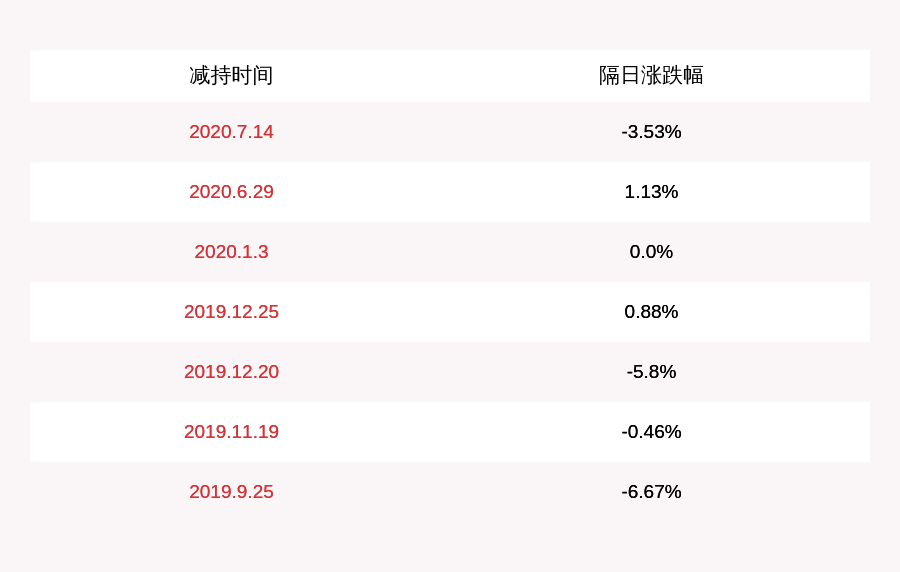
дёҖжҸҗеҲ°е…ізі»еһӢж•°жҚ®еә“пјҢжҲ‘зҰҒдёҚдҪҸжғіпјҡжңүдәӣдёңиҘҝиў«еҝҪи§ҶдәҶ гҖӮе…ізі»еһӢж•°жҚ®еә“ж— еӨ„дёҚеңЁпјҢиҖҢдё”з§Қзұ»з№ҒеӨҡпјҢд»Һе°Ҹе·§е®һз”Ёзҡ„ SQLite еҲ°ејәеӨ§зҡ„ TeradataгҖӮдҪҶеҫҲе°‘жңүж–Үз« и®Іи§Јж•°жҚ®еә“жҳҜеҰӮдҪ•е·ҘдҪңзҡ„ гҖӮдҪ еҸҜд»ҘиҮӘе·ұи°·жӯҢ/зҷҫеәҰдёҖдёӢгҖҺе…ізі»еһӢж•°жҚ®еә“еҺҹзҗҶгҖҸпјҢзңӢзңӢз»“жһңеӨҡд№Ҳзҡ„зЁҖе°‘пјҢиҖҢдё”жүҫеҲ°зҡ„йӮЈдәӣж–Үз« йғҪеҫҲзҹӯ гҖӮзҺ°еңЁеҰӮжһңдҪ жҹҘжүҫжңҖиҝ‘ж—¶й«Ұзҡ„жҠҖжңҜпјҲеӨ§ж•°жҚ®гҖҒNoSQLжҲ–JAVAScriptпјүпјҢдҪ иғҪжүҫеҲ°жӣҙеӨҡж·ұе…ҘжҺўи®Ёе®ғ们еҰӮдҪ•е·ҘдҪңзҡ„ж–Үз« гҖӮйҡҫйҒ“е…ізі»еһӢж•°жҚ®еә“е·Із»ҸеӨӘеҸӨиҖҒеӨӘж— и¶ЈпјҢйҷӨдәҶеӨ§еӯҰж•ҷжқҗгҖҒз ”з©¶ж–ҮзҢ®е’Ңд№ҰзұҚд»ҘеӨ–пјҢжІЎдәәж„ҝж„Ҹи®ІдәҶеҗ—пјҹ

ж–Үз« жҸ’еӣҫ
дҪңдёәдёҖдёӘејҖеҸ‘дәәе‘ҳпјҢжҲ‘дёҚе–ңж¬ўз”ЁжҲ‘дёҚжҳҺзҷҪзҡ„дёңиҘҝ гҖӮиҖҢдё”пјҢж•°жҚ®еә“е·Із»ҸдҪҝз”ЁдәҶ40е№ҙд№Ӣд№…пјҢдёҖе®ҡжңүзҗҶз”ұзҡ„ гҖӮеӨҡе№ҙд»ҘжқҘпјҢжҲ‘иҠұдәҶжҲҗзҷҫдёҠеҚғдёӘе°Ҹж—¶жқҘзңҹжӯЈйўҶдјҡиҝҷдәӣжҲ‘жҜҸеӨ©йғҪеңЁз”Ёзҡ„гҖҒеҸӨжҖӘзҡ„й»‘зӣ’еӯҗ гҖӮе…ізі»еһӢж•°жҚ®еә“йқһеёёжңүи¶ЈпјҢеӣ дёәе®ғ们жҳҜеҹәдәҺе®һз”ЁиҖҢдё”еҸҜеӨҚз”Ёзҡ„жҰӮеҝө гҖӮеҰӮжһңдҪ еҜ№дәҶи§ЈдёҖдёӘж•°жҚ®еә“ж„ҹе…ҙи¶ЈпјҢдҪҶжҳҜд»ҺжңӘжңүж—¶й—ҙжҲ–ж„Ҹж„ҝжқҘеҲ»иӢҰй’»з ”иҝҷдёӘеҶ…е®№е№ҝжіӣзҡ„иҜҫйўҳпјҢдҪ еә”иҜҘе–ңж¬ўиҝҷзҜҮж–Үз« гҖӮ
иҷҪ然жң¬ж–Үж ҮйўҳеҫҲжҳҺзЎ®пјҢдҪҶжҲ‘зҡ„зӣ®зҡ„并дёҚжҳҜи®ІеҰӮдҪ•дҪҝз”Ёж•°жҚ®еә“ гҖӮеӣ жӯӨпјҢдҪ еә”иҜҘе·Із»ҸжҺҢжҸЎжҖҺд№ҲеҶҷдёҖдёӘз®ҖеҚ•зҡ„ join queryпјҲиҒ”жҺҘжҹҘиҜўпјүе’ҢCRUDж“ҚдҪңпјҲеҲӣе»әиҜ»еҸ–жӣҙж–°еҲ йҷӨпјүпјҢеҗҰеҲҷдҪ еҸҜиғҪж— жі•зҗҶи§Јжң¬ж–Ү гҖӮиҝҷжҳҜе”ҜдёҖйңҖиҰҒдҪ дәҶи§Јзҡ„пјҢе…¶д»–зҡ„з”ұжҲ‘жқҘи®Іи§Ј гҖӮ
жҲ‘дјҡд»ҺдёҖдәӣи®Ўз®—жңә科еӯҰж–№йқўзҡ„зҹҘиҜҶи°Ҳиө·пјҢжҜ”еҰӮж—¶й—ҙеӨҚжқӮеәҰ гҖӮжҲ‘зҹҘйҒ“жңүдәӣдәәи®ЁеҺҢиҝҷдёӘжҰӮеҝөпјҢдҪҶжҳҜжІЎжңүе®ғдҪ е°ұдёҚиғҪзҗҶи§Јж•°жҚ®еә“еҶ…йғЁзҡ„е·§еҰҷд№ӢеӨ„ гҖӮз”ұдәҺиҝҷжҳҜдёӘеҫҲеӨ§зҡ„иҜқйўҳпјҢжҲ‘е°ҶйӣҶдёӯжҺўи®ЁжҲ‘и®Өдёәеҝ…иҰҒзҡ„еҶ…е®№пјҡж•°жҚ®еә“еӨ„зҗҶSQLжҹҘиҜўзҡ„ж–№ејҸ гҖӮжҲ‘д»…д»…д»Ӣз»Қж•°жҚ®еә“иғҢеҗҺзҡ„еҹәжң¬жҰӮеҝөпјҢд»ҘдҫҝеңЁиҜ»е®Ңжң¬ж–ҮеҗҺдҪ дјҡеҜ№еә•еұӮеҲ°еә•еҸ‘з”ҹдәҶд»Җд№ҲжңүдёӘеҫҲеҘҪзҡ„дәҶи§Ј гҖӮ
