CV|专访ACL2020最佳论文二作:全新NLP模型评测方法论,思路也适用于CV

文章图片
作者 | 陈大鑫
编辑 | 丛 末
现在,ACL2020各个奖项都已悉数公布,对此AI科技评论做了详细报道。其中,最受人瞩目的当属最佳论文奖,今年该奖项由微软团队的《Beyond Accuracy: Behavioral Testing of NLP Models with CheckList》一举拿下。
小编看到论文题目的第一眼就觉得哪些有些不对,于是赶紧通读了一下文章,嗯~确实不太对,这貌似和之前我们熟悉的NLP“大力出奇迹”的模型套路不太一样啊?
那么这篇论文到底讲了什么呢,又何以摘得桂冠呢?
论文解读以外,我们进一步对论文的第二作者吴彤霜进行了专访,以更深入地了解最佳论文团队背后的工作。
文章图片
1
论文方法一览
我们从论文的题目入手来了解一下这篇论文在讲什么。
首先是"Beyond Accuracy":这是在说要超越Accuracy,这里Accuracy说的是NLP模型在各大数据集和任务上跑出的准确率,也即是性能的一种度量。
那既然要超越它总要有一个理由:
1.评估所用的训练-验证-测试划分集来估计模型的准确性时保留的数据集往往不全面。
2.测试集中往往包含与训练数据相同的偏差,这种方式可能高估了模型在真实世界的性能
3.通过Accuracy一刀切的方式很难找出模型失败在哪里,以及如何修复它。
对此本文提出的Beyond 方式又是如何呢?
Behavioral Testing of NLP Models with CheckList!也即用CheckList对NLP模型做行为测试。
文章图片
上图是论文一作Marco Tulio Ribeiro在大会上做的展示,我们以此展开对CheckList的介绍。
1、We should test NLP models
训练NLP模型的主要目标之一是泛化,虽然Accuracy是评价泛化的主要方法,但它往往高估了NLP模型的性能,用于评估模型的替代方法要么侧重于单个任务,要么侧重于特定的行为,benchmark的准确性不足以评估NLP模型。
除此之外许多额外的评估方法已经被提出来了,例如评估对噪声或对抗性变化的鲁棒性、公平性、逻辑一致性、可解释、诊断数据集和交互式错误分析。然而,这些方法要么侧重于单个任务,如问答或自然语言推理,要么侧重于一些能力(如鲁棒性),因此没有提供关于如何评估模型的全面指导。
因此在这这篇论文中,作者提出了CheckList(检查表),一种新的评估方法和配套工具,用于NLP模型的综合行为测试。
2、Software engineering->NLP
软件工程研究提出了测试复杂软件系统的各种范式和工具。特别是“行为测试”(黑盒测试)是指在不了解内部结构的情况下,通过验证输入输出行为来测试系统的不同能力。虽然有明显的相似之处,但软件工程的许多见解还没有应用到NLP模型中。
作者借鉴软件工程中行为测试的原理提出了CheckList:一种和模型、任务都无关的测试方法,它使用三种不同的测试类型来测试模型的各个功能。
作者用三个任务的测试来说明检查表的效用,识别商业和SOTA模型中的关键错误。在一项用户研究中,一个负责商业情绪分析模型的团队在一个经过广泛测试的模型中发现了新的、可操作的bug。在另一个用户研究中,使用CheckList的NLP实践者创建了两倍多的测试,发现的bug几乎是没有检查表的用户的三倍。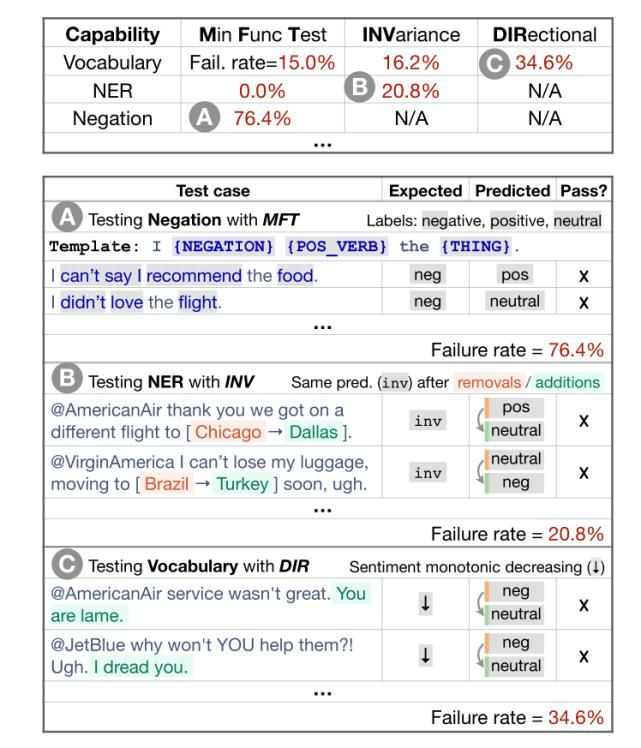
文章图片
图1
3、What is CheckList
CheckList包括一个通用语言能力和测试类型的矩阵,有助于全面的测试构思,以及一个快速生成大量不同测试用例的软件工具。从概念上讲,用户通过填写矩阵中的单元格来“检查”模型(图1),每个单元格可能包含多个测试。CheckList应用了“测试与实现脱钩”的行为测试原则,即将模型视为一个黑盒,允许对不同数据上训练的不同模型进行比较,或者对不允许访问训练数据或模型结构的第三方模型进行比较。
4、What to test:capabilities
CheckList通过提供适用于大多数任务的语言能力列表,指导用户测试什么。CheckList引入了不同的测试类型,比如在某些干扰下的预测不变性,或者一组“健全性检查”的性能。
虽然测试单个组件是软件工程中的常见实践,但现代NLP模型很少一次只构建一个组件。相反,CheckList鼓励用户考虑如何在手头的任务上表现出不同的自然语言能力,并创建测试来评估这些能力的模型。例如,词汇+POS能力取决于一个模型是否具有必要的词汇,以及它是否能够恰当地处理具有不同词性的单词对任务的影响。对于情绪,我们可能需要检查模型是否能够识别带有积极、消极或中性情绪的单词,方法是验证它在“这是一次很好的飞行”等示例上的行为。
基于此,作者建议用户至少考虑以下性能(capabilities):
词汇+POS(任务的重要单词或单词类型)
Taxonomy(同义词、反义词等)
健壮性(对拼写错误、无关更改等)
NER(正确理解命名实体)
推荐阅读

















- 八达岭长城|3.25万!今起八达岭长城单日最佳承载量上调
- 许光汉|许光汉和老狼先后到访蘑菇屋,本该是满屏尬聊,结果却是四季最佳
- 龚|专访龚永泽:成都烟火气 让经济更有活力
- 现场|Sunnee杨芸晴大型打脸&翻车现场|由你专访彩蛋
- 土星|明天是土星冲日最佳赏期
- 河神|专访《河神2》监制汪启楠:换代,用商业大片的要求制作网剧
- 张明汉|复读是一种选择,更是一种态度------专访广外中高考培训项目负责人张明汉
- 石家庄|2020年新高考对复读生的影响-----专访河北明进复读学校杨校长
- 于落寞中前行——专访诗人赫赫扬扬|于落寞中前行——专访诗人赫赫扬扬
- 新星|厉害了!女排21岁天才新星强势崛起,已成朱婷在老东家的最佳替身