жөӢиҜ„зӣҳзӮ№|RTX 3080йҰ–жөӢпјҡеҚҠд»·иҺ·еҫ—жҜ”дёҠд»Јж——иҲ°ејә30%зҡ„жҖ§иғҪ( дёғ )
е…¶е®һеҰӮжһңе…¬зүҲдёҖеҮә пјҢ еҸҜиғҪе°ұжІЎдәәд№°AICзҡ„еҚЎдәҶ пјҢ жҜ•з«ҹе…¬зүҲиҝҷи®ҫи®Ўе’Ңе”®д»·дј°и®Ўи°ҒйғҪжҠөжҢЎдёҚдҪҸ гҖӮ
NVIDIA Ampereжһ¶жһ„дёҺRTX 30зі»жҳҫеҚЎиҜҰи§ЈпјҡеӨ§е№…жҖ§иғҪжҸҗеҚҮжҳҜжҖҺж ·жқҘзҡ„пјҹ
CUDAж ёеҝғеҶҚж”№ пјҢ е®һзҺ°зҝ»еҖҚCUDAж•°пјҹ
дёүеј жҳҫеҚЎеҸ‘еёғеҗҺ пјҢ еӨ§е®¶жңҖзғӯи®®и®Ёи®әзҡ„еә”иҜҘе°ұжҳҜCUDAж ёеҝғж•°дәҶ пјҢ иҝҳи®°еҫ—еҗҢдәӢжңҖж·ұеҲ»зҡ„дёҖеҸҘж„ҹеҸ№пјҡвҖңжңүз”ҹд№Ӣе№ҙжҲ‘жғізңӢеҲ°CUDAж•°иғҪеҒҡеҲ°дёҖдёҮ пјҢ з»“жһңжІЎжғіеҲ°иҝҷд№Ҳеҝ«е°ұжқҘдәҶ гҖӮ вҖқ
ж–Үз« еӣҫзүҮ
зЎ®е®һ пјҢ RTX 3080иҷҪ然算жҳҜRTX 2080зҡ„еҜ№дҪҚдә§е“Ғ пјҢ дҪҶжҢүе®ҳзҪ‘и§„ж јжқҘзңӢ пјҢ CUDAж•°еҚҙзӣҙжҺҘеӨҡдәҶеҝ«дёӨеҖҚдәҶ пјҢ еҜ№жҜ”RTX 2080 Tiд№ҹеҮ д№Һзҝ»еҖҚ пјҢ иҝҷдёӨе№ҙйҮҢиӢұдјҹиҫҫжҠҖжңҜиҝӣжӯҘеҝ«еҫ—иҝҷд№ҲзҰ»и°ұдәҶеҗ—пјҹ
ж–Үз« еӣҫзүҮ
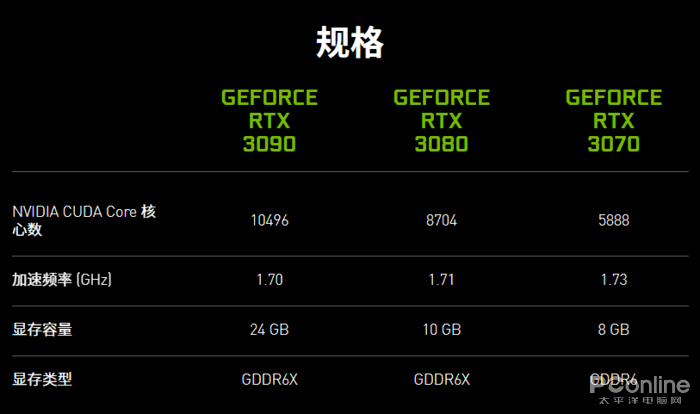
Turingжһ¶жһ„SMеҚ•е…ғзӨәж„Ҹеӣҫ пјҢ еӣҫдёӯFP32еҢәеҹҹжҜҸдёӘе°ҸжЎҶжЎҶ=1дёӘFP32еҚ•е…ғ
