AMD Zen3жһ¶жһ„ж·ұеәҰи§ЈжһҗпјҒжҸӯејҖжҖ§иғҪжҡҙж¶Ё39пј…зҡ„з§ҳеҜҶ
AMDеҹәдәҺZen3е…Ёж–°жһ¶жһ„зҡ„й”җйҫҷ5000зі»еҲ—з»ҲдәҺи§ЈзҰҒдёҠеёӮдәҶ пјҢ дёҚзҹҘйҒ“й”җйҫҷ9 5950XгҖҒй”җйҫҷ9 5900Xзҡ„жҖ§иғҪжҳҜеҗҰи®©еӨ§е®¶ж»Ўж„ҸпјҹеӨ§е–ҠYESзҡ„еҗҢж—¶жңүжІЎжңүеүҒжүӢд№°д№°д№°пјҹ
жҺҘдёӢжқҘ пјҢ еҝ«з§‘жҠҖиҝҳдјҡеҘүдёҠй”җйҫҷ7 5800XгҖҒй”җйҫҷ5 5600Xзҡ„иҜ„жөӢ пјҢ 敬иҜ·жңҹеҫ… гҖӮ
иҝҷж¬Ў пјҢ й”җйҫҷдёҖзӣҙд»ҘжқҘеҸҜд»ҘиҜҙе”ҜдёҖејұеҠҝзҡ„еҚ•ж ёеҝғ/жёёжҲҸжҖ§иғҪз»ҲдәҺдёҚеҶҚжҳҜзҹӯжқҝ пјҢ дёҖдёҫе®һзҺ°дәҶеҜ№Intelзҡ„еҸҚи¶… пјҢ иҖҢдё”иҝҳжҳҜеңЁеҲ¶йҖ е·Ҙиүәз»ҙжҢҒ7nmе·Ҙиүәе®Ңе…ЁдёҚеҸҳзҡ„еүҚжҸҗдёӢеҒҡеҲ°зҡ„ пјҢ е…Ёж–°и®ҫи®Ўзҡ„Zen3жһ¶жһ„еҸҜд»ҘиҜҙеҠҹдёҚеҸҜжІЎ пјҢ иҝҷд№ҹжҳҜZenиҜһз”ҹд»ҘжқҘжңҖеӨ§и§„жЁЎзҡ„еҸҳйқ© гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
д»ҠеӨ© пјҢ жҲ‘们е°ұеҘҪеҘҪиҒҠдёҖиҒҠZen3жһ¶жһ„зҡ„йқ©ж–°д№ӢеӨ„ гҖӮ
еҪ“然дәҶ пјҢ еӨ„зҗҶеҷЁжһ¶жһ„и®ҫи®ЎжҳҜжһҒдёәй«ҳж·ұзҡ„еӯҰй—® пјҢ жҲ‘们дёҚеҸҜиғҪи®Іеҫ—еӨҡд№Ҳж·ұе…ҘгҖҒдё“дёҡ пјҢ е°ұиҜҙиҜҙдёҖдәӣжҜ”иҫғиЎЁеұӮе’ҢдҫҝдәҺзҗҶи§Јзҡ„дёңиҘҝ пјҢ зңӢзңӢеҰӮжӯӨйҖҶеӨ©зҡ„жҖ§иғҪйЈһи·ғ究з«ҹеҰӮдҪ•иҖҢжқҘ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
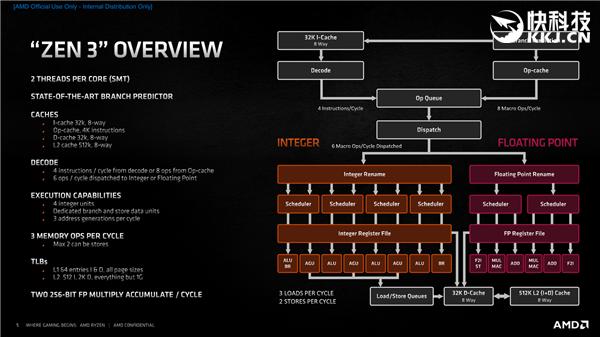
йҰ–е…Ҳ пјҢ еҒҡд»»дҪ•дәӢйғҪиҰҒжңүзӣ®ж Ү пјҢ и®ҫи®ЎдёҖдёӘеӨ„зҗҶеҷЁжһ¶жһ„жӣҙжҳҜеҰӮжӯӨ гҖӮ Zen3зҡ„зӣ®ж Үе°ұжңүдёүдёӘпјҡ
