ҙеҝ—ж–Ү件зҡ„зЈҒзӣҳ I/Oж“ҚдҪң гҖӮ зә§еҲ«1и¶ід»Ҙе°Ҷе…ій”®й”ҷиҜҜи®°е…Ҙж—Ҙеҝ—дёӯ гҖӮ
- SendFile/Zerocopy гҖӮиҜҘиЎҘдёҒдҪҝеҫ— SambaеҜ№дәҺе®ўжҲ·иҜ»иҜ·жұӮдҪҝз”Ё SendFileжңәеҲ¶ гҖӮ иҜҘиЎҘдёҒдёҺ Linuxзҡ„ ZerocopyжҠҖжңҜ(жңҖж—©еҮәзҺ°дәҺ 2.4.4зүҲжң¬дёӯ)з»“еҗҲдҪҝз”Ё пјҢ еҸҜд»Ҙж¶ҲйҷӨдёӨз§Қй«ҳејҖй”Җзҡ„еҶ…еӯҳеӨҚеҲ¶ж“ҚдҪң гҖӮ
- O(1)и°ғеәҰеҷЁ гҖӮиҝҷдёӘе°Ҹж”№иҝӣжңүеҲ©дәҺжңӘжқҘзҡ„е…¶д»–жҖ§иғҪж”№иҝӣ гҖӮO(1)и°ғеәҰеҷЁжҳҜиғҪеӨҹж”№иҝӣеҜ№з§°еӨҡеӨ„зҗҶеҷЁжҖ§иғҪзҡ„еӨҡйҳҹеҲ—и°ғеәҰеҷЁ гҖӮ иҝҷжҳҜ Linux 2.5е’Ң 2.6еҶ…ж ёдёӯзҡ„й»ҳи®Өи°ғеәҰеҷЁ гҖӮ
- еқҮзӯүдәІеҗҲзҡ„ IRQ(evenly affined IRQ) гҖӮ4дёӘзҪ‘з»ңйҖӮй…ҚеҷЁдёӯжҜҸдёӘйҖӮй…ҚеҷЁзҡ„дёӯж–ӯйғҪз”ұе”ҜдёҖзҡ„еӨ„зҗҶеҷЁжқҘеӨ„зҗҶ гҖӮ еңЁ P4дҪ“зі»з»“жһ„дёӯ пјҢ SUSE SLES 8зҡ„ IRQиҮі CPUжҳ е°„жңәеҲ¶й»ҳи®ӨдёәиҪ®иҜўеҲҶй…Қ(destination= irq_num% num_cpus) гҖӮ еңЁзӨәдҫӢдёӯ пјҢ зҪ‘з»ңйҖӮй…ҚеҷЁзҡ„жүҖжңү IRQйғҪиў«иҪ¬иҮі CPU0 гҖӮиҝҷеҜ№дәҺжҖ§иғҪйқһеёёжңүзӣҠ пјҢеӣ дёәиҜҘд»Јз ҒдёҠзҡ„ cacheжҡ–е’ҢжҖ§е·ІиҺ·еҫ—ж”№иҝӣ пјҢдҪҶйҡҸзқҖжӣҙеӨҡNICиў«ж·»еҠ еҲ°зі»з»ҹдёӯ пјҢеҚ•дёӘ CPUеҸҜиғҪйҡҫд»ҘеӨ„зҗҶе…ЁйғЁзҪ‘з»ңиҙҹиҚ· гҖӮ зҗҶжғізҡ„и§ЈеҶіж–№жЎҲжҳҜеқҮеҢҖең°дәІеҗҲиҝҷдәӣ IRQ пјҢдҪҝеҫ—жҜҸдёӘеӨ„зҗҶеҷЁйғҪеӨ„зҗҶжқҘиҮӘдёҖдёӘ NICзҡ„дёӯж–ӯ гҖӮ иҝҷз§ҚжңәеҲ¶дёҺиҝӣзЁӢдәІеҗҲжҖ§з»“еҗҲдҪҝз”Ё пјҢ еә”иҜҘиғҪеӨҹе°ҶжҢҮжҙҫз»ҷжҹҗдёӘзү№е®ҡ NICдёҠзҡ„иҝӣзЁӢд№ҹжҢҮжҙҫеҲ°дёҖдёӘ CPUдёҠ пјҢ д»ҘдҫҝиҺ·еҸ–жңҖй«ҳжҖ§иғҪ гҖӮ