е…Ҳи®Іи®ІCUDAжҖҺд№Ҳз®—зҡ„пјҡCUDAж•°=FP32еҚ•е…ғж•° гҖӮ
дёҖзӣҙд»ҘжқҘCUDAж ёеҝғж•°зҡ„и®Ўз®—ж–№ејҸжҳҜдёҖдёӘSMжЁЎеқ—дёӢзҡ„FP32иҝҗз®—еҚ•е…ғдёӘж•° пјҢеңЁжҲ‘们еӣәжңүеҚ°иұЎдёӯ пјҢ INTпјҲж•ҙж•°иҝҗз®—еҚ•е…ғпјүе’ҢFPпјҲжө®зӮ№иҝҗз®—пјүз»„еҗҲжүҚз®—жҳҜдёҖдёӘеӨ„зҗҶеҷЁеҚ•е…ғ пјҢ дҪҶеӣ дёәеӨ§йғЁеҲҶиҝҗз®—жҖ§иғҪпјҲжҜ”еҰӮжёёжҲҸи®Ўз®—пјүдё»иҰҒиҖғеҜҹFP32еҚ•е…ғжҖ§иғҪ пјҢ жүҖд»ҘиҖҒй»„д»ҺFermiжһ¶жһ„ејҖе§Ӣ пјҢ е…¶е®һе°ұзӣҙжҺҘз”ЁFP32еҚ•е…ғ=CUDAж ёеҝғиҝҷж ·зҡ„и®Ўз®—ж–№ејҸ пјҢ жІҝз”ЁиҮід»Ҡ гҖӮ
д»ҘTuringзӨәдҫӢ пјҢ жҜҸSMеҚ•е…ғжңү64дёӘCUDAж ёеҝғ пјҢ зңӢдёҠеӣҫж•°FP32зҡ„ж јеӯҗе°ұиғҪж•°еҮә64дёӘFP32еҚ•е…ғ гҖӮ
ж–Үз« еӣҫзүҮ
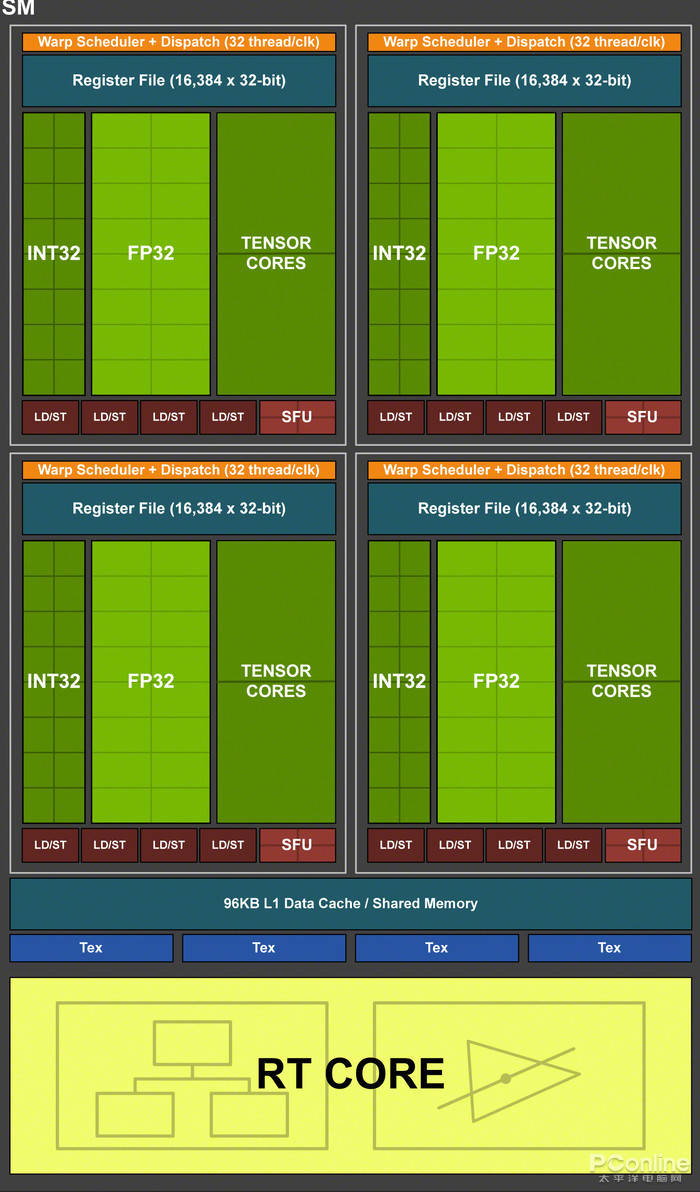
NVIDIA Ampereжһ¶жһ„еӣҫ пјҢ FP32+INT32еҗҢжӯҘиҝҗз®—
иҖҢеҲ°дәҶиҝҷд»ЈNVIDIA Ampereжһ¶жһ„еҗҺ пјҢ еёғеұҖз»“жһ„дёҺTuringжҳҜе·®дёҚеӨҡзҡ„ пјҢ дёӯй—ҙзҡ„дёҖз»„ж•°жҚ®и·Ҝеҫ„дҫқ然жҳҜе…ЁFP32еҚ•е…ғи®ҫи®Ў пјҢ иҖҢе·Ұиҫ№зҡ„ж•°жҚ®и·Ҝеҫ„еҲҷеҸҳжҲҗдәҶвҖңFP32+INT32вҖқ пјҢ еҜ№дәҺж–°SMеҚ•е…ғжҳҜжҖҺд№Ҳе·ҘдҪңзҡ„ пјҢ иӢұдјҹиҫҫеҶ…е®№дёҺжҠҖжңҜеүҜжҖ»иЈҒTony TamasiеңЁRedditдёҠдҪңеҮәдәҶи§ЈйҮҠпјҡ