дёҖжҳҜжҸҗеҚҮеҚ•зәҝзЁӢжҖ§иғҪ пјҢ дё“дёҡеҗҚиҜҚеҸ«IPC(жҜҸж—¶й’ҹе‘ЁжңҹжҢҮд»Өж•°) пјҢ жҜ•з«ҹд№ӢеүҚеҮ д»ЈдёҖзӣҙиҝҪжұӮеӨҡж ёеҝғдёәдё» пјҢ жҳҜж—¶еҖҷжҠҠеҚ•ж ёжҖ§иғҪжҸҗеҚҮеҲ°и¶іеӨҹзҡ„й«ҳеәҰдәҶ пјҢ дёҚ然е§Ӣз»ҲжҳҜзҳёзқҖи„ҡиө°и·Ҝ пјҢ зјәд№Ҹй•ҝд№…з«һдәүеҠӣ гҖӮ
дәҢжҳҜеңЁз»ҙжҢҒ8ж ёеҝғCCDжЁЎеқ—зҡ„еүҚжҸҗдёӢ пјҢ з»ҹдёҖж ёеҝғдёҺзј“еӯҳ пјҢ жҸҗеҚҮеҪјжӯӨйҖҡдҝЎж•ҲзҺҮ пјҢ йҷҚдҪҺ延иҝҹ гҖӮ
дёүжҳҜ继з»ӯжҸҗй«ҳиғҪж•ҲжҜ” пјҢ жҖ§иғҪжҸҗеҚҮзҡ„еҗҢж—¶еҠҹиҖ—дёҚиғҪеӨұжҺ§ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дёәжӯӨ пјҢ Zen3жһ¶жһ„еҜ№дәҺжүҖжңүжЁЎеқ—йғҪиҝӣиЎҢдәҶзҝ»ж–° пјҢ еүҚз«ҜгҖҒйў„еҸ–гҖҒи§Јз ҒгҖҒжү§иЎҢгҖҒж•ҙж•°гҖҒжө®зӮ№гҖҒиҪҪе…ҘгҖҒеӯҳеӮЁгҖҒзј“еӯҳзӯүзӯү пјҢ жҜҸдёӘзҺҜиҠӮйғҪжҳҜ焕然дёҖж–° гҖӮ
йҰ–е…Ҳ пјҢ Zen3и®ҫи®ЎдәҶдёҖдёӘе Әз§°иүәжңҜзә§зҡ„еҲҶж”Ҝйў„жөӢеҷЁ пјҢ е®ғд№ӢеҗҺжңүдёӨжқЎйҖҡйҒ“е°ҶжҢҮд»ӨйҖҒе…ҘйҳҹеҲ— пјҢ 然еҗҺиҝӣиЎҢеҲҶжҙҫ пјҢ дёҖжҳҜ8и·Ҝе…іиҒ”зҡ„32KBдёҖзә§жҢҮд»Өзј“еӯҳе’Ңx86и§Јз ҒеҷЁ пјҢ дәҢжҳҜ4KжҢҮд»Өзҡ„ж“ҚдҪңзј“еӯҳ(Op-cache) гҖӮ
x86и§Јз ҒеҷЁзҡ„йҷҗеҲ¶жҳҜжҜҸдёӘж—¶й’ҹе‘ЁжңҹеҸӘиғҪеӨ„зҗҶжңҖеӨҡ4жқЎжҢҮд»Ө пјҢ дҪҶеҰӮжһңжҳҜзҶҹжӮүзҡ„жҢҮд»Ө пјҢ е°ұеҸҜд»Ҙж”ҫе…Ҙж“ҚдҪңзј“еӯҳ пјҢ жҜҸдёӘе‘Ёжңҹе°ұиғҪеӨ„зҗҶ8жқЎ пјҢ дәҢиҖ…з»“еҗҲжҢҮд»ӨеҲҶеҸ‘ж•ҲзҺҮе°ұеӨ§еӨ§жҸҗеҚҮ пјҢ зӣёжҜ”дәҺZen2зӣҙжҺҘдёҠеҚҮдәҶдёҖдёӘжЎЈж¬Ў гҖӮ
