AMD Zen3жһ¶жһ„ж·ұеәҰи§ЈжһҗпјҒжҸӯејҖжҖ§иғҪжҡҙж¶Ё39пј…зҡ„з§ҳеҜҶ( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
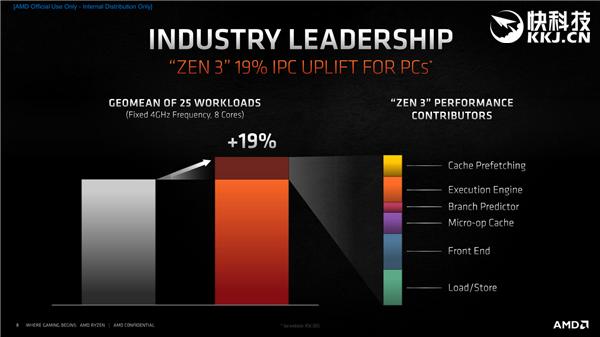
жӯЈжҳҜеҹәдәҺиҝҷдәӣж”№иҝӣ пјҢ Zen3жһ¶жһ„зҡ„IPCжҸҗеҚҮдәҶеӨҡиҫҫ19пј… пјҢ жқҘиҮӘеүҚз«ҜгҖҒиҪҪе…Ҙ/еӯҳеӮЁгҖҒжү§иЎҢеј•ж“ҺгҖҒзј“еӯҳйў„еҸ–гҖҒеҫ®ж“ҚдҪңзј“еӯҳгҖҒеҲҶж”Ҝйў„жөӢзӯүйғЁеҲҶзҡ„еҗҲеҠӣиҙЎзҢ® гҖӮ
йӮЈд№ҲеӨ§е®¶еҸҜиғҪдјҡз–‘жғ‘дәҶ пјҢ 19пј…иҝҷдёӘж•°еӯ—жҖҺд№ҲжқҘзҡ„пјҹ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
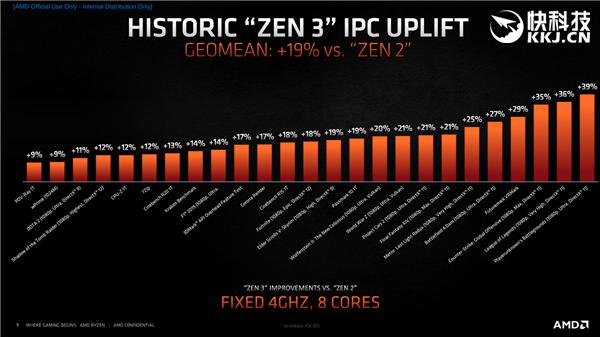
иҜҙиө·жқҘд№ҹз®ҖеҚ• пјҢ Zen3гҖҒZen2жһ¶жһ„йғҪеӣәе®ҡеңЁ8ж ёеҝғгҖҒ4GHzйў‘зҺҮ пјҢ 然еҗҺеҜ№жҜ”дёҚеҗҢеә”з”Ёзҡ„жҖ§иғҪеҸҳеҢ– пјҢ жңҖеҗҺз»јеҗҲиҖҢжқҘ гҖӮ
дёҚеҗҢе·ҘдҪңиҙҹиҪҪзҡ„жҸҗеҚҮе№…еәҰеҪ“然дёҚе°ҪзӣёеҗҢ пјҢ еҸҳеҢ–жңҖеӨ§зҡ„жҳҜй”җйҫҷд№ӢеүҚзҡ„ејұйЎ№зҪ‘жёё пјҢ еҗғйёЎгҖҒLOLгҖҒCSGOиҝҷдәӣжҸҗеҚҮдәҶеӨҡиҫҫ35-39пј… пјҢ еҶҚеҠ дёҠйў‘зҺҮжҸҗеҚҮзӯү пјҢ жңҖз»ҲеӨ§е®¶е°ұзңӢеҲ°дәҶй”җйҫҷ5000еңЁзҪ‘жёёйҮҢиҫ№зҝ»еӨ©иҰҶең°зҡ„еҸҳеҢ– гҖӮ
дәӢе®һдёҠ пјҢ жҸҗеҚҮе№…еәҰи¶…иҝҮ19пј…е№іеқҮж°ҙе№ізҡ„ пјҢ еҹәжң¬йғҪжҳҜжёёжҲҸ пјҢ д№ҹжӯЈеӣ дёәеҰӮжӯӨ пјҢ й”җйҫҷ5000жүҚеңЁжёёжҲҸжҖ§иғҪдёҠеӨәиө°дәҶIntelзҡ„жңҖеҗҺдёҖеӨ„йҳөең° пјҢ жңүиө„ж јиҜҙиҮӘе·ұжҳҜжңҖеҘҪзҡ„жёёжҲҸеӨ„зҗҶеҷЁ гҖӮ
