йҡҫдәҺйў„жөӢ|еҪ’еӣ еҲҶжһҗжҢҮеҚ—v1.0( еӣӣ )
з®ҖеҚ•жқҘиҜҙпјҢеҗҢдёҖз»„ж•°жҚ®пјҢж•ҙдҪ“зҡ„и¶ӢеҠҝе’ҢеҲҶз»„еҗҺзҡ„и¶ӢеҠҝе®Ңе…ЁдёҚеҗҢгҖӮд»Һз»ҹи®ЎеӯҰ家зҡ„и§ӮзӮ№жқҘзңӢпјҢеҮәзҺ°иҫӣжҷ®жЈ®жӮ–и®әзҡ„еҺҹеӣ жҳҜеӣ дёәиҝҷдәӣж•°жҚ®дёӯжҪңи—ҸзқҖдёҖдёӘйӯ”й¬јвҖ”вҖ”жҪңеңЁеҸҳйҮҸlurking variableгҖӮ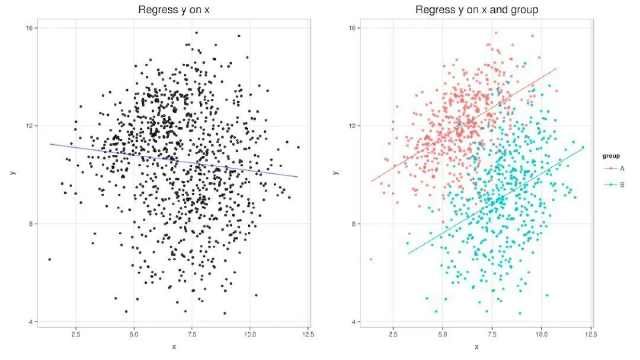
ж–Үз« еӣҫзүҮ
жңҖи‘—еҗҚзҡ„иҫӣжҷ®жЈ®жӮ–и®әзҡ„е®һдҫӢпјҢе°ұжҳҜ1973е№ҙеҠ еҲ©зҰҸе°јдәҡеӨ§еӯҰдјҜе…ӢеҲ©еҲҶж ЎжҖ§еҲ«жӯ§и§ҶжЎҲзҡ„дҫӢеӯҗгҖӮеҰӮжһңеҸӘзңӢж•ҙдҪ“еҪ•еҸ–зҺҮпјҢйӮЈд№Ҳз”·з”ҹзҡ„еҪ•еҸ–зҺҮжҳҜ44%пјҢеҘіз”ҹзҡ„жҳҜ35%гҖӮиҖҢеҰӮжһңжӢҶејҖжқҘзңӢпјҢеңЁ6дёӘйҷўзі»зҡ„4дёӘйҮҢпјҢеҘіз”ҹзҡ„еҪ•еҸ–зҺҮеӨ§дәҺз”·з”ҹгҖӮеҰӮжһңжҢүз…§иҝҷж ·зҡ„еҲҶзұ»пјҢеҘіз”ҹе®һйҷ…дёҠжҜ”з”·з”ҹзҡ„еҪ•еҸ–зҺҮиҝҳй«ҳдёҖзӮ№зӮ№гҖӮеңЁиҝҷдёӘжЎҲдҫӢдёӯпјҢиҫӣжҷ®жЈ®жӮ–и®әеҮәзҺ°зҡ„еҺҹеӣ жҳҜпјҢеҘіз”ҹжӣҙж„ҝж„Ҹз”іиҜ·йӮЈдәӣз«һдәүеҺӢеҠӣеҫҲеӨ§зҡ„йҷўзі»пјҲжҜ”еҰӮиӢұиҜӯзі»пјүпјҢдҪҶжҳҜз”·з”ҹеҚҙжӣҙж„ҝж„Ҹз”іиҜ·йӮЈдәӣзӣёеҜ№е®№жҳ“иҝӣзҡ„йҷўзі»пјҲжҜ”еҰӮе·ҘзЁӢеӯҰзі»пјүгҖӮиҝҷдёҚе°ұжҳҜеҪ’еӣ жүҖиҰҒжҢ–жҺҳзҡ„жҙһи§Ғеҗ—пјҹ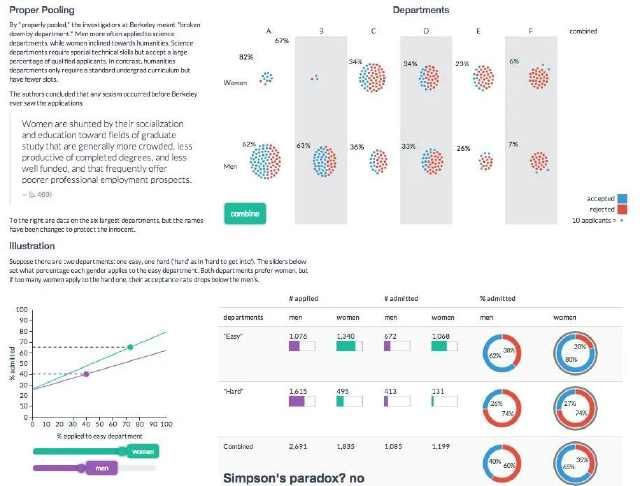
ж–Үз« еӣҫзүҮ
дёҚе°‘з»ҹи®ЎеӯҰ家и®ӨдёәпјҢиҫӣжҷ®жЈ®жӮ–и®әзҡ„еӯҳеңЁпјҢжҸҗйҶ’жҲ‘们дёҚеҸҜиғҪе…үз”Ёз»ҹи®Ўж•°еӯ—жқҘжҺЁеҜјеҮҶзЎ®зҡ„еӣ жһңе…ізі»гҖӮеӣ дёәж•°жҚ®еҸҜд»Ҙз”Ёеҗ„з§Қеҗ„ж ·зҡ„ж–№ејҸеҲҶзұ»пјҢ然еҗҺеҶҚиҝӣиЎҢжҜ”иҫғпјҢжүҖд»ҘзҗҶи®әдёҠжҪңеңЁеҸҳйҮҸж— з©·ж— е°ҪпјҢдҪ жҖ»жҳҜеҸҜд»Ҙз”ЁжҹҗдёӘжҪңеңЁеҸҳйҮҸеҫ—еҲ°жҹҗз§Қз»“и®әгҖӮ