ж–Үз« еӣҫзүҮ
Tony Tamasiпјҡ
пјҲзәўзәҝйғЁеҲҶпјүдёҖз»„ж•°жҚ®и·Ҝеҫ„еҢ…еҗ«16з»„FP32 CUDAж ёеҝғ пјҢ жҜҸдёӘж—¶й’ҹе‘ЁжңҹеҸҜд»Ҙжү§иЎҢ16жқЎFP32жҢҮд»Өпјӣ
еҸҰдёҖжқЎи·Ҝеҫ„еҢ…еҗ«16дёӘFP32е’Ң16дёӘINT32ж ёеҝғ гҖӮ
еҫ—зӣҠдәҺж–°и®ҫи®Ў пјҢ жҜҸдёӘSMеҚ•е…ғйҮҢзҡ„еҲҶеҢәеҸҜд»ҘйҖүжӢ©еңЁжҜҸдёӘж—¶й’ҹе‘ЁжңҹеҶ…жү§иЎҢ32жқЎFP32жҢҮд»Ө пјҢ жҲ–иҖ…жҳҜ16жқЎFP32+16жқЎINT32жҢҮд»Ө гҖӮ
жҚўз®—дёӢжқҘ пјҢ дёҖдёӘSMеҚ•е…ғеҸҜд»ҘеңЁжҜҸдёӘж—¶й’ҹе‘Ёжңҹжү§иЎҢ128жқЎFP32жҢҮд»Ө пјҢ жҳҜTuringжһ¶жһ„зҡ„дёӨеҖҚ гҖӮ жҲ–иҖ…жҳҜ пјҢ жҜҸдёӘж—¶й’ҹе‘Ёжңҹжү§иЎҢ64жқЎFP32+64жқЎINT32 гҖӮ
ж–Үз« еӣҫзүҮ
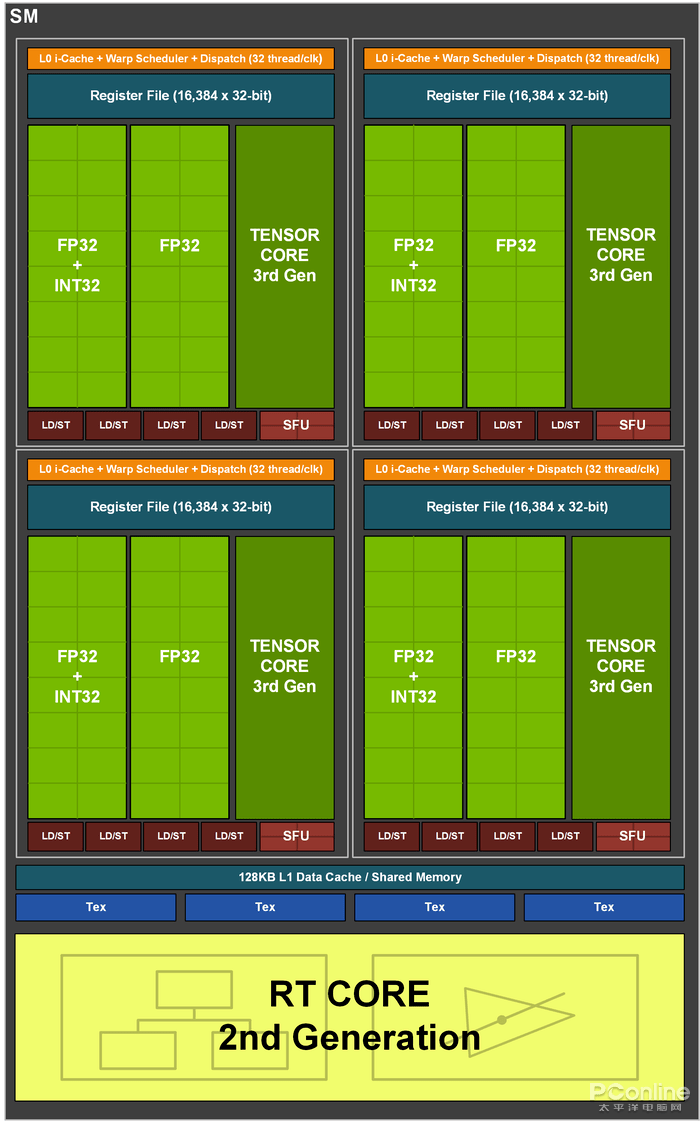
RTX 3080ж ёеҝғзӨәж„Ҹеӣҫ пјҢ жҖ»е…ұ68з»„SMеҚ•е…ғ
128дёӘFP32 пјҢ йӮЈзӣёеҜ№дәҺTuring пјҢ жҜҸдёӘSMеҚ•е…ғзҡ„FP32ж•°йҮҸе°ұжҳҜзҝ»еҖҚдәҶ гҖӮ иҖҢжҢүз…§FP32=CUDAж ёеҝғж•°зҡ„и®Ўз®—ж–№ејҸ пјҢ йӮЈд№ҹзЎ®е®һжІЎй”ҷ пјҢ 68з»„SMеҚ•е…ғxжҜҸеҚ•е…ғ128дёӘFP32=8704 пјҢ е°ұжҳҜе®ҳж–№ж Үз§°зҡ„CUDAж ёеҝғж•°дәҶ гҖӮ
