按关键词阅读:
文章图片
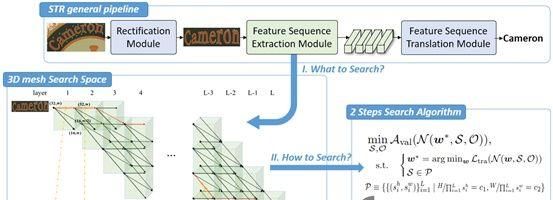
(3)搜索算法
本文将搜索 的过程和搜索 的过程解耦成两步搜索过程,具体来说,在第一步中,本文下采样路径上面的卷积操作 全部固定成默认的3X3的普通残差网络层,然后在此基础上搜索下采样路径。第二步搜索的过程是基于第一步已经搜索出来的最优下采样路径,进一步搜索如何在该路径上面放置更好的卷积操作。
第一步:搜索特征下采样路径
用 表示卷积网络 在数据集 上计算得到的序列交叉熵损失。用 表示训练集,对应的 表示验证集。在这一步骤中先默认卷积操作为固定的 ,搜索下采样路径。因此公式(1)中 变成了常量,可以被改写成公式(2)中的搜索任务。
在3.2.1节本文已经阐述了下采样路径中只能存在两次 和三次 的卷积滑动的步长策略以满足约束条件 ,我们分别用符号 和 表示这两种步长策略。注意到目前的一些NAS方法,在每个卷积阶段使用相同数量的层,并取得了良好的效果。通过使用这些合理的先验知识与设计准则,本文对搜索空间进行了简化,对于一个深度 的网络,本文在第1、4、7、10、13层分别设置特征下采样,而其他层使用步长 即保持当前分辨率不变,从而将整个网络平均分成五个卷积阶段,每个卷积阶段包含3个卷积层。因此特征下采样路径可以划分为10种典型的路径: 、 、 、 、 、 、 、 、 和 。本文可以在这些典型的路径集合中进行小范围的网格化搜索,以找到最接近 的良好路径。然后,通过在搜索步骤2中学习跳连接(Skip-Connect)层,从而可以减少每个卷积阶段的卷积层数。
第二步:搜索卷积操作块
受可微分架构搜索的启发,我们给第 层的卷积操作 赋予结构参数 ,从而将卷积块中操作的离散选择给连续化。由于 对整个网络的复杂度和准确率都会产生影响,因此我们给操作搜索的优化函数引入了一个正则项 以便实现一个良好的折中,如公式(3), 用于调节正则项对损失函数的影响程度, 表示作为参考网络的计算量。
因此公式(1)的优化目标可以继续改写成公式(4),
目前很多方法可以用来解决公式(4)中的问题,比如DARTS [1]、NASP [2]等等,为了节约显存,我们最后采用了ProxylessNAS [3]。
[1]. DARTS: Differentiable Architecture Search. ICLR 2018
[2]. Efficient Neural Architecture Search via Proximal Iterations. AAAI 2020.
[3]. Proxylessnas: Direct neural architecture search on target task and hardware. ICLR 2018
4
【 范式|第四范式提出AutoSTR,自动搜索文字识别网络新架构】实验结果
此次,根据一般场景文本识别设计基准来评估本次工作的搜索架构。实验数据包括IIIT 5K-Words (IIIT5K) 、Street View Text (SVT) 、ICDAR 2003 (IC03) 、 ICDAR 2013 (IC13) 、ICDAR 2015 (IC15)、SVT-Perspective (SVTP) 等数据,其中,前四个数据集中的图像是规则的,其余为不规则的。
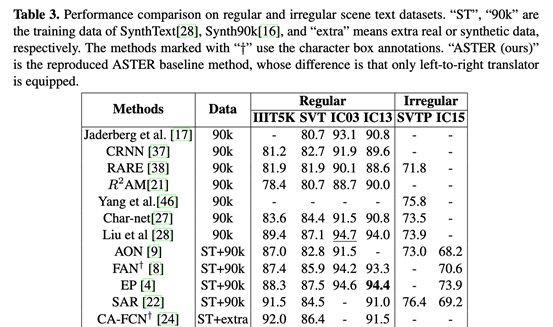
(1)实验对比
在识别精度上,利用搜索到的主干网,整个框架与其他最先进的方法进行了比较,如下图所示。
文章图片
AutoSTR在IIIT5K、SVT、IC15、SVTP中表现最好,在IC03、IC13中也获得了相似的结果。值得注意的是,AutoSTR在IIIT5K、SVT、IC03、IC13、SVTP、IC15上的表现优于ASTER,分别为1.4%、1.9%、0.9%、2.7%、2.3%,证明了AutoSTR的有效性。尽管SCRN可以获得与AutoSTR相当的性能,但它的校正模块需要额外的字符级注释来实现更精确的校正。作为一个插件,AutoSTR在配备SCRN整流模块的同时,有望进一步提高性能。
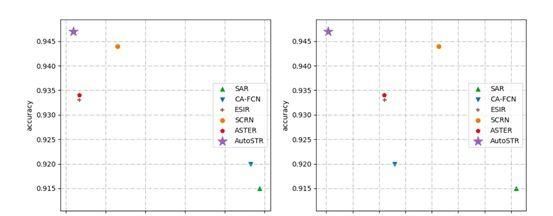
在计算耗能方面,下图详细比较了各方法的浮点运算和内存大小。
![]()
来源:(行走自由的花)
【江苏龙网】网址:/a/2021/0326/lmkd0RTG1542020.html
标题: 范式|第四范式提出AutoSTR,自动搜索文字识别网络新架构( 三 )