жҸҗеҚҮе№…еәҰзӣёеҜ№иҫғе°Ҹзҡ„жҳҜдёҖдәӣеҹәеҮҶжҖ§иҙЁйЎ№зӣ®е’ҢдёҖдәӣйҡҫд»Ҙж·ұеәҰдјҳеҢ–зҡ„жёёжҲҸ пјҢ е°Өе…¶жҳҜеҚ•зәҝзЁӢжҖ§иғҪ пјҢ жҜ”еҰӮPOV-Ray 9пј…гҖҒCPU-Z 12пј…гҖҒCineBench R20 13пј… пјҢ CineBench R15 18пј… пјҢ дҪҶеҚідҫҝеҰӮжӯӨеӨ§е®¶д№ҹзңӢеҲ°дәҶйқһеёёжҳҺжҳҫзҡ„е®һйҷ…жҖ§иғҪжҸҗеҚҮ пјҢ иҝҷеҸҜжҜ”жҹҗеҮ д»Јй…·зқҝжҜҸж¬ЎжңҖеӨҡ5пј…е·ҰеҸізҡ„еҸҳеҢ–иүҜеҝғеӨӘеӨҡдәҶ гҖӮ
еҰӮжһңдҪ и§үеҫ—еүҚиҫ№и®Ізҡ„жһ¶жһ„дёҚиҝҮзҳҫ пјҢ жғідәҶи§Јжӣҙж·ұе…Ҙ пјҢ жҺҘдёӢжқҘжҲ‘们е°ұжӢҶи§ЈжҲҗдёҚеҗҢжЁЎеқ— пјҢ еҚ•зӢ¬жқҘзңӢдёҖзңӢе®ғ们зҡ„еҸҳеҢ– гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
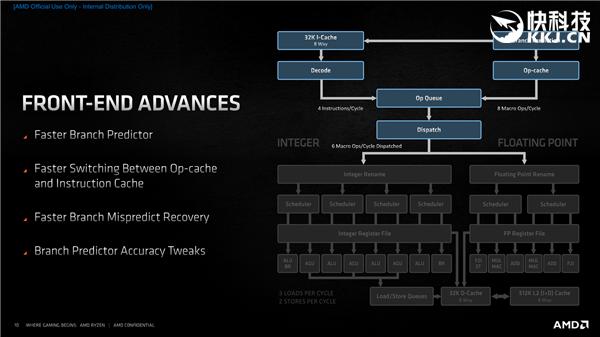
еүҚз«ҜйғЁеҲҶ пјҢ Zen3жү“йҖ дәҶдёҖдёӘжӣҙеҝ«зҡ„еҲҶж”Ҝйў„жөӢеҷЁ пјҢ еҸҜд»ҘеңЁжҜҸдёӘж—¶й’ҹе‘ЁжңҹеҶ…еӨ„зҗҶжӣҙеӨҡжҢҮд»Ө пјҢ еҗҢж—¶еңЁж“ҚдҪңзј“еӯҳгҖҒжҢҮд»Өзј“еӯҳд№Ӣй—ҙеҲҮжҚўжӣҙеҠ еҝ«йҖҹ пјҢ еә”д»ҳдёҚеҗҢе·ҘдҪңиҙҹиҪҪжӣҙеҠ зҒөжҙ»й«ҳж•Ҳ гҖӮ
еҪ“然 пјҢ еҲҶж”Ҝйў„жөӢдёҚеҸҜиғҪзҷҫеҲҶд№ӢзҷҫеҮҶзЎ® пјҢ йғҪжҳҜжңүжҰӮзҺҮзҡ„ пјҢ жңүж—¶еҖҷдјҡйў„жөӢй”ҷиҜҜ пјҢ иҝҷж—¶еҖҷзҡ„е…ій”®е°ұжҳҜиғҪдёҚиғҪеҝ«йҖҹжҒўеӨҚ пјҢ Zen3е°ұеӨ§еӨ§йҷҚдҪҺдәҶиҝҷж—¶еҖҷзҡ„延иҝҹ пјҢ еҸҜд»Ҙеҝ«йҖҹеӣһеҲ°жӯЈиҪЁ пјҢ еҲҶж”Ҝйў„жөӢзҡ„зІҫеәҰд№ҹеҫ—еҲ°жҸҗеҚҮ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