пјҲе…ідәҺж—¶й—ҙеӨҚжқӮеәҰ гҖӮи®Ўз®—жңә科еӯҰдёӯпјҢз®—жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜдёҖдёӘеҮҪж•°пјҢе®ғе®ҡйҮҸжҸҸиҝ°дәҶиҜҘз®—жі•зҡ„иҝҗиЎҢж—¶й—ҙ гҖӮеҰӮжһңдёҚдәҶи§ЈиҝҷдёӘжҰӮеҝөе»әи®®е…ҲзңӢзңӢз»ҙеҹәжҲ–зҷҫеәҰзҷҫ科пјҢеҜ№дәҺзҗҶи§Јж–Үз« дёӢйқўзҡ„еҶ…е®№еҫҲжңүеё®еҠ©пјү
з”ұдәҺжң¬ж–ҮжҳҜдёӘй•ҝзҜҮжҠҖжңҜж–Үз« пјҢж¶үеҸҠеҲ°еҫҲеӨҡз®—жі•е’Ңж•°жҚ®з»“жһ„зҹҘиҜҶпјҢдҪ е°ҪеҸҜд»Ҙж…ўж…ўиҜ» гҖӮжңүдәӣжҰӮеҝөжҜ”иҫғйҡҫжҮӮпјҢдҪ еҸҜд»Ҙи·іиҝҮпјҢдёҚеҪұе“ҚзҗҶи§Јж•ҙдҪ“еҶ…е®№ гҖӮ
иҝҷзҜҮж–Үз« еӨ§зәҰеҲҶдёә3дёӘйғЁеҲҶпјҡ
- еә•еұӮе’ҢдёҠеұӮж•°жҚ®еә“组件жҰӮеҶө
- жҹҘиҜўдјҳеҢ–иҝҮзЁӢжҰӮеҶө
- дәӢеҠЎе’Ңзј“еҶІжұ з®ЎзҗҶжҰӮеҶө
еңЁиҝҷдёҖйғЁеҲҶпјҢжҲ‘е°ҶжҸҗйҶ’еӨ§е®¶дёҖдәӣиҝҷзұ»зҡ„жҰӮеҝөпјҢеӣ дёәе®ғ们еҜ№зҗҶи§Јж•°жҚ®еә“иҮіе…ійҮҚиҰҒ гҖӮжҲ‘иҝҳдјҡд»Ӣз»Қж•°жҚ®еә“зҙўеј•зҡ„жҰӮеҝө гҖӮ
O(1) vs O(n^2)
зҺ°д»ҠеҫҲеӨҡејҖеҸ‘иҖ…дёҚе…іеҝғж—¶й—ҙеӨҚжқӮеәҰ……他们жҳҜеҜ№зҡ„ гҖӮ
дҪҶжҳҜеҪ“дҪ еә”еҜ№еӨ§йҮҸзҡ„ж•°жҚ®пјҲжҲ‘иҜҙзҡ„еҸҜдёҚеҸӘжҳҜжҲҗеҚғдёҠдёҮе“ҲпјүжҲ–иҖ…дҪ иҰҒдәүеҸ–жҜ«з§’зә§ж“ҚдҪңпјҢйӮЈд№ҲзҗҶи§ЈиҝҷдёӘжҰӮеҝөе°ұеҫҲе…ій”®дәҶ гҖӮиҖҢдё”дҪ зҢңжҖҺд№ҲзқҖпјҢж•°жҚ®еә“иҰҒеҗҢж—¶еӨ„зҗҶиҝҷдёӨз§Қжғ…жҷҜпјҒжҲ‘дёҚдјҡеҚ з”ЁдҪ еӨӘй•ҝж—¶й—ҙпјҢеҸӘиҰҒдҪ иғҪжҳҺзҷҪиҝҷдёҖзӮ№е°ұеӨҹдәҶ гҖӮиҝҷдёӘжҰӮеҝөеңЁдёӢж–Үдјҡеё®еҠ©жҲ‘们зҗҶи§Јд»Җд№ҲжҳҜеҹәдәҺжҲҗжң¬зҡ„дјҳеҢ– гҖӮ
жҰӮеҝө
ж—¶й—ҙеӨҚжқӮеәҰз”ЁжқҘжЈҖйӘҢжҹҗдёӘз®—жі•еӨ„зҗҶдёҖе®ҡйҮҸзҡ„ж•°жҚ®иҰҒиҠұеӨҡй•ҝж—¶й—ҙ гҖӮдёәдәҶжҸҸиҝ°иҝҷдёӘеӨҚжқӮеәҰпјҢи®Ўз®—жңә科еӯҰ家дҪҝз”Ёж•°еӯҰдёҠзҡ„гҖҺз®ҖжҳҺи§ЈйҮҠз®—жі•дёӯзҡ„еӨ§Oз¬ҰеҸ·гҖҸ гҖӮиҝҷдёӘиЎЁзӨәжі•з”ЁдёҖдёӘеҮҪж•°жқҘжҸҸиҝ°з®—жі•еӨ„зҗҶз»ҷе®ҡзҡ„ж•°жҚ®йңҖиҰҒеӨҡе°‘ж¬Ўиҝҗз®— гҖӮ
жҜ”еҰӮпјҢеҪ“жҲ‘иҜҙгҖҺиҝҷдёӘз®—жі•жҳҜйҖӮз”Ё O(жҹҗеҮҪж•°())гҖҸпјҢжҲ‘зҡ„ж„ҸжҖқжҳҜеҜ№дәҺжҹҗдәӣж•°жҚ®пјҢиҝҷдёӘз®—жі•йңҖиҰҒ жҹҗеҮҪж•°(ж•°жҚ®йҮҸ) ж¬Ўиҝҗз®—жқҘе®ҢжҲҗ гҖӮ
йҮҚиҰҒзҡ„дёҚжҳҜж•°жҚ®йҮҸпјҢиҖҢжҳҜеҪ“ж•°жҚ®йҮҸеўһеҠ ж—¶иҝҗз®—еҰӮдҪ•еўһеҠ гҖӮж—¶й—ҙеӨҚжқӮеәҰдёҚдјҡз»ҷеҮәзЎ®еҲҮзҡ„иҝҗз®—ж¬Ўж•°пјҢдҪҶжҳҜз»ҷеҮәзҡ„жҳҜдёҖз§ҚзҗҶеҝө гҖӮ

ж–Үз« жҸ’еӣҫ
еӣҫдёӯеҸҜд»ҘзңӢеҲ°дёҚеҗҢзұ»еһӢзҡ„еӨҚжқӮеәҰзҡ„жј”еҸҳиҝҮзЁӢпјҢжҲ‘з”ЁдәҶеҜ№ж•°е°әжқҘе»әиҝҷдёӘеӣҫ гҖӮе…·дҪ“зӮ№е„ҝиҜҙпјҢж•°жҚ®йҮҸд»ҘеҫҲеҝ«зҡ„йҖҹеәҰд»Һ1жқЎеўһй•ҝеҲ°10дәҝжқЎ гҖӮжҲ‘们еҸҜеҫ—еҲ°еҰӮдёӢз»“и®әпјҡ
