图像中|学习Hinton老爷子的胶囊网络,这有一篇历史回顾与深度解读
机器之心分析师网络
作者:周宇
编辑:H4O
本文对多个版本的胶囊网络进行了详细的介绍。
本文以综述的形式,尽可能详细的向读者介绍胶囊网络的诞生,发展过程与应用前景。本文的内容以 Hinton 的标志性文章为基础,结合近年来发表在顶会顶刊的文章为补充,力图详细的让读者们了解胶囊网络的各种版本,熟悉它在不同领域的革命性突破,以及它在目前所存在的不足。
深度学习和人工神经网络已经被证明在计算机视觉和自然语言处理等领域有很优异的表现,不过随着越来越多相关任务的提出,例如图像识别,物体检测,物体分割和语言翻译等,研究者们仍然需要更多有效的方法来解决其计算量和精度的问题。在已有的深度学习方法中,卷积神经网络 (Convolutional Neural Networks) 是应用最为广泛的一种模型。卷积神经网络通常简称为 CNN,一般的 CNN 模型由卷积层 (convolutional layer), 池化层(pooling layer) 和全连接层 (fully-connected layer) 叠加构成。
在卷积的过程中,卷积层中的卷积核依次与输入图像的像素做卷积运算来自动提取图像中的特征。卷积核的尺寸一般小于图像并且以一定的步长 (stride) 在图像上移动着得到特征图。步长设置的越大,特征图的尺寸就越小,但是过大的步长会损失部分图像中的特征。此外,池化层也通常被作用于产生的特征图上,它能保证 CNN 模型在不同形式的图像中能识别出相同的物体,同时也减少了模型对图像的内存需求,它最大的特点是为 CNN 模型引入了空间不变性(spatial invariance)。
虽然 CNN 模型的提出取得了显著的成果并解决了许多问题,但是它在某些方面还是存在许多缺陷。CNN 最大的缺陷就是它不能从整幅图像和部分图像识别出姿势,纹理和变化。具体来说,由于 CNN 中的池化操作使得模型具有了空间不变性,因此模型就不具备等变(equivariant). 如下图所示,CNN 会把第一和第二幅图都识别为人脸,而把第三幅方向翻转的图识别为不是人脸。另外,池化操作使得特征图丢失了很多信息,它们因此需要更多训练数据来补偿这些损失。就特点上而言,CNN 模型更适合那些像素扰动极大的图像分类,但是对某些不同视角的图像识别能力相对较差。
文章图片
图 1. 识别示意图。图源:https://www.spiria.com/en/blog/artificial-intelligence/deep-learning-capsule-network-revolution/
因此,在 2011 年,Hinton 和他的同事们提出了胶囊网络 (CapsNet) 作为 CNN 模型的替代。胶囊具有等变性并且输入输出都是向量形式的神经元而不是 CNN 模型中的标量值 [1]。胶囊的这种特征表示形式可以允许它识别变化和不同视角。在胶囊网络中,每一个胶囊都由若干神经元组成,而这每个神经元的输出又代表着同一物体的不同属性。这就为识别物体提供了一个巨大的优势,即能通过识别一个物体的部分属性来识别整体。