жҲ‘们иғҪеҒҡзҡ„пјҢе°ұжҳҜд»”з»Ҷең°з ”究еҲҶжһҗеҗ„з§ҚеҪұе“Қеӣ зҙ пјҢжҠҠеҗ„з§ҚеҲҶзұ»ж–№ејҸпјҲдёҚеҗҢжЁЎеһӢпјүеҜ№жҜ”з ”з©¶еҲҶжһҗгҖӮ
д»ҘдёҠдёәе…Ёж–ҮпјҢжҖ»з»“дёӢпјҡ
еҪ’еӣ жҳҜжҸҸиҝ°еӣ жһңе…ізі»зҡ„дёҖз§ҚеҲҶжһҗж–№жі•пјҢжҲ‘们йңҖиҰҒжҳҺзЎ®еҪұе“Қеӣ зҙ пјҢеңЁеҪұе“Қеӣ зҙ зҡ„иҢғеӣҙдёӢиҝӣиЎҢеҪ’еӣ еҲҶжһҗгҖӮ
еҗ„дёӘйўҶеҹҹзҡ„еә”з”ЁпјҢйңҖиҰҒз»“еҗҲдёҡеҠЎе…·дҪ“зҡ„жғ…еҶөпјҢи®ҫе®ҡдёҖдәӣеҹәжң¬зҡ„еҒҮи®ҫпјҢдҫӢеҰӮж•°еӯ—иҗҘй”ҖжңүзӮ№еҮ»еҪ’еӣ зӯүжЁЎеһӢпјҢжҠ•иө„еҶізӯ–жңүеҲҶй…ҚгҖҒйҖүжӢ©гҖҒзӣёдә’дҪңз”Ёзҡ„жЁЎеһӢгҖӮ
дә§е“ҒдёҠпјҢдёҚд»…д»…жҳҜеҪ’еӣ пјҢиҝҳиҰҒи§ЈеҶіжҙһеҜҹй—®йўҳгҖӮжҙһеҜҹе®һйҷ…дёҠе°ұжҳҜжңүи¶Јзҡ„з»“и®әпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁжңәеҷЁеӯҰд№ иҮӘеҠЁжҢ–жҺҳеҲ°жңүи¶Јзҡ„з»“и®әпјҲз»“еҗҲжҙһеҜҹеҲҶзұ»пјү
дә§е“ҒжңҖе°Ҹй—ӯзҺҜпјҡеәҰйҮҸ-дјҳеҢ–-и®ЎеҲ’гҖӮ
еҪ’еӣ йҷӨдәҶеҹәдәҺ规еҲҷзҡ„е®һзҺ°пјҢиҝҳжңүжңәеҷЁеӯҰд№ зҡ„е®һзҺ°ж–№ејҸпјҢз§°дёәз®—жі•еҪ’еӣ гҖӮ
еҪ’еӣ д№ҹеҸҜд»Ҙд»Һиҫӣжҷ®жЈ®жӮ–и®әйҮҢиҺ·еҫ—з»“и®әгҖӮ
еҸӮиҖғж–ҮзҢ®пјҡ
https://agencyanalytics.com/blog/marketing-attribution-models
https://zhuanlan.zhihu.com/p/90165817
https://arxiv.org/pdf/1703.01365.pdf
https://www.microsoft.com/en-us/research/uploads/prod/2016/12/Insight-Types-Specification.pdf
https://www.microsoft.com/en-us/research/uploads/prod/2019/05/QuickInsights-camera-ready-final.pdf
зӣёе…ій“ҫжҺҘгҖҒжӣҙеӨҡиө„ж–ҷжҹҘйҳ…
???