- з»ҝпјҡO(1)жҲ–иҖ…еҸ«еёёж•°йҳ¶еӨҚжқӮеәҰпјҢдҝқжҢҒдёәеёёж•°пјҲиҰҒдёҚдәә家е°ұдёҚдјҡеҸ«еёёж•°йҳ¶еӨҚжқӮеәҰдәҶпјү гҖӮ
- зәўпјҡO(log(n))еҜ№ж•°йҳ¶еӨҚжқӮеәҰпјҢеҚідҪҝеңЁеҚҒдәҝзә§ж•°жҚ®йҮҸж—¶д№ҹеҫҲдҪҺ гҖӮ
- зІүпјҡжңҖзіҹзі•зҡ„еӨҚжқӮеәҰжҳҜ O(n^2)пјҢе№іж–№йҳ¶еӨҚжқӮеәҰпјҢиҝҗз®—ж•°еҝ«йҖҹиҶЁиғҖ гҖӮ
- й»‘е’Ңи“қпјҡеҸҰеӨ–дёӨз§ҚеӨҚжқӮеәҰпјҲзҡ„иҝҗз®—ж•°д№ҹжҳҜпјүеҝ«йҖҹеўһй•ҝ гҖӮ
ж•°жҚ®йҮҸдҪҺж—¶пјҢO(1) е’Ң O(n^2)зҡ„еҢәеҲ«еҸҜд»ҘеҝҪз•ҘдёҚи®Ў гҖӮжҜ”еҰӮпјҢдҪ жңүдёӘз®—жі•иҰҒеӨ„зҗҶ2000жқЎе…ғзҙ гҖӮ
- O(1) з®—жі•дјҡж¶ҲиҖ— 1 ж¬Ўиҝҗз®—
- O(log(n)) з®—жі•дјҡж¶ҲиҖ— 7 ж¬Ўиҝҗз®—
жҺЁиҚҗйҳ…иҜ»
- еҰӮдҪ•жҢ‘йҖүй»‘иұҶ
- дёҚжҳҜеӨ«еҰ»еҗҲз§ҹжҲҝзҠҜзҪӘеҗ—
- еҢ»дҝқж–ӯзјҙдёүдёӘжңҲдҪҷйўқжё…йӣ¶пјҹе‘ҳе·ҘеҸҜиҮӘж„ҝж”ҫејғзӨҫдҝқпјҹиҝҷдәӣи°ЈиЁҖеҲ«еҶҚдҝЎдәҶ
- жүӢдёІйў—ж•°еӨ§жңү讲究пјҢеҚғдёҮеҲ«жҲҙй”ҷдәҶ
- вҖңзҰҒжӯўй•ҝж—¶й—ҙеҒңиҪҰвҖқпјҢеҲ°еә•жҢҮзҡ„жҳҜеҮ еҲҶй’ҹпјҹдәӨиӯҰпјҡжңҖеҗҺеҶҚиҜҙдёҖйҒҚ
- еӨӘзғӯдәҶпјҒеҲ«еҶҚжҠ«еӨҙж•ЈеҸ‘дәҶпјҢиҝҷ4ж¬ҫеҸ‘еһӢеӨҹзҫҺеӨҹжё…еҮү
- жІЎй’ұиҝҳдҝЎз”ЁеҚЎжңүд»Җд№Ҳи§ЈеҶіеҠһжі•
- дҝЎз”ЁеҚЎиҝҮжңҹеҚЎжҖҺд№ҲеӨ„зҗҶ
- дҝЎз”ЁеҚЎйҖҫжңҹиў«жіЁй”ҖжҖҺд№Ҳиҝҳй’ұ
- еҰӮдҪ•жүҫеӣһжҠ–йҹіз§ҒиҒҠи®°еҪ•