жҢҮд»ӨеҲҶжҙҫд№ӢеҗҺе°ұжқҘеҲ°жү§иЎҢеј•ж“Һйҳ¶ж®ө пјҢ еҲҶдёәж•ҙж•°гҖҒжө®зӮ№дёӨеӨ§йғЁеҲҶ пјҢ жҜҸдёӘж—¶й’ҹе‘ЁжңҹеҸҜд»Ҙеҗ‘е®ғ们еҲҶжҙҫ6жқЎжҢҮд»Ө гҖӮ
е…¶дёӯ пјҢ ж•ҙж•°еҚ•е…ғиҝҳжҳҜ4дёӘ пјҢ дҪҶжӣҙеҠ еҲҶж•Ј пјҢ 并еўһеҠ дәҶдёҖдёӘеҚ•зӢ¬зҡ„еҲҶж”ҜдёҺж•°жҚ®еӯҳеӮЁеҚ•е…ғ пјҢ жҸҗеҚҮеҗһеҗҗйҮҸ пјҢ жҜҸж—¶й’ҹе‘ЁжңҹеҸҜд»Ҙз”ҹжҲҗ3дёӘең°еқҖ гҖӮ
жө®зӮ№ж–№йқўеҲҷеҲҶдёәе…ӯжқЎжөҒж°ҙзәҝ пјҢ иҝӣдёҖжӯҘжҸҗеҚҮеҗһеҗҗйҮҸе’Ңж•ҲзҺҮ гҖӮ
еҶ…еӯҳж–№йқў пјҢ жҜҸж—¶й’ҹе‘ЁжңҹеҸҜд»Ҙжү§иЎҢ3дёӘиҪҪе…Ҙ пјҢ жҲ–иҖ…1дёӘиҪҪе…ҘеҠ 2дёӘеӯҳеӮЁ пјҢ еҶҚж¬ЎжҸҗеҚҮеҗһеҗҗйҮҸ пјҢ 并且еҸҜд»ҘжӣҙзҒөжҙ»ең°еӨ„зҗҶдёҚеҗҢе·ҘдҪңиҙҹиҪҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
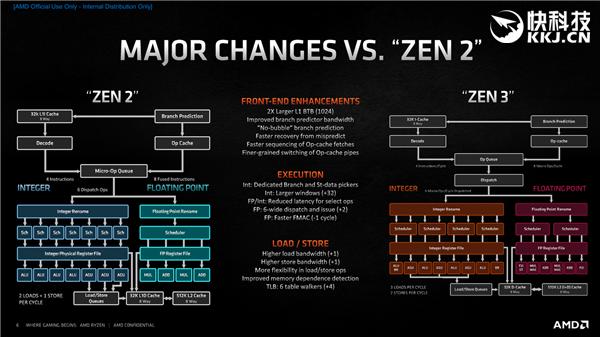
еҚ•зәҜиҜҙZen3еҸҜиғҪж„ҹи§үдёҚеҲ°д»Җд№Ҳ пјҢ йӮЈе°ұеҜ№жҜ”дёҖдёӢZen2 пјҢ еҸҳеҢ–еӨӘеӨҡиҝҳжҳҜжҚЎжңҖж ёеҝғзҡ„иҜҙ гҖӮ
еүҚз«Ҝж–№йқў пјҢ дё»иҰҒжңүе®№йҮҸзҝ»з•Әзҡ„L1 BTBгҖҒжӣҙеӨ§зҡ„еҲҶж”Ҝйў„жөӢеҷЁеёҰе®ҪгҖҒжӣҙеҝ«зҡ„йў„жөӢй”ҷиҜҜжҒўеӨҚгҖҒжӣҙеҝ«зҡ„ж“ҚдҪңзј“еӯҳжӢҫеҸ–гҖҒжӣҙзІҫз»Ҷзҡ„ж“ҚдҪңзј“еӯҳжөҒж°ҙзәҝеҲҮжҚў пјҢ зӯүзӯү гҖӮ
жү§иЎҢеј•ж“Һж–№йқў пјҢ дё»иҰҒжңүзӢ¬з«Ӣзҡ„еҲҶж”ҜдёҺж•°жҚ®еӯҳеӮЁеҚ•е…ғгҖҒжӣҙеӨ§зҡ„ж•ҙж•°зӘ—еҸЈгҖҒжӣҙдҪҺзҡ„зү№е®ҡж•ҙж•°/жө®зӮ№жҢҮд»Ө延иҝҹгҖҒ6е®ҪеәҰжӢҫеҸ–дёҺеҲҶеҸ‘гҖҒжӣҙе®Ҫзҡ„жө®зӮ№еҲҶжҙҫгҖҒжӣҙеҝ«зҡ„жө®зӮ№FMAC(д№ҳжі•зҙҜеҠ еҷЁ) пјҢ зӯүзӯү гҖӮ
иҪҪе…Ҙ/еӯҳеӮЁж–№йқў пјҢ дё»иҰҒжңүжӣҙй«ҳзҡ„иҪҪе…ҘеёҰе®Ҫ(2дёӘеҸҳ3дёӘ)гҖҒжӣҙй«ҳзҡ„еӯҳеӮЁеёҰе®Ҫ(1дёӘеҸҳ2дёӘ)гҖҒжӣҙзҒөжҙ»зҡ„иҪҪе…Ҙ/еӯҳеӮЁжҢҮд»ӨгҖҒжӣҙеҘҪзҡ„еҶ…еӯҳдҫқиө–жЈҖжөӢ пјҢ зӯүзӯү гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
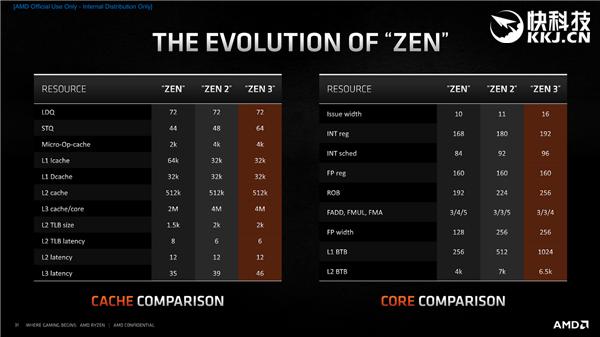
д»ҘдёҠжҳҜZenгҖҒZen2гҖҒZen3дёүд»Јжһ¶жһ„еңЁж ёеҝғгҖҒзј“еӯҳдёҖдәӣе…ій”®жҢҮж ҮдёҠзҡ„еҸҳеҢ– гҖӮ д№ҚдёҖзңӢ пјҢ Zen3еҸҳеҢ–зҡ„еҠӣеәҰдјјд№ҺдёҚеҰӮZen2 пјҢ дҪҶдёҖеҲҷиҝҷдәӣж•°еӯ—дёҚиғҪе®Ңе…ЁеҸҚеә”жӣҙж·ұеұӮж¬Ўзҡ„еҸҳеҢ– пјҢ дәҢеҲҷZen3еңЁе…ій”®жҢҮж ҮдёҠжӣҙжңүзӘҒз ҙ пјҢ жҜ”еҰӮиҜҙеҲҶеҸ‘е®ҪеәҰд»Һ10/11дёҖи·ғжқҘеҲ°16 пјҢ жү§иЎҢж•ҲзҺҮжҸҗеҚҮеҸҜдёҚжӯўдёҖзӮ№еҚҠзӮ№ гҖӮ
жҺЁиҚҗйҳ…иҜ»


















- AMD Ryzen 7 5700GвҖңZen 3вҖқAPUи§„ж јжі„йңІ ж—¶й’ҹйў‘зҺҮй«ҳиҫҫ4.66GHz
- R9 5900HеҚіе°Ҷзҷ»еңәпјҢжңәжў°йқ©е‘ҪеҸ‘еёғAMDж——иҲ°жёёжҲҸжң¬
- Zen3жһ¶жһ„пјҒй”җйҫҷ5000GжЎҢйқўAPUж ·е“ҒзҺ°иә«пјҡеҚ•ж ёжҲҳе№іi9-10900K
- еҫ®иҪҜSurface Laptop 4дә§е“ҒзәҝеҸҜиғҪеҢ…еҗ«жӣҙеӨҡAMDеһӢеҸ·
- еҚҺзЎ•еҹәдәҺWRX80зҡ„дё»жқҝзҺ°иә« дёәAMD Ryzen Threadripper Proжү“йҖ
- AMD Zen3 APUеҶ…ж ёеӣҫжҸҗеүҚеҒ·и·‘пјҡдёүзә§зј“еӯҳиҙЁеҸҳ
- AMDCESеҸ‘еёғдјҡ1жңҲ13ж—ҘеҮҢжҷЁ0зӮ№ејҖе§ӢпјҡиӢҸе§ҝдё°дҪңдё»йўҳжј”и®І
- AMDе®ҳе®ЈCEOиӢҸе§ҝдё°CESжј”и®Іпјҡй”җйҫҷ5000笔记жң¬жү“еӨҙйҳө
- Zen3еҸ‘йЈҷпјҒй”җйҫҷ7 5800Uи·‘еҲҶжөҒеҮәпјҡеӨҡж ёжҡҙж¶Ё27пј…
- 8ж ёZen3 AMDж–°CPUзҺ°иә«пјҡй”җйҫҷ7 5700G