йӮЈд№Ҳ пјҢ CUDAж ёеҝғзҝ»еҖҚ пјҢ жҳҜеҗҰж„Ҹе‘ізқҖжҖ§иғҪзҝ»еҖҚе‘ўпјҹеҰӮжһңзәҜзҗҶи®әFP32и®Ўз®—зҡ„ж—¶еҖҷ пјҢ жҳҜзҡ„ гҖӮ дҪҶеңЁжёёжҲҸдёӯ пјҢ иҷҪ然FP32з”Ёеҫ—еҫҲеӨҡ пјҢ д№ҹжңүеҢ…жӢ¬INTеңЁеҶ…зҡ„еӨҡз§Қиҝҗз®—жғ…еҶө пјҢ еҚҒеҲҶеӨҚжқӮ гҖӮ жүҖд»ҘжёёжҲҸйҮҢдёӨеҖҚжҖ§иғҪжҸҗеҚҮеҮ д№ҺдёҚеҸҜиғҪеӯҳеңЁ гҖӮ

ж–Үз« еӣҫзүҮ
иҜқиҜҙеӣһжқҘ пјҢ еңЁе®ҳзҪ‘дёҠзңӢеҲ°NVIDIA Ampereжһ¶жһ„зҡ„з®Җд»Ӣ пјҢ еҶҷзҡ„жҳҜвҖң2еҖҚFP32еҗһеҗҗйҮҸвҖқ пјҢ иҖҢдёҚжҳҜзӣҙжҺҘж ҮжіЁдёӨеҖҚFP32ж•°йҮҸ пјҢ дј°и®ЎжҳҜиҖғиҷ‘еҲ°зҝ»еҖҚеҸҜиғҪдјҡжӣІи§Јж„ҸжҖқ пјҢ жҜ•з«ҹеҸӘжңүеҚ•зӢ¬и®Ўз®—FP32ж—¶жүҚиғҪжңүзҝ»еҖҚзҡ„жҖ§иғҪ гҖӮ
дёҚиҝҮиҝҷз§ҚFP32зҝ»еҖҚзҡ„и®ҫи®ЎиғҪеӨ§еӨ§жҸҗеҚҮиҝҗз®—ж•ҲзҺҮ пјҢ дё”еңЁе®һйҷ…еә”з”ЁеңәжҷҜдёӯиғҪеңЁдёҚе°‘ең°ж–№дҪ“зҺ°еҮәжқҘ пјҢ д№ҹжҳҜиҝҷж¬ЎNVIDIA Ampereжһ¶жһ„GPUиғҪеӨ§е№…и¶…и¶ҠдёҠд»ЈTuringжһ¶жһ„GPUзҡ„дё»иҰҒеҺҹеӣ гҖӮ
дёүжҳҹе®ҡеҲ¶8nmеҲ¶зЁӢ пјҢ иҠҜзүҮж•ҲиғҪи·ғиҝӣ
