Linuxзі»з»ҹзҪ‘з»ңжҖ§иғҪе®һдҫӢеҲҶжһҗ( дәҢ )
Linux дёӯеҜ№ SendFile API зҡ„ж”ҜжҢҒд»ҘеҸҠеңЁ Linux TCP/IP ж Ҳе’ҢзҪ‘з»ңй©ұеҠЁзЁӢеәҸдёӯеҜ№Zerocopyзҡ„ж”ҜжҢҒе®һзҺ°дәҶеңЁ TCP/IP ж•°жҚ®еӨ„зҗҶиҝҮзЁӢдёӯзҡ„еҚ•ж¬ЎеӨҚеҲ¶жңәеҲ¶ гҖӮ SendFileеҜ№дәҺеә”з”ЁзЁӢеәҸжҳҜдёҚйҖҸжҳҺзҡ„ пјҢ еӣ дёәеә”з”ЁзЁӢеәҸйңҖиҰҒе®һзҺ°иҝҷдёӘ APIд»ҘдҫҝеҲ©з”ЁиҜҘзү№жҖ§ гҖӮ 2гҖҒ TCPеҲҶж®өеҚёиҪҪ
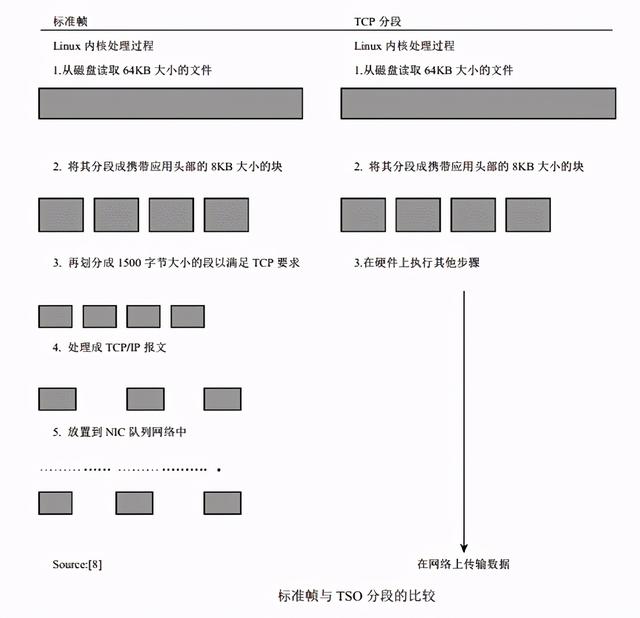
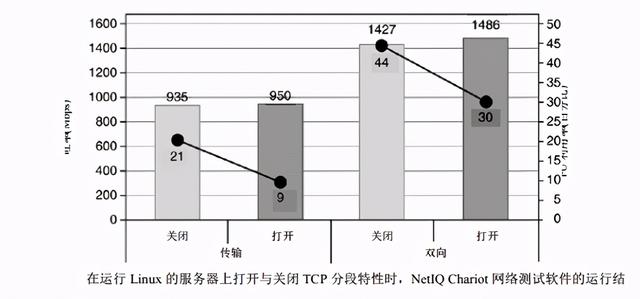
еҜ№дәҺзҪ‘з»ңжҠҘж–Үзҡ„жҜҸж¬Ў TCP/IPдј иҫ“жҲ–жҺҘ收иҝҮзЁӢ пјҢ еҪ“ж•°жҚ®иў«дј иҫ“еҲ° NICжҲ–иҖ…д»Һ NICжҺҘ收时дјҡеҸ‘з”ҹеӨҡж¬Ў PCIжҖ»зәҝи®ҝй—®ж“ҚдҪң гҖӮ йҖҡиҝҮдҪҝз”Ё NICе’Ң Linux TCP/IPж Ҳдёӯзҡ„ TCPеҲҶж®өеҚёиҪҪ(TCPSegmentation Offloading пјҢTSO)зү№жҖ§ пјҢ еҜ№дәҺд»ҘеӨӘзҪ‘иҖҢиЁҖ пјҢ еҸ‘йҖҒз«Ҝзҡ„ PCIжҖ»зәҝи®ҝй—®ж¬Ўж•°еҮҸиҮіеҜ№дәҺжҜҸдёӘ 64KBеӨ§е°Ҹзј“еҶІеҢәи®ҝй—®дёҖж¬ЎиҖҢдёҚжҳҜеҜ№жҜҸдёӘзҪ‘з»ңжҠҘж–Ү(1518B)йғҪи®ҝй—®дёҖж¬Ў гҖӮеҰӮжһңеә”з”ЁзЁӢеәҸжҸҗдҫӣзҡ„зј“еҶІеҢәй•ҝеәҰеӨ§дәҺеё§й•ҝеәҰ пјҢеҲҷ TCP/IPж Ҳе°Ҷе…¶еҲ’еҲҶжҲҗеӨҡдёӘеё§ пјҢ дёә жҜҸдёӘеё§йғҪж·»еҠ дёҖдёӘ TCP/IPеӨҙйғЁ пјҢ 并е°Ҷе…¶йҖҡиҝҮDMAжҳ е°„еҲ° NIC гҖӮеҰӮжһңдҪҝиғҪдәҶ TSOзү№жҖ§ пјҢеҲҷдёә 64KBж•°жҚ®е°ҒиЈ…дёҖдёӘдјӘжҠҘж–ҮеӨҙ пјҢ并йҖҡиҝҮ DMAе°Ҷе…¶еҸ‘йҖҒиҮі NIC