低代码的器学习工具
具有PyCaret , BigQueryML和fastai的低代码AI 文章插图
文章插图
> Photo by Kasya Shahovskaya on Unsplash
【低代码的器学习工具】机器学习有潜力帮助解决企业和整个世界范围内的各种问题 。通常 , 要开发机器学习模型并将该模型部署到可以在操作上使用的状态 , 需要对编程有深入的了解 , 并且需要充分了解其背后的算法 。
这将机器学习的使用限制在一小部分人中 , 因此也限制了可以解决的问题数量 。
幸运的是 , 在过去的几年中 , 涌现了许多库和工具 , 这些库和工具减少了模型开发所需的代码量 , 或者在某些情况下完全消除了代码开发 。这为非数据科学家(如分析师)发挥了利用机器学习功能的潜力 , 并允许数据科学家更快地对模型进行原型制作 。
这是一些我最喜欢的用于机器学习的低代码工具 。
PyCaretPyCaret是Python的包装器 , 用于流行的机器学习库 , 例如Scikit-learn和XGBoost 。它使仅需几行代码就能将模型开发为可部署状态 。
可以通过pip安装Pycaret 。有关更详细的安装说明 , 请参阅PyCaret文档 。
pip install pycaret
PyCaret具有公共数据集的存储库 , 可以使用pycaret.datasets模块直接安装 。完整列表可在此处找到 , 但出于本教程的目的 , 我们将使用一个非常简单的数据集来解决称为"葡萄酒"数据集的分类任务 。
PyCaret库包含一组模块 , 用于解决所有常见的机器学习问题 , 其中包括:
· 分类 。
· 回归 。
· 聚类 。
· 自然语言处理 。
· 关联规则挖掘 。
· 异常检测 。
要创建分类模型 , 我们需要使用pycaret.classification模块 。创建模型非常简单 。我们只需调用将Model ID作为参数的create_model()函数即可 。您可以在此处找到支持的型号及其对应ID的完整列表 。或者 , 您可以在导入适当的模块后运行以下代码以查看可用模型的列表 。
from pycaret.classification import * models()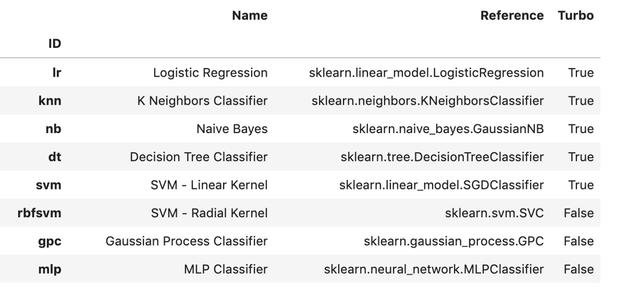 文章插图
文章插图
> A snapshot of models available for classification. Image by Author.
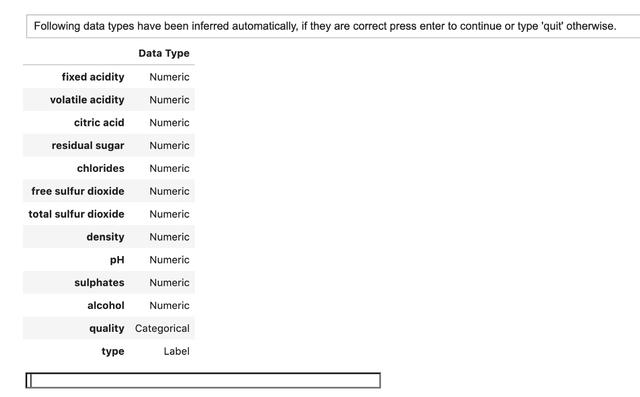
在调用create_model()之前 , 您首先需要调用setup()函数来为您的机器学习实验指定适当的参数 。在这里 , 您可以指定诸如测试序列拆分的大小以及是否在实验中实施交叉验证之类的内容 。
from pycaret.classification import *rf = setup(data = http://kandian.youth.cn/index/data,target ='type',train_size=0.8)rf_model = create_model('rf')create_model()函数将自动推断数据类型并使用默认方法处理这些数据类型 。运行create_model()时 , 您将收到以下输出 , 其中显示了推断的数据类型 。
 文章插图
文章插图
> Image by Author.
PyCaret将使用一组默认的预处理技术来处理诸如分类变量和估算缺失值之类的事情 。但是 , 如果您需要更定制的数据解决方案 , 则可以在模型设置中将它们指定为参数 。在下面的示例中 , 我更改了numeric_imputation参数以使用中位数 。
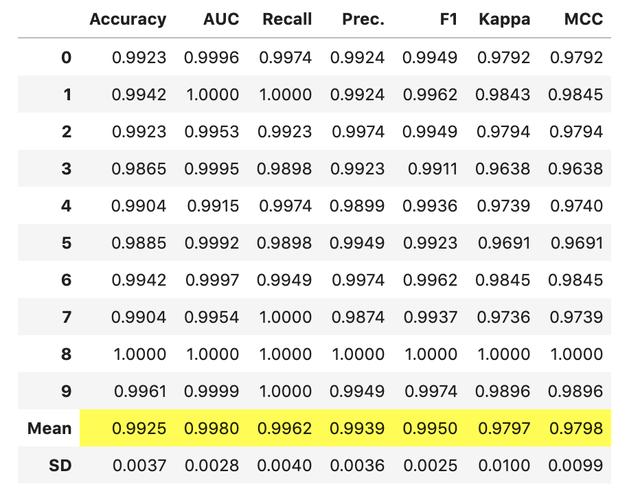
from pycaret.classification import *rf = setup(data = http://kandian.youth.cn/index/data,target ='type',numeric_imputation='median')rf_model = create_model('rf')对参数满意后 , 请按Enter键 , 模型将最终确定并显示性能结果网格 。
 文章插图
文章插图
推荐阅读

















- 计算机专业大一下学期,该选择学习Java还是Python
- 假期弯道超车 国美学习“神器”助孩子变身“学霸”
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 锐龙5000微代码更新:超频更稳、X570无需风扇
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 初探 iOS 自动化工具——快捷指令
- 学习大数据是否需要学习JavaEE
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能
- 免费好用:这款Win10系统增强工具不要错过(二)