图像中|学习Hinton老爷子的胶囊网络,这有一篇历史回顾与深度解读( 三 )
文章图片
图 5. Dynamic routing between capsules (Sabour et al., 2017)
在高级胶囊中,当该数字出现在图像里,类数字 k 就会有有一个很长的实例化向量。在文章里,一个边缘损失函数被提出,其表达式如下
这里 Tk=1, m+=0.9 并且 m-=0.1,系数为 0.5,总损失就是所有数字胶囊损失函数的总和。
在以上条件下,作者设计了 CapsNet 的初步框架,如图 6 所示。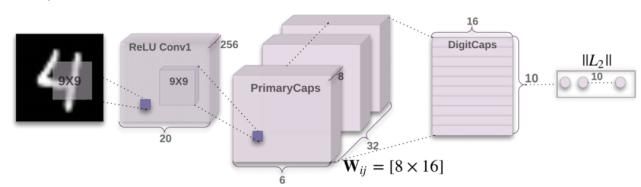
文章图片
图 6. 3 层结构的 CapsNet. 由卷积层和 ReLU 层构成的浅层网络,由卷积层和变换层构成的初级胶囊层和数字胶囊层共同组成 CapsNet(Sabour et al., 2017)。
除此之外,作者还设计了一个译码器来重构输入的数字,这个重构的过程也可以作为模型训练过程中的约束项。其结构如图 7 所示。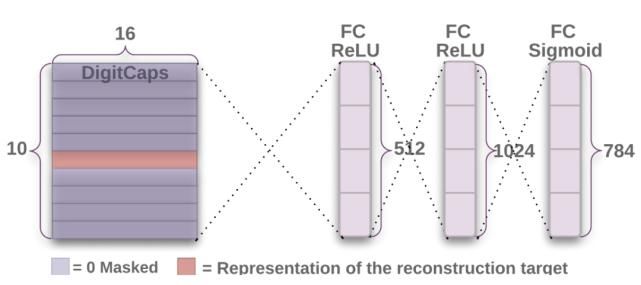
文章图片
图 7. 从数字胶囊层重构图像(Sabour et al., 2017)。
当然,CapsNet 也取得了相当不错的效果。在文章中,作者展示了重构的图像和在 MNIST 数据集上的识别结果可达到 99.23%。我们挑选了部分直观的结果进行展示。
文章图片
图 8. 输入图像与重构图像(Sabour et al., 2017)。
(3) Matrix capsules with EM routing
与使用向量输出不同,Hinton 等人在 2018 年提出用矩阵表示胶囊的输入和输出 [4]。这一想法对减小胶囊之间的变换矩阵大小十分必要。因为使用向量作为输出时可能需要 n*2 个元素,但是用矩阵则只需要 n。这个版本采用期望最大化算法 (Expectation Maximization algorithm) 代替动态路由。
具体来说,胶囊中特征实体存在的概率用参数 a 来替代上一个版本中向量的长度,这有助于避免压缩函数被认为是“不客观或不明智的”。每个胶囊 M 都有一个 4x4 姿态矩阵和激活概率 a, 在 L 层的胶囊 i 和 L+1 层的胶囊 j 之间,胶囊通过一个 4x4 的变换矩阵 Wij 相互连接,变换矩阵只存储参数和进行学习。胶囊 i 的姿态矩阵与变化矩阵点积后得到胶囊 j 的姿态矩阵,可以表示为 Vij=MiWij。在 L+1 层中所有胶囊的姿态和激活概率都通过非线性路由的方法来连接,并更新 Vij 和 ai。这个非线性路由的方法就是文中介绍的 Expectation Maximization algorithm, 它动态的迭代的更新了 L+1 的参数。