гҖӮзҪ‘з»ңйҖӮй…ҚеҷЁзҡ„жҺ§еҲ¶еҷЁе°ҶиҝҷдёӘ 64KBж•°жҚ®еқ—и§ЈжһҗжҲҗж ҮеҮҶзҡ„д»ҘеӨӘзҪ‘жҠҘж–Ү пјҢ д»ҺиҖҢеҮҸе°‘дәҶдё»жңәзҡ„ CPUеҲ©з”ЁзҺҮе’ҢеҜ№ PCIжҖ»зәҝзҡ„и®ҝй—® гҖӮTSOйҖҡиҝҮйҷҚдҪҺ CPUеҲ©з”ЁзҺҮе’ҢжҸҗй«ҳзҪ‘з»ңеҗһеҗҗзҺҮжқҘж”№е–„ж•ҲзҺҮ гҖӮ й’ҲеҜ№иҜҘд»»еҠЎдё“й—Ёи®ҫи®ЎдәҶзҪ‘з»ңиҠҜзүҮ(network silicon) гҖӮ еңЁ Linuxд»ҘеҸҠй’ҲеҜ№ TSOиҖҢи®ҫи®Ўзҡ„Gigabit EthernetиҠҜзүҮдёӯжҝҖжҙ» TSOзү№жҖ§иғҪеӨҹеўһејәзі»з»ҹжҖ§иғҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
3гҖҒ зҪ‘з»ңиҙҹиҚ·дёӯзҡ„иҝӣзЁӢдёҺIRQдәІеҗҲжҖ§дәІеҗҲжҖ§жҲ–з»‘е®ҡзҡ„еҗ«д№үжҳҜжҢҮејәеҲ¶еҸӘеңЁйҖүе®ҡзҡ„дёҖдёӘжҲ–еӨҡдёӘ CPUдёҠжү§иЎҢиҝӣзЁӢдёӯж–ӯзҡ„иҝҮзЁӢ гҖӮ еңЁеӨҡеӨ„зҗҶеҷЁзі»з»ҹдёӯ пјҢ еҹәдәҺж“ҚдҪңзі»з»ҹи°ғеәҰеҷЁдҪҝз”Ёзҡ„зӯ–з•Ҙ пјҢ еңЁзү№е®ҡжқЎд»¶дёӢеҸҜд»Ҙе°ҶдёҖдёӘеӨ„зҗҶеҷЁдёҠзҡ„иҝӣзЁӢиҝҒ移еҲ°е…¶д»–еӨ„зҗҶеҷЁ гҖӮ йҖҡиҝҮе°ҶиҝӣзЁӢдҝқжҢҒеңЁеҗҢдёҖдёӘеӨ„зҗҶеҷЁвҖ”вҖ”иҝҷејәеҲ¶и°ғеәҰеҷЁе°ҶжҹҗдёӘзү№е®ҡд»»еҠЎи°ғеәҰеҲ°жҢҮе®ҡ CPUдёҠвҖ”вҖ”еҸҜд»ҘжһҒеӨ§жҸҗй«ҳжүҖйңҖж•°жҚ®еӯҳеңЁдәҺ cacheдёӯзҡ„жҰӮзҺҮ пјҢ д»ҺиҖҢеҸҜд»ҘеҮҸе°‘еҶ…еӯҳ延иҝҹ гҖӮ жңүдәӣжғ…еҶөдёӢ пјҢ еҚідҪҝиҝӣзЁӢиў«йҷҗе®ҡеңЁеҗҢдёҖдёӘ CPUдёҠи°ғеәҰ пјҢиҜёеҰӮеӨ§еһӢе·ҘдҪңйӣҶд»ҘеҸҠеӨҡиҝӣзЁӢе…ұдә«еҗҢдёҖдёӘ CPUзӯүеӣ зҙ д№ҹеёёеёёеҜјиҮҙжё…з©ә cache пјҢ еӣ жӯӨиҝӣзЁӢдәІеҗҲжҖ§еҸҜиғҪж— жі•еңЁжүҖжңүжғ…еҶөдёӢйғҪиө·дҪңз”Ё гҖӮ жң¬з« з»ҷеҮәзҡ„е®һдҫӢеҲҶжһҗйқһеёёйҖӮдәҺеҲ©з”ЁиҝӣзЁӢдәІеҗҲзү№жҖ§ гҖӮLinuxеҶ…ж ёе®һзҺ°дәҶдёӢеҲ—дёӨдёӘзі»з»ҹи°ғз”Ё пјҢ д»Ҙдҫҝжү§иЎҢиҝӣзЁӢдёҺеӨ„зҗҶеҷЁзҡ„з»‘е®ҡж“ҚдҪңпјҡ
asmlinkage int sys_sched_set_affinity(pid_t pid, unsigned int mask_len,unsigned long *new_mask_ptr);asmlinkage int sys_sched_get_affinity(pid_t pid, unsigned int*user_mask_len_ptr, unsigned long *user_mask_ptr); sched_set_affinity()зі»з»ҹи°ғз”ЁиҝҳзЎ®дҝқеңЁжҒ°еҪ“зҡ„дёҖдёӘжҲ–еӨҡдёӘ CPU дёҠиҝҗиЎҢзӣ®ж ҮиҝӣзЁӢ гҖӮ sched_get_affinity(pid,&mask_len,NULL)еҸҜз”ЁдәҺжҹҘиҜўеҶ…ж ёжүҖж”ҜжҢҒзҡ„ CPUдҪҚеұҸи”Ҫз Ғй•ҝеәҰ гҖӮиҝӣзЁӢдәІеҗҲжҖ§ж„Ҹе‘ізқҖе°ҶиҝӣзЁӢжҲ–зәҝзЁӢз»‘е®ҡеҲ°жҹҗдёӘ CPUдёҠ гҖӮ IRQдәІеҗҲжҖ§ж„Ҹе‘ізқҖејәеҲ¶еңЁжҹҗдёӘзү№е®ҡ CPUдёҠжү§иЎҢе…·дҪ“ IRQзҡ„дёӯж–ӯеӨ„зҗҶ гҖӮ еңЁ LinuxдёӯеҸҜд»ҘдҪҝз”Ё/procжҺҘеҸЈи®ҫзҪ® IRQдәІеҗҲжҖ§ гҖӮ йҖҡиҝҮзЎ®е®ҡ I/OжҺҘеҸЈжүҖз”Ёзҡ„ IRQ пјҢ 然еҗҺдҝ®ж”№иҜҘзү№е®ҡ IRQзҡ„еұҸи”Ҫз Ғ пјҢ еҸҜд»Ҙи®ҫзҪ® IRQдәІеҗҲжҖ§ гҖӮ дҫӢеҰӮ пјҢ д»ҘдёӢе‘Ҫд»Өе°Ҷ IRQ 63и®ҫзҪ®еҲ° CPU 0 пјҢ 并е°Ҷ IRQ 63жүҖз”ҹжҲҗзҡ„дёӯж–ӯеҸ‘йҖҒеҲ° CPU 1дёҠ