гҖҢ Mix+дәәе·ҘжҷәиғҪ гҖҚ дё“еҲҠ
жҜҸжңҹз”ұmixlabзӨҫеҢәзІҫйҖүгҖӮ收еҪ•дәәе·ҘжҷәиғҪзҡ„зӣёе…іеҶ…е®№пјҢеҢ…жӢ¬AIдә§е“ҒгҖҒAIжҠҖжңҜгҖҒAIеңәжҷҜгҖҒAIжҠ•иө„дәӢ件гҖҒAIзҡ„жҖқз»ҙж–№ејҸзӯүпјҢMIXзҡ„дё»йўҳеҢ…жӢ¬пјҡARгҖҒVRгҖҒи®Ўз®—и®ҫи®ЎгҖҒи®Ўз®—е№ҝе‘ҠгҖҒжҷәиғҪи®ҫи®ЎгҖҒжҷәиғҪеҶҷдҪңгҖҒиҷҡжӢҹеҒ¶еғҸзӯүгҖӮ
жҷәиғҪж—¶д»ЈпјҢдәәдёҺдәәд№Ӣй—ҙзҡ„е·®и·қпјҢдҪ“зҺ°еңЁAIдҪҝз”ЁиғҪеҠӣдёҠ
To Be Continued
гҖҗ йҡҫдәҺйў„жөӢ|еҪ’еӣ еҲҶжһҗжҢҮеҚ—v1.0гҖ‘вҖҰвҖҰ
жҺЁиҚҗйҳ…иҜ»


















- иҘҝй—ЁеӯҗжҷәиғҪ家еұ…жҷәиғҪ家еұ…дә§е“Ғ|AWSеҠ©иҘҝй—Ёеӯҗжү“йҖ е…Ёж–°жҷәиғҪ家еұ…зі»з»ҹ 2020жҷәиғҪ家еұ…еёӮеңәз«һдәүж јеұҖеҸҠдҫӣйңҖеҲҶжһҗйў„жөӢ
- OLEDOLEDйқўжқҝеҮәиҙ§йҮҸ|2020е№ҙе…ЁзҗғOLEDеёӮеңәеҸ‘еұ•зҺ°зҠ¶е’ҢдҫӣйңҖеҲҶжһҗйў„жөӢ е…ЁзҗғOLEDйқўжқҝйў„жңҹеҮәиҙ§4.65дәҝзүҮ
- з…§дә®зҒҜе…ү|еҪ©зҘЁжҳҜеҗҰзңҹзҡ„еҸҜд»ҘжҺЁз®—йў„жөӢеҮәжқҘпјҹ
- е°Ҹз•ӘеҒҘеә·|д№ҷиӮқжҒ©жӣҝеҚЎйҹҰ4е№ҙиҜ•йӘҢе’ҢзӢ¬з«Ӣйў„жөӢHCCеӣ еӯҗеҲҶжһҗ
- йҖүжүӢ|еҲӣйҖ иҗҘ2020жҖ»еҶіиөӣпјҢ15ејәйҖүжүӢжңҖз»ҲеӨ§жҺ’еҗҚеӨ§йў„жөӢ
- з”өи§Ҷеү§|гҖҠзҢҺзӢҗгҖӢпјҡжқЁе»әзҫӨзҡ„з»“еұҖжӣқе…үпјҢеӣӣз§Қйў„жөӢе…ЁйғЁзҢңй”ҷ
- 2100е№ҙ|з ”з©¶дәәе‘ҳйў„жөӢ2100е№ҙдё–з•ҢдәәеҸЈ88дәҝ дёӯеӣҪйҷҚиҮі7.3дәҝ
- з ”з©¶дәәе‘ҳйў„жөӢ2100е№ҙдё–з•ҢдәәеҸЈ88дәҝ|з ”з©¶дәәе‘ҳйў„жөӢ2100е№ҙдё–з•ҢдәәеҸЈ88дәҝ жҲ‘еӣҪеӨ„дәҺдәәеҸЈзәўеҲ©дёӢиЎҢжңҹ
- йҮҸеӯҗ|иӢұеӣҪеӣҪйҳІз§‘еӯҰдёҺжҠҖжңҜе®һйӘҢе®Өйў„жөӢйҮҸеӯҗжҠҖжңҜеә”з”ЁеүҚжҷҜ
- еӣӣиҪ®дёҚиҙҘ|иӢұи¶…37иҪ®пјҡжүҳзү№зәіе§ҶзғӯеҲәVSиҺұж–Ҝзү№еҹҺжҜ”еҲҶйў„жөӢ