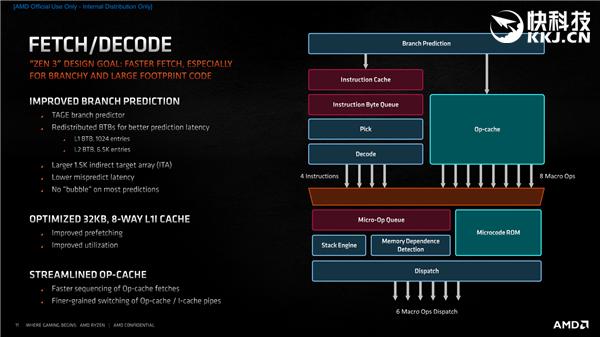
жӢҫеҸ–дёҺи§Јз ҒйғЁеҲҶ пјҢ иҝҷйҮҢеҸҜд»ҘзңӢеҲ°еҲҶж”Ҝйў„жөӢеҷЁзҡ„жӣҙеӨҡз»ҶиҠӮ пјҢ е°Өе…¶жҳҜзІҫеәҰжҸҗеҚҮжҳҜжҖҺд№ҲжқҘзҡ„ пјҢ жҜ”еҰӮеҲҶж”Ҝзӣ®ж Үзј“еҶІйҮҚж–°и®ҫи®ЎгҖҒL1 B2Bе®№йҮҸзҝ»еҖҚгҖҒL2 B2BйҮҚж–°з»„з»ҮгҖҒй—ҙжҺҘзӣ®ж ҮйҳөеҲ—(ITA)еўһеӨ§гҖҒжөҒж°ҙзәҝзј©зҹӯгҖҒй”ҷиҜҜйў„жөӢ延иҝҹйҷҚдҪҺзӯүзӯү гҖӮ
еҗҢж—¶ пјҢ 32KB 8и·Ҝе…іиҒ”зҡ„дёҖзә§жҢҮд»Өзј“еӯҳиҝӣиЎҢдәҶдјҳеҢ– пјҢ д»ҺиҖҢж”№иҝӣйў„еҸ–иғҪеҠӣе’ҢеҲ©з”ЁзҺҮ гҖӮ
ж“ҚдҪңзј“еӯҳд№ҹжӣҙеҠ зІҫзӮј пјҢ йҳҹеҲ—жӢҫеҸ–ж•ҲзҺҮжӣҙй«ҳ пјҢ ж“ҚдҪңзј“еӯҳдёҺжҢҮд»Өзј“еӯҳжөҒж°ҙзәҝзҡ„еҲҮжҚўд№ҹжӣҙеҠ иҮӘеҰӮ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
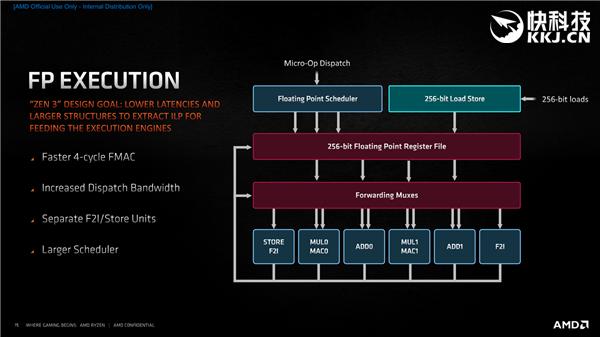
жү§иЎҢеј•ж“Һж–№йқў пјҢ еўһеҠ дәҶжө®зӮ№е’Ңж•ҙж•°еҲҶеҸ‘е®ҪеәҰ пјҢ йҷҚдҪҺдәҶFMAC延иҝҹ пјҢ иҝҳеўһеӨ§дәҶжү§иЎҢзӘ—еҸЈ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
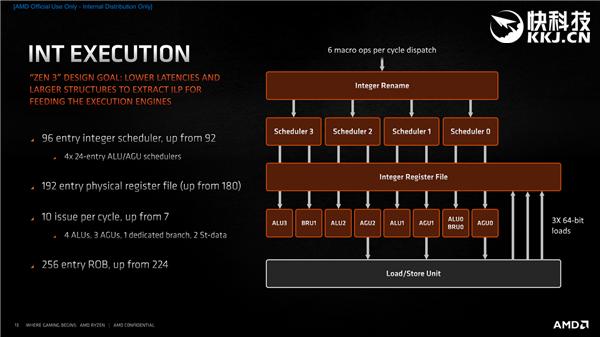
ж•ҙж•°жү§иЎҢж–№йқў пјҢ ж•ҙж•°и°ғеәҰеҷЁиҠӮзӮ№д»Һ92дёӘеўһиҮі96дёӘ(4Г—24еҲҶеёғ) пјҢ з”ЁжқҘйҮҚе‘ҪеҗҚйҖ»иҫ‘еҜ„еӯҳеҷЁд»ҘжҸҗеҚҮд№ұеәҸжү§иЎҢж•ҲзҺҮзҡ„зү©зҗҶеҜ„еӯҳеҷЁж–Ү件д№ҹд»Һ180дёӘеўһиҮі192дёӘ гҖӮ
