梯度下降算法中求J(θ)的最小值时,θ0(常数项)的值怎样确定
在求θ0的梯度时,θ0是变量,而不是字面上常参数的意思。
所有的θ事实上在这个梯度下降(任何最优化方法)的过程中都应该作为变量,求某个θ的偏导时,别的θ可看做常数。相反X0,X1,X2虽然平时都约定看作变量,而此时由于数据对<X,Y>是已知的,他们现在都应该作为常量帮助对各个θ求导。
更具体一点吧
【梯度下降算法中求J(θ)的最小值时,θ0(常数项)的值怎样确定】
平方损失函数
确定
就是在梯度下降法中一次次去迭代
是学习率, 是已知的,那就是要求
,把
以外的都来看成常数
整理后求
的导数
迭代公式就是
■网友
和其他参数一样,求梯度逐步求得。每一次训练都要对所有参数求梯度。然后根据梯度大小更新参数梯度越大更新幅度越大,梯度越小更新幅度越小。
■网友
■网友
先人为给定一个初值,然后迭代更新,直到收敛,此时便确定了
■网友
这个问题暂时没什么理论上的分析……
推荐阅读



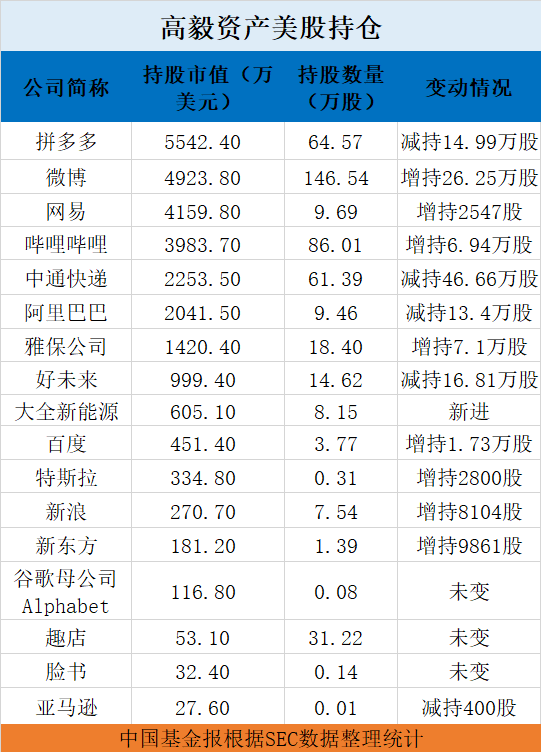












- 山东PM2.5年平均浓度五年下降37%累计淘汰燃煤小锅炉4.1万余台
- 北京发布寒潮蓝色预警:最低气温下降8℃以上
- 汽车知识|配置增加价格下降,2021款奥迪Q7上市,低配性价比高!
- 为啥这个算法误差的看起来这么小
- 使用算法帮助人们筛选reader的信息是否存在可能
- 请问如果想成为算法工程师的话,大学选专业是选软件工程好还是计算机科学与技术好。
- 神经网络算法是否真的属于人工智能范畴
- 以算法为例,是否存在讲解者认为“懂得自然懂了,不懂的我说再多也白搭”的心理
- 豆瓣FM的推荐算法还有哪些可以改进的地方
- 如果已确定图像中物体的位置, 常用的目标分割和提取算法有哪些