下面我们来介绍一下 EM 算法的具体过程,假设我们已经确定了某一层中所有胶囊的姿态矩阵和激活概率 a,现在要决定哪个胶囊激活和连接高一层的胶囊,并且分配每个活动的低级胶囊到一个活动的高级胶囊。每一个高级层中的胶囊对应于高斯分布和低级层中每个活动胶囊 (转换为向量) 对应于一个数据点。在作者运用最小长度原则来描述时,作者做出了一个选择,即在激活某个高级别的胶囊时,使用了一个固定的代价函数用来编码其均值和方差。于是,为了确定 L+1 层中胶囊的姿态矩阵和激活概率,作者在知道 L 层姿态矩阵和激活概率后使用了 3 次迭代的 EM 算法,其伪代码如下图所示。
文章图片
图 9. EM 算法步骤[4]。
在制定了基本方法之后,作者提出了网络的整体框架。模型起始于一个 5x5 且有 32 个通道步长为 2 的卷积层,后面跟着 ReLU 的非线性层。所有的其他层都是初始胶囊层。每个 B=32 姿态矩阵为 4x4 的初级胶囊会从更低的胶囊中学习线性变换。初级胶囊的激活函数是通过应用 sigmoid 函数产生的。在初级胶囊之后是两个 3x3 的卷积胶囊层(K=3),每层 32 胶囊类型(C=D=32),步长分别为 2 和 1。卷积的最后一层胶囊连接到最后的分类胶囊层,每个类别有一个胶囊。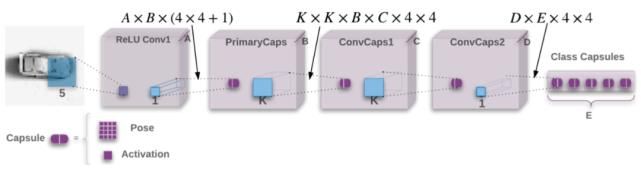
文章图片
图 10. 网络的结构图[4]。
路由算法在每一对相邻的胶囊层之间使用,对于卷积胶囊层,L + 1 层的每个胶囊只向 L 层内其感受域内的胶囊发送反馈。因此,L 层中每个胶囊的卷积实例最多接收到来自 L + 1 层中每个胶囊的卷积核大小的反馈。L 层的边界附近的实例图像接收到的反馈较少,角落的每个胶囊类型只接收到一个反馈。
为了降低训练对模型初始化和超参数的敏感性,网络使用 “扩散损失函数” 来直接最大化目标类(at)和其他类激活之间的差距,这里设置 m=1,其计算方法如下。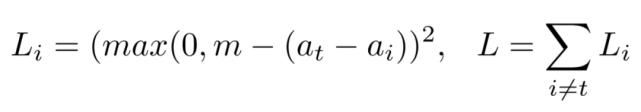
文章图片
作者用了一个数据集 smallNORB 对网络的性能进行了验证,其结果相比 CNN 模型有明显的提高。
文章图片
二:其他作者对胶囊网络的改进
以上的三个版本的胶囊网络均是 Hinton 和他的团队发表的成果。这一章我们介会绍其他几个对于胶囊网络所做的改进。他们分别是:(1) Stacked Capsule Autoencoders; (2) DeepCaps; (3) Visual-textual Capsule Routing。它们分别是发表在 2019 年的 NeurIPS, CVPR 和 2020 年的 CVPR。
推荐阅读















- 学习|王一博带着天天兄弟自驾游,和“以家团”学习露营技能,画面真实
- 260|西海岸新区260家文化经营单位集中学习五大服务规范
- 孩子想到|教育专家张敏:超度学习会让孩子产生厌学心理,玩耍时间是必须的
- Apple|苹果公布新的AI和机器学习培训计划
- 测评|火箭猫定制学AI测评 用权威和专业护航高效学习
- 贾云海|《智慧学习方程式》贾云海:勤学苦练须讲究方式
- |《智慧学习方程式》贾云海:勤学苦练须讲究方式
- | 多地确定开学时间,讯飞智能学习机助力学子实现新逆袭
- 学习|成功通关1065题! 学习达人刘立凡教你如何挑战“学习强国”
- 喜马拉雅|喜马拉雅“91学习季”上线少儿教育频道抢跑新学年