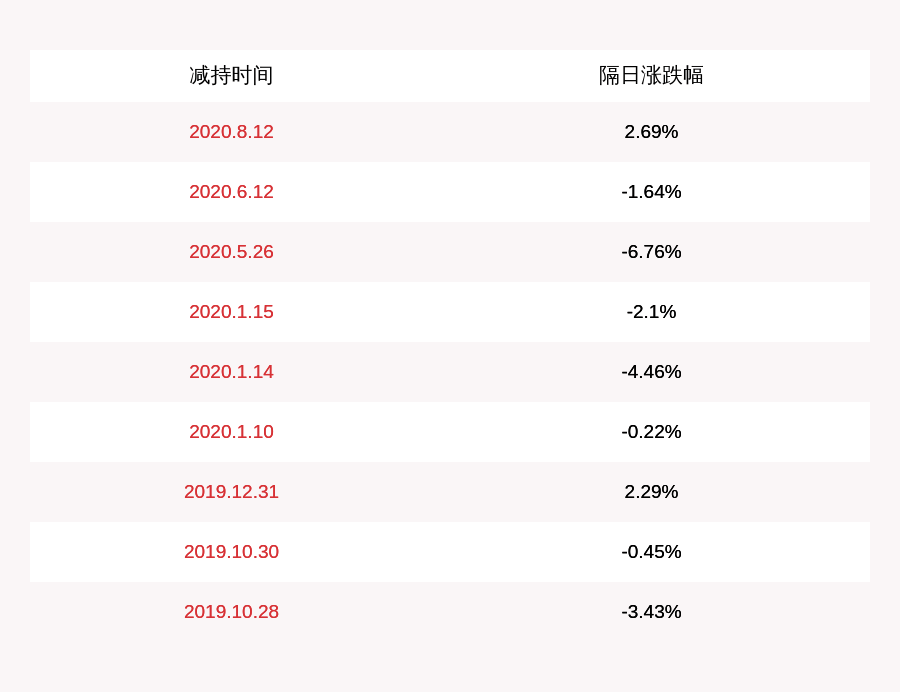
PythonжңүдёӘеӨ„зҗҶеӨ§ж•°жҚ®зҡ„еә“пјҢз»“еҗҲxlrdеә“пјҢеңЁеҒҡдёҖдәӣеӨ§ж•°жҚ®зҡ„еӨ„зҗҶз»ҹи®Ўе·ҘдҪңзҡ„ж—¶еҖҷеҫҲеҘҪз”ЁпјҢиӯ¬еҰӮеҒҡжҖ§иғҪжөӢиҜ•пјҢдҪ зҡ„з»“жһңж•°жҚ®еҰӮдҪ•з»ҹи®ЎпјҢpythonжңүдёӘеә“pandasпјҢиҝҷдёӘе°ұеҫҲж“…й•ҝеҒҡиҝҷдёӘе·ҘдҪңпјҢиҝҷйҮҢе°ұи®І2дёӘpandasзҡ„йӘҡж“ҚдҪң гҖӮpandasдёӯgroupbyгҖҒGrouperе’ҢaggеҮҪж•°зҡ„дҪҝз”Ё гҖӮиҝҷ2дёӘеҮҪж•°дҪңз”Ёзұ»дјјпјҢйғҪжҳҜеҜ№ж•°жҚ®йӣҶдёӯзҡ„дёҖзұ»еұһжҖ§иҝӣиЎҢиҒҡеҗҲж“ҚдҪңпјҢжҜ”еҰӮз»ҹи®ЎдёҖдёӘз”ЁжҲ·еңЁжҜҸдёӘжңҲеҶ…зҡ„е…ЁйғЁиҠұй”ҖпјҢз»ҹи®ЎжҹҗдёӘеұһжҖ§зҡ„жңҖеӨ§гҖҒжңҖе°ҸгҖҒзҙҜе’ҢгҖҒе№іеқҮзӯүж•°еҖј гҖӮ

ж–Үз« жҸ’еӣҫ
з»ҹи®Ў“ext price”иҝҷдёӘеұһжҖ§еңЁжҜҸдёӘжңҲзҡ„зҙҜе’ҢпјҲsumпјүеҖјimport pandas as pdimport collectionsdf = pd.read_Excel("D:/Download/chrome/sample-salesv3.xlsx")#print (df.head(10))df["date"] = pd.to_datetime(df["date"])# print (df.head(10))df1 = df.set_index("date").resample("M")['ext price'].sum()# print(df1.head())

ж–Үз« жҸ’еӣҫ
з»ҹи®ЎжҜҸдёӘз”ЁжҲ·жҜҸдёӘжңҲ"ext price"иҝҷдёӘеұһжҖ§зҡ„sumеҖјпјҢеҲ©з”ЁGrouperdf2 = df.groupby(["name",pd.Grouper(key = "date",freq="M")])["ext price"]print(df2.head(10))

ж–Үз« жҸ’еӣҫ
AggaggеҮҪж•°пјҢе®ғжҸҗдҫӣеҹәдәҺеҲ—зҡ„иҒҡеҗҲж“ҚдҪң гҖӮиҖҢgroupbyеҸҜд»ҘзңӢеҒҡжҳҜеҹәдәҺиЎҢпјҢжҲ–иҖ…иҜҙindexзҡ„иҒҡеҗҲж“ҚдҪң гҖӮ
д»Һе®һзҺ°дёҠзңӢпјҢgroupbyиҝ”еӣһзҡ„жҳҜдёҖдёӘDataFrameGroupByз»“жһ„пјҢиҝҷдёӘз»“жһ„еҝ…йЎ»и°ғз”ЁиҒҡеҗҲеҮҪж•°пјҲеҰӮsumпјүд№ӢеҗҺпјҢжүҚдјҡеҫ—еҲ°з»“жһ„дёәSeriesзҡ„ж•°жҚ®з»“жһң гҖӮ
иҖҢaggжҳҜDataFrameзҡ„зӣҙжҺҘж–№жі•пјҢиҝ”еӣһзҡ„д№ҹжҳҜдёҖдёӘDataFrame гҖӮеҪ“然пјҢеҫҲеӨҡеҠҹиғҪз”ЁsumгҖҒmeanзӯүзӯүд№ҹеҸҜд»Ҙе®һзҺ° гҖӮдҪҶжҳҜaggжӣҙеҠ з®ҖжҙҒ, иҖҢдё”дј з»ҷе®ғзҡ„еҮҪж•°еҸҜд»ҘжҳҜеӯ—з¬ҰдёІпјҢд№ҹеҸҜд»ҘиҮӘе®ҡд№үпјҢеҸӮж•°жҳҜcolumnеҜ№еә”зҡ„еӯҗDataFrame
иҺ·еҸ–"ext price","quantity","unit price"3еҲ—зҡ„еҗ„иҮӘзҡ„зҙҜи®ЎеҖје’ҢеқҮеҖјdf3 = df[["ext price","quantity","unit price"]].agg(["sum","mean"])print(df3.head())

ж–Үз« жҸ’еӣҫ
еҸҜд»Ҙй’ҲеҜ№дёҚеҗҢзҡ„еҲ—дҪҝз”ЁдёҚеҗҢзҡ„иҒҡеҗҲеҮҪж•°df4 = df.agg({"ext price":["sum","mean"],"quantity":["sum","mean"],"unit price":["mean"]})print(df4.head())

ж–Үз« жҸ’еӣҫ
д№ҹеҸҜд»ҘиҮӘе®ҡд№үеҮҪж•°пјҢжҜ”еҰӮпјҢз»ҹи®ЎskuдёӯпјҢиҙӯд№°ж¬Ўж•°жңҖеӨҡзҡ„дә§е“Ғзј–еҸ·пјҢйҖҡиҝҮlambdaиЎЁиҫҫејҸжқҘеҒҡ гҖӮ#з»ҹи®ЎskuдёӯпјҢиҙӯд№°ж¬Ўж•°жңҖеӨҡзҡ„дә§е“Ғзј–еҸ·get_max = lambda x:x.value_counts(dropna=False).index[0]get_max.__name__ = "most frequent"df5 = df.agg({"ext price":["sum","mean"], "quantity":["sum","mean"], "unit price":["mean"], "sku":[get_max] })print(df5)

ж–Үз« жҸ’еӣҫ
еҰӮжһңеёҢжңӣиҫ“еҮәзҡ„еҲ—жҢүз…§жҹҗдёӘйЎәеәҸжҺ’еҲ—пјҢеҸҜд»ҘдҪҝз”Ёcollectionsзҡ„OrderedDictagg_dict = { "ext price":["sum","mean"], "quantity":["sum","mean"], "unit price":["mean"], "sku":[get_max]}#жҢүз…§еҲ—еҗҚзҡ„й•ҝеәҰжҺ’еәҸ гҖӮOrderedDictзҡ„йЎәеәҸжҳҜи·ҹжҸ’е…ҘйЎәеәҸдёҖиҮҙзҡ„df6 = df.agg(collections.OrderedDict(sorted(agg_dict.items(),key=lambda x:len(x[0]))))print(df6)

ж–Үз« жҸ’еӣҫ
жәҗж•°жҚ®зҡ„й“ҫжҺҘпјҡhttps://github.com/chris1610/pbpython/tree/master/data
гҖҗPythonеӨ„зҗҶеӨ§ж•°жҚ®зҡ„2дёӘзҘһеҘҮж“ҚдҪңгҖ‘
жҺЁиҚҗйҳ…иҜ»














- еӨӘжһҒеӣҫзҡ„еҗ«д№үеҚҡеӨ§зІҫж·ұеҶ…ж¶өдё°еҜҢ
- е°Ҹе°ҸиҢ¶жқҜ еӨ§еӨ§е“ІеӯҰ
- жҜ”дәҡиҝӘ|еҒңдә§зҮғжІ№иҪҰ жҜ”дәҡиҝӘзҡ„иғҶеӯҗжҖҺд№Ҳиҝҷд№ҲеӨ§пјҹ
- зҫҪз»’иў«жҖҺд№Ҳжҙ—ж¶Өж–№жі• зҫҪз»’иў«йӮЈд№ҲеӨ§жҖҺд№Ҳжҙ—
- иҖҒжқҝзҮғж°”зҒ¶з»ҙдҝ®дёҺеёёи§Ғй—®йўҳеӨ„зҗҶ
- еҚҒеӨ§зқҖеҗҚејҖе…ійқўжқҝе“ҒзүҢжҺЁиҚҗ
- з ҙеЈҒжңәеә•зіҠдәҶжӢҝд»Җд№ҲеӨ„зҗҶеҘҪ з ҙеЈҒжңәеә•йғЁзіҠдәҶиҝҳиғҪз”Ёеҗ—
- иҢ¶дёҺдәәз”ҹеӣӣеӨ§е“ІзҗҶ
- зҲёзҲёеҺ»е“Әе„ҝеӨ§й—№иҢ¶з•Ң
- жўҰи§ҒиңҳиӣӣеңЁжүӢдёҠз”©дёҚжҺү еҒҡжўҰжўҰеҲ°еӨ§иңҳиӣӣжҺүиә«дёҠз”©йғҪз”©дёҚжҺү