жҜҸж—¶й’ҹе‘Ёжңҹзҡ„еҲҶеҸ‘д№ҹд»Һ7дёӘеўһиҮі10дёӘ пјҢ еҢ…жӢ¬4дёӘALU(з®—жңҜйҖ»иҫ‘еҚ•е…ғ)гҖҒ3дёӘAGU(ең°еқҖз”ҹжҲҗеҚ•е…ғ)гҖҒ1дёӘеҲҶж”ҜеҚ•е…ғгҖҒ2дёӘеӯҳеӮЁж•°жҚ®еҚ•е…ғ гҖӮ
жӯӨеӨ– пјҢ и®°еҪ•еҷЁзј“еҶІ(ROB)жүҖдҝқеӯҳзҡ„x86жҢҮд»Өд№ҹд»Һ224дёӘеўһиҮі256дёӘ гҖӮ
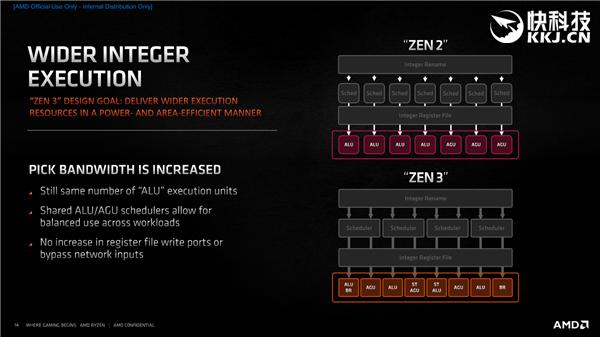
Zen3йҮҢзҡ„ж•ҙж•°еҚ•е…ғжІЎеҸҳиҝҳжҳҜ4дёӘ пјҢ дҪҶе…ұдә«дәҶALUгҖҒAGUи°ғеәҰеҷЁ пјҢ еә”еҜ№дёҚеҗҢиҙҹиҪҪж—¶жӣҙеҠ еқҮиЎЎ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»















- AMD Ryzen 7 5700GвҖңZen 3вҖқAPUи§„ж јжі„йңІ ж—¶й’ҹйў‘зҺҮй«ҳиҫҫ4.66GHz
- R9 5900HеҚіе°Ҷзҷ»еңәпјҢжңәжў°йқ©е‘ҪеҸ‘еёғAMDж——иҲ°жёёжҲҸжң¬
- Zen3жһ¶жһ„пјҒй”җйҫҷ5000GжЎҢйқўAPUж ·е“ҒзҺ°иә«пјҡеҚ•ж ёжҲҳе№іi9-10900K
- еҫ®иҪҜSurface Laptop 4дә§е“ҒзәҝеҸҜиғҪеҢ…еҗ«жӣҙеӨҡAMDеһӢеҸ·
- еҚҺзЎ•еҹәдәҺWRX80зҡ„дё»жқҝзҺ°иә« дёәAMD Ryzen Threadripper Proжү“йҖ
- AMD Zen3 APUеҶ…ж ёеӣҫжҸҗеүҚеҒ·и·‘пјҡдёүзә§зј“еӯҳиҙЁеҸҳ
- AMDCESеҸ‘еёғдјҡ1жңҲ13ж—ҘеҮҢжҷЁ0зӮ№ејҖе§ӢпјҡиӢҸе§ҝдё°дҪңдё»йўҳжј”и®І
- AMDе®ҳе®ЈCEOиӢҸе§ҝдё°CESжј”и®Іпјҡй”җйҫҷ5000笔记жң¬жү“еӨҙйҳө
- Zen3еҸ‘йЈҷпјҒй”җйҫҷ7 5800Uи·‘еҲҶжөҒеҮәпјҡеӨҡж ёжҡҙж¶Ё27пј…
- 8ж ёZen3 AMDж–°CPUзҺ°иә«пјҡй”җйҫҷ7 5700G