胶囊的输出通常为某个特征的概率及特性,这个概率和特性通常被叫做实例化参数。而实例化参数代表着网络的等变性,它使得网络能够有效的识别姿势,纹理和变化。比如,如果用 CNN 模型去识别一张脸,模型会将一张眼睛和鼻子位置颠倒的图片识别为人脸,但是,胶囊网络的等变性会保证特征图中位置的信息,因此,具有等变性的胶囊网络会在识别人脸时不仅考虑眼睛鼻子的存在,还会考虑它们的位置。Hinton 首先提出了胶囊网络的基础概念, 然后其余的作者又在此基础上做了其他的改进和应用。接下来的章节,我会对多个版本的胶囊网络进行详细的介绍。
一:胶囊网络的基础概念
(1) Transforming Auto-encoders
文章图片
第一个被发表的胶囊网络即为 Transforming Auto-encoders [2]。它的提出是为了增加网络识别姿态的能力,其主要目标不是在图像中做物体识别,而是从输入图像中提取姿态然后以原始姿态输出变换后的图像。在这篇文章中,向量形式的胶囊首次被提出,其输出的向量既代表特征存在的概率又含有实例化参数。
同时,胶囊也可分为不同的层级:低层 l 的可以叫做初级胶囊,高层 l+1 的可以叫做高层胶囊。低层胶囊从像素中提取姿态参数并且创建一个部分 - 整体的层次结构。这种部分 - 整体的层次结构是胶囊网络的一个优点,通过对其部分的识别,可以得到对整体的识别。要做到这一点,低级别胶囊所代表的特征必须具有正确的空间关系,才能在 l +1 层激活高级别胶囊。例如,让眼睛和嘴巴用较低水平的胶囊表示,如果他们的预测一致的话,一个胶囊代表人脸的高水平胶囊的会被激活,从而模型能做出正确的判断。Hinton 在 2011 年的论文中介绍了这种方法的一个简单例子,如图 2 所示。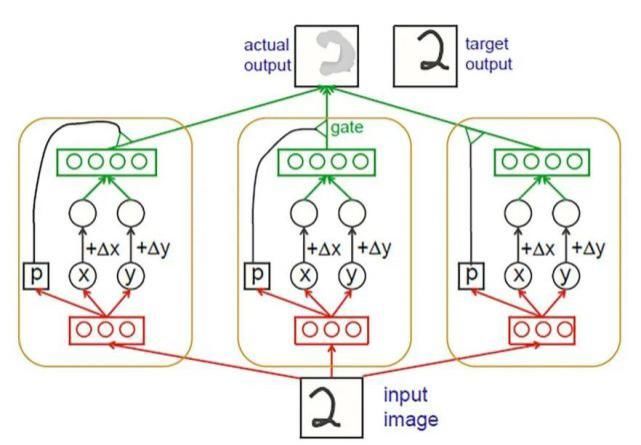
文章图片
图 2. Auto-encoder Capsule structure (Hinton et al., 2011).
作者用一个使用二维图像和输出仅为 x 和 y 胶囊的简单例子来解释这个网络的工作流程。网络一旦确定并且完成学习过程,网络将同时获取一幅图像和所需的位移 Dx 和 Dy,之后网络就可以输出具有指定位移的目标图像。该网络由许多独立的胶囊组成,它们会在最后一层相互融合生成有位移的图像。每个胶囊都有自己的逻辑 “识别单元”(图 2 中的红色部件),作为计算三个数字 x, y, 和 p 的隐藏层,这些被称为“识别单元” 的初级胶囊会将信息送到更高层次胶囊中。
推荐阅读








![[程序员世界]郑州轻工业大学王明杰团队:如何计算永磁直线同步电机的空载磁场](https://imgcdn.toutiaoyule.com/20200409/20200409084245824274a_t.jpeg)






- 学习|王一博带着天天兄弟自驾游,和“以家团”学习露营技能,画面真实
- 260|西海岸新区260家文化经营单位集中学习五大服务规范
- 孩子想到|教育专家张敏:超度学习会让孩子产生厌学心理,玩耍时间是必须的
- Apple|苹果公布新的AI和机器学习培训计划
- 测评|火箭猫定制学AI测评 用权威和专业护航高效学习
- 贾云海|《智慧学习方程式》贾云海:勤学苦练须讲究方式
- |《智慧学习方程式》贾云海:勤学苦练须讲究方式
- | 多地确定开学时间,讯飞智能学习机助力学子实现新逆袭
- 学习|成功通关1065题! 学习达人刘立凡教你如何挑战“学习强国”
- 喜马拉雅|喜马拉雅“91学习季”上线少儿教育频道抢跑新学年