- иҝӣзЁӢдәІеҗҲжҖ§ гҖӮиҜҘжҠҖжңҜзЎ®дҝқеҜ№дәҺжҜҸдёӘиў«еӨ„зҗҶзҡ„зҪ‘з»ңдёӯж–ӯ пјҢ зӣёеә”зҡ„ smbdиҝӣзЁӢйғҪеңЁеҗҢдёҖдёӘ CPUдёҠиў«и°ғеәҰд»ҘдҫҝиҝӣдёҖжӯҘж”№е–„cacheжҡ–е’ҢжҖ§ гҖӮ
- /proc/sys/net/hl=763 гҖӮеўһеҠ зҪ‘з»ңеҚҸи®®ж Ҳд»Јз ҒдёӯжӢҘжңүзҡ„зј“еҶІеҢәж•°йҮҸ пјҢ д»ҺиҖҢдҪҝзҪ‘з»ңж ҲдёҚйңҖи°ғз”ЁеҶ…еӯҳзі»з»ҹжқҘд»ҺдёӯиҺ·еҸ–жҲ–йҮҠж”ҫзј“еҶІеҢә гҖӮLinux 2.6еҶ…ж ёдёӯжңӘжҸҗдҫӣиҝҷдёӘи°ғдјҳзү№жҖ§ гҖӮ
- е®һж–ҪеӨ§е°ҸеҶҷж•Ҹж„ҹзү№жҖ§ гҖӮеҰӮжһңжңӘе®һж–ҪиҝҷдёӘзү№жҖ§ пјҢSambaеңЁжү“ејҖдёҖдёӘж–Ү件еүҚеҸҜиғҪйңҖиҰҒжҗңзҙўиҜҘж–Ү件зҡ„дёҚеҗҢзүҲжң¬еҗҚз§° пјҢеӣ дёәеҗҢдёҖдёӘж–Ү件еҸҜд»ҘжӢҘжңүеӨҡдёӘж–Ү件еҗҚз»„еҗҲ гҖӮ еҗҜеҠЁеӨ§е°ҸеҶҷж•Ҹж„ҹзү№жҖ§е°ұеҸҜд»Ҙж¶ҲйҷӨиҝҷдәӣзҢңжөӢ гҖӮ
- иҮӘж—Ӣй”Ғ(spinlock) гҖӮSambaзҡ„ж•°жҚ®еә“дёӯдҪҝз”ЁдәҶй«ҳејҖй”Җзҡ„ fcntl()и°ғз”Ё гҖӮ еҸҜд»ҘдҪҝз”ЁиҮӘж—Ӣй”ҒжқҘд»ЈжӣҝиҝҷдёӘи°ғз”Ё гҖӮ еҲ©з”ЁеңЁposix_lock_file()дёӯеҸ‘зҺ°зҡ„еӨ§еҶ…ж ёй”Ғ(Big Kernel Lock)еҸҜд»ҘеҮҸе°‘еӨ§еҶ…ж ёй”Ғзҡ„з«һдәүе’Ңзӯүеҫ…ж—¶й—ҙ гҖӮ иҰҒдҪҝз”ЁиҜҘзү№жҖ§ пјҢеҸҜд»ҘйҖҡиҝҮ--use-spin-locksжқҘй…ҚзҪ®Samba пјҢ еҰӮдёӢдҫӢжүҖзӨә гҖӮ Smbd --use-spin-locks -p-O-s