иӢұдјҹиҫҫдјјд№ҺеҫҲд№…жІЎжңүжҸҗеҚҮе®ғ们жҳҫеҚЎзҡ„е·ҘиүәжҠҖжңҜдәҶ пјҢ д»ҺPascalзҡ„TSMC 16nm пјҢ еҲ°Turingзҡ„12nm FFNпјҲе…¶е®һз®—жҳҜ16nmзҡ„ж”№иүҜзүҲпјү пјҢ зӣёжҜ”дәҺAMDд»ҺGF 12nmжҸҗеҚҮиҮіTSMC 7nm пјҢ иӢұдјҹиҫҫиҝҷиҫ№зҡ„дә§е“Ғ并没жңүеӨӘеӨ§зҡ„е·ҘиүәжҸҗеҚҮ гҖӮ

ж–Үз« еӣҫзүҮ
иҷҪ然NVIDIA Ampereжһ¶жһ„еҚҮзә§е·ҘиүәжҳҜжқҝдёҠй’үй’үзҡ„дәӢ пјҢ дҪҶиӢұдјҹиҫҫйҰ–е…Ҳз»ҷжҲ‘们ж”ҫдәҶдёӘзғҹйӣҫеј№пјҡ5жңҲд»ҪеҸ‘еёғзҡ„GA100дҪҝз”Ёзҡ„жҳҜTSMC 7nmе·Ҙиүә пјҢ и®©еӨ§е®¶д»ҘдёәRTX 30зі»жҳҫеҚЎдҪҝз”Ёзҡ„жҳҜдёҖж ·зҡ„е·Ҙиүә гҖӮ зӯүеҲ°еҸ‘еёғдјҡ пјҢ еӨ§е®¶жүҚзҹҘйҒ“з”Ёзҡ„жҳҜдёүжҳҹ8nmе·Ҙиүә гҖӮ
иҷҪ然д№ҰйқўдёҠжҳҜдёүжҳҹ8nm пјҢ дҪҶе®һйҷ…дёҠе®ғжҳҜдёүжҳҹ10nmе·Ҙиүәж”№иүҜиҖҢжқҘ гҖӮ

ж–Үз« еӣҫзүҮ
еӣҫжәҗigor's LAB
RTX 3080пјҲGA102пјү628mm2зҡ„иҠҜзүҮе°әеҜёеҶ…еЎһиҝӣдәҶ280дәҝдёӘжҷ¶дҪ“з®Ў пјҢ дёҺд№ӢзӣёжҜ”зҡ„жҳҜдёҠд»Јзҡ„RTX 2080 Ti пјҢ еҲҷжҳҜ754mm2еҶ… пјҢ еҸӘжңү186дәҝдёӘжҷ¶дҪ“з®Ў пјҢ еҜҶеәҰеҮ д№Һзҝ»еҖҚ пјҢ иҖҢеҜ№жҜ”йҮҮз”ЁдәҶTSMC 7nmзҡ„GA100 пјҢ 826mm2зҡ„йқўз§ҜйҮҢеЎһдёӢдәҶ540дәҝдёӘжҷ¶дҪ“з®Ў гҖӮ