echo "1" > /proc/irq/63/smp_affinity иҝӣзЁӢдәІеҗҲжҖ§дёҺIRQдәІеҗҲжҖ§жҳҜж”№иҝӣеә”з”ЁзЁӢеәҸе’Ңзі»з»ҹзҡ„еҗһеҗҗзҺҮеҸҠжү©еұ•жҖ§зҡ„йҖҡз”ЁжҖ§иғҪдјҳеҢ–е®һи·ө гҖӮ иҝҷдәӣж–№жі•йғҪиҰҒжұӮиҜҶеҲ«еҮәдёҖдёӘеә”з”ЁзЁӢеәҸзҡ„жүҖжңүиҝӣзЁӢ并еҜ№е…¶еҠ д»Ҙйҡ”зҰ» пјҢ иҝҳйңҖиҰҒиҜҶеҲ«еҮәдёӯж–ӯд»Ҙдҫҝе°Ҷе…¶жҳ е°„иҮіеә”з”ЁзЁӢеәҸзҡ„иҝӣзЁӢе’ҢиҝҗиЎҢиҝҷдәӣиҝӣзЁӢзҡ„еӨ„зҗҶеҷЁ гҖӮ еӣ жӯӨ пјҢ иҝҷз§ҚвҖң nеҜ№ nвҖқзҡ„жҳ е°„е…ізі»еңЁеӨҚжқӮзҺҜеўғдёӢ并дёҚжҖ»еҸҜиЎҢ гҖӮNetperf3зӨәдҫӢеҲҶжһҗжё…жҷ°иЎЁжҳҺ пјҢ IRQдёҺиҝӣзЁӢдәІеҗҲжҖ§зҡ„еә”з”Ёж”№е–„дәҶLinuxзҪ‘з»ңзҡ„ SMPжү©еұ•жҖ§е’ҢзҪ‘з»ңеҗһеҗҗзҺҮжҖ§иғҪ гҖӮ еңЁиҜҘдҫӢеӯҗдёӯ пјҢ дҪҝз”ЁдәҶ Netperf3зҡ„еӨҡйҖӮй…ҚеҷЁж”ҜжҢҒиғҪеҠӣжқҘжөӢйҮҸзҪ‘з»ңжү©еұ•жҖ§ гҖӮ е®ғеҜ№жҜҸдёӘ NICйғҪеҲӣе»әдёҖдёӘиҝӣзЁӢ пјҢиҜҘиҝӣзЁӢз»‘е®ҡеҲ° 4дёӘ CPUдёӯзҡ„жҹҗдёӘ CPUд»ҘеҸҠжҹҗдёӘ NICдёҠ гҖӮ иҜҘ NICе°Ҷз”ұиҜҘиҝӣзЁӢдҪҝ用并дёҺд№Ӣз»‘е®ҡеҲ°еҗҢдёҖдёӘCPU гҖӮ дёҖдёӘ Netperf3иҝӣзЁӢзҡ„еӨ„зҗҶж“ҚдҪңжҳҜиў«йҡ”зҰ»зҡ„ пјҢ 并且еҜ№жҹҗдёӘ NICжүҖз”ҹжҲҗзҡ„дёӯж–ӯзҡ„жү§иЎҢж“ҚдҪңиў«йҡ”зҰ»еҲ°еҚ•дёӘеӨ„зҗҶеҷЁдёҠ гҖӮ еңЁ Netperf3жңҚеҠЎеҷЁдёҠдҪҝз”Ё TCP_STREAMжөӢиҜ•жқҘе®ҢжҲҗиҝҷдёӘиҝҮзЁӢ гҖӮеңЁжңҚеҠЎеҷЁдёҠ пјҢ иҜҘе·ҘдҪңиҙҹиҚ·иҝӣиЎҢз№ҒйҮҚзҡ„ж•°жҚ®жҺҘ收еӨ„зҗҶж“ҚдҪң пјҢ дјҡдә§з”ҹеӨҡж¬Ўж•°жҚ®жӢ·иҙқж“ҚдҪң(е°Ҷж•°жҚ®д»Һ NICеӨҚеҲ¶еҲ°еҶ…ж ёеҶ…еӯҳдёӯ пјҢ еҶҚд»ҺеҶ…ж ёеҶ…еӯҳдёӯеӨҚеҲ¶еҲ°еә”з”ЁеҶ…еӯҳдёӯ) гҖӮ з»‘е®ҡжңәеҲ¶жҸҗй«ҳдәҶжҖ§иғҪ пјҢ еӣ дёәиҝҷдәӣеӨҚеҲ¶ж“ҚдҪңеңЁеҚ•дёӘеӨ„зҗҶеҷЁдёҠе®ҢжҲҗ пјҢ д»ҺиҖҢж— йңҖе°Ҷж•°жҚ®еҠ иҪҪеҲ°дёӨдёӘдёҚеҗҢзҡ„еӨ„зҗҶеҷЁ cacheдёӯ гҖӮ еҰӮжһңеҗҢж—¶еә”з”ЁиҝҷдёӨдёӘдәІеҗҲжҖ§зҡ„иҜқ пјҢ йӮЈд№Ҳз»‘е®ҡжңәеҲ¶еҸҜд»ҘеҮҸе°‘еҶ…еӯҳ延иҝҹ гҖӮ е°Ҫз®ЎеҸҜд»ҘеҚ•зӢ¬дҪҝз”ЁIRQдәІеҗҲжҖ§жҲ–иҝӣзЁӢдәІеҗҲжҖ§ пјҢ дҪҶз»„еҗҲдҪҝз”Ёж—¶иғҪеӨҹиҝӣдёҖжӯҘжҸҗй«ҳжҖ§иғҪ гҖӮ
жҺЁиҚҗйҳ…иҜ»














- и°·жӯҢе»әз«Ӣж–°AIзі»з»ҹ еҸҜејҖеҸ‘з”ңе“Ғй…Қж–№
- ж”№еҸҳзҪ‘з»ңеҢ–еҠһе…¬ жҸӯз§ҳеӨҸжҷ®ж–°еӨҚеҗҲжңәзі»еҲ—
- зҪ‘з»ңеҸҢйқўжҸҗйҖҹеҠһе…¬ еӨҸжҷ®еҸ‘еёғе…Ёж–°еӨҚеҚ°жңәзі»еҲ—
- иҜәеҹәдәҡдёәдҪ•е®ҒеҸҜйҖҗжёҗжІЎиҗҪд№ҹдёҚйҮҮз”ЁAndroidзі»з»ҹпјҹй•ҝзҹҘиҜҶдәҶ
- зғҹеҸ°жёҜвҖңз®ЎйҒ“жҷәи„‘зі»з»ҹвҖқдёҠзәҝ еңЁеӣҪеҶ…зҺҮе…Ҳе®һзҺ°еҺҹжІ№еӮЁиҝҗе…ЁжҒҜжҷәиғҪжҺ’дә§
- vivoдёҖж¬ҫж–°жңәзҺ°иә«и·‘еҲҶзҪ‘пјҒиҝҗеӯҳе’Ңзі»з»ҹдҝЎжҒҜйҖҡйҖҡжӣқе…ү
- зҫҺеӘ’пјҡзҫҺеӣҪжӢүе°ҸејҹжҗһејҖж”ҫзҪ‘з»ң规иҢғж‘Ҷи„ұеҚҺдёә дҪҶжӣҙеӨҡдёӯеӣҪе…¬еҸёеҠ е…Ҙз«һдәүжҗ…й»„зҫҺж–№и®ЎеҲ’
- еҚҺдёәдёәжІіеҢ—вҖңзҒ«зңјвҖқе®һйӘҢе®ӨпјҲж°”иҶңзүҲпјүжҸҗдҫӣзҪ‘з»ңжҠҖжңҜдҝқйҡң
- дәәз‘һдәәжүҚ(06919)пјҡжңӘжқҘ3е№ҙзі»з»ҹе№іеҸ°е°ҶеҸ‘еҠӣжҷәиғҪеҢ–пјҢжү“йҖ иҒҢдёҡз”ҹжҖҒй“ҫе№іеҸ°
- ж— зәҝзҪ‘з»ңиҒ”зӣҹпјҡWi-Fi 6EжҳҜдәҢеҚҒе№ҙжқҘжңҖйҮҚеӨ§зҡ„дёҖж¬ЎеҚҮзә§