- dcache иҜ»еӨҚеҲ¶жӣҙж–°(read copy update) гҖӮйҖҡиҝҮдҪҝз”ЁиҜ»еӨҚеҲ¶жӣҙж–°жҠҖжңҜ пјҢ дёҖз§Қж–°зҡ„dlookup()е®һзҺ°еҸҜд»ҘеҮҸе°‘зӣ®еҪ•йЎ№жҹҘиҜўж¬Ўж•° гҖӮ иҜ»еӨҚеҲ¶жӣҙж–°жҳҜ Linuxдёӯз”ЁдҪңдә’ж–ҘжңәеҲ¶зҡ„дёҖз§ҚдёӨйҳ¶ж®өжӣҙж–°ж–№жі• пјҢеҸҜд»ҘйҒҝе…ҚиҮӘж—Ӣзӯүеҫ…й”Ғзҡ„ејҖй”Җ гҖӮ жӣҙеӨҡдҝЎжҒҜеҸӮи§Ғ LinuxеҸҜдјёзј©жҖ§з ”究计еҲ’(Linux Scalability Effort)дёӯе…ідәҺй”Ғ(locking)жҠҖжңҜж–№йқўзҡ„е·ҘдҪң гҖӮ
жҺЁиҚҗйҳ…иҜ»
- и°·жӯҢе»әз«Ӣж–°AIзі»з»ҹ еҸҜејҖеҸ‘з”ңе“Ғй…Қж–№
- ж”№еҸҳзҪ‘з»ңеҢ–еҠһе…¬ жҸӯз§ҳеӨҸжҷ®ж–°еӨҚеҗҲжңәзі»еҲ—
- зҪ‘з»ңеҸҢйқўжҸҗйҖҹеҠһе…¬ еӨҸжҷ®еҸ‘еёғе…Ёж–°еӨҚеҚ°жңәзі»еҲ—
- иҜәеҹәдәҡдёәдҪ•е®ҒеҸҜйҖҗжёҗжІЎиҗҪд№ҹдёҚйҮҮз”ЁAndroidзі»з»ҹпјҹй•ҝзҹҘиҜҶдәҶ
- зғҹеҸ°жёҜвҖңз®ЎйҒ“жҷәи„‘зі»з»ҹвҖқдёҠзәҝ еңЁеӣҪеҶ…зҺҮе…Ҳе®һзҺ°еҺҹжІ№еӮЁиҝҗе…ЁжҒҜжҷәиғҪжҺ’дә§
- vivoдёҖж¬ҫж–°жңәзҺ°иә«и·‘еҲҶзҪ‘пјҒиҝҗеӯҳе’Ңзі»з»ҹдҝЎжҒҜйҖҡйҖҡжӣқе…ү
- зҫҺеӘ’пјҡзҫҺеӣҪжӢүе°ҸејҹжҗһејҖж”ҫзҪ‘з»ң规иҢғж‘Ҷи„ұеҚҺдёә дҪҶжӣҙеӨҡдёӯеӣҪе…¬еҸёеҠ е…Ҙз«һдәүжҗ…й»„зҫҺж–№и®ЎеҲ’
- еҚҺдёәдёәжІіеҢ—вҖңзҒ«зңјвҖқе®һйӘҢе®ӨпјҲж°”иҶңзүҲпјүжҸҗдҫӣзҪ‘з»ңжҠҖжңҜдҝқйҡң
- дәәз‘һдәәжүҚ(06919)пјҡжңӘжқҘ3е№ҙзі»з»ҹе№іеҸ°е°ҶеҸ‘еҠӣжҷәиғҪеҢ–пјҢжү“йҖ иҒҢдёҡз”ҹжҖҒй“ҫе№іеҸ°
- ж— зәҝзҪ‘з»ңиҒ”зӣҹпјҡWi-Fi 6EжҳҜдәҢеҚҒе№ҙжқҘжңҖйҮҚеӨ§зҡ„дёҖж¬ЎеҚҮзә§