жҺЁиҚҗйҳ…иҜ»













- еЈ°йҹі|зӣҳзӮ№2020еҘҪеЈ°йҹідёҖжҚўйЈҺж је°ұиҫ“зҡ„еӯҰе‘ҳ
- жҳҺжҳҹе©ҡ姻|зӣҳзӮ№вҖңжҳҷиҠұдёҖзҺ°вҖқзҡ„е…«еӨ§жёҜе§җеҶ еҶӣпјҢи°ҒжңҖи®©жғӢжғңпјҹ
- жҳҺжҳҹе©ҡ姻|зӣҳзӮ№еЁұд№җеңҲдёӯзҡ„е№ІдәІпјҢеҲҳеҫ·еҚҺз»ҷж”ҜжҢҒпјҢе‘Ёжҳҹй©°з»ҷеҗҚж°”пјҢиҖҢд»–д»ӨдәәдҪңе‘•пјҒ
- и–Үи–ҮзҲұз”өеҪұ|зӣҳзӮ№жҠӣејғеҘіеҸӢзҡ„з”·жҳҺжҳҹпјҢйғ‘дјҠеҒҘгҖҒйғӯеҜҢеҹҺгҖҒе‘Ёжқ°дјҰгҖҒйӮұжіҪгҖҒз”„еӯҗдё№
- з”өи§Ҷ|зӣҳзӮ№еӨ®и§ҶеҘідё»жҢҒдәәдёүдҪҚе…јиў«жҹҘеҠһпјҢжӣҫз»ҸйғҪе…үйІңдә®дёҪпјҢе…¶дёӯеҘ№жңҖжғЁпјҒ
- й»„йҮ‘е‘Ё|еӨ–еӘ’зӣҳзӮ№еҸҢиҠӮй»„йҮ‘е‘ЁпҪңеҰӮжӯӨеӨҡзҡ„дәәиҮӘз”ұж—…иЎҢ е…ЁзҗғвҖңз»қж— д»…жңүвҖқ
- жңқйҳізҫӨдј—|95еҗҺз”·жҳҹеӯҳиҙ§еӨ§зӣҳзӮ№пјҡзҺӢдёҖеҚҡгҖҒе®ӢеЁҒйҫҷеҗ„дёҖеҸҢз”·дё»еү§пјҢдҪ жңҖжңҹеҫ…и°Ғпјҹ
- жөӢиҜ„|дәҡ马йҖҠеә•еұӮз®—жі•д№ӢвҖңжөӢиҜ„жңүиҜқиҜҙвҖқ
- йқ’зқҗ|зҗҶе·ҘеӨ§еӯҰзӣҳзӮ№|е°ұдёҡзҺҮй«ҳгҖҒеӨҮеҸ—иҖғз”ҹйқ’зқҗпјҢзҺӢзүҢдё“дёҡеҗ„жңүдјҳеҠҝпјҒ
- ж—Ҙеү§зӣҳзӮ№|дёүйғЁгҖҠж–—зҪ—гҖӢдҪңе“Ғе–ңж¬ўз”·дё»зҡ„еҘіеӯ©еӯҗдёӯпјҢзҺӢз§Ӣе„ҝжңҖжғЁпјҹе®һеңЁе№¶дёҚжҳҜ