Meteor 实时计算平台架构与实践
来源:微信公众号:携程技术
作者:何彬
出处:
作者简介何彬 , 携程市场营销研发部高级研发经理 , 10多年互联网研发和架构经验 。 2014年加入携程 , 负责携程广告、新媒体推广和市场大数据平台的构建、研发工作 。
一、前言
营销场景计算需求多种多样 , 场景模型也纷繁复杂 , 计算要求的资源配置也大小不一 , 系统更新部署步骤繁琐 , 人工操作亦有极大的安全风险 。 随着公司个性化营销的推广 , 类似的资源需求也越来越多 , 大集群支持、资源共享、资源效率是重点关注的问题 。
本文将介绍携程市场营销基于storm框架的meteor实时计算平台 , 解决日益增长的市场部业务需求 。
二、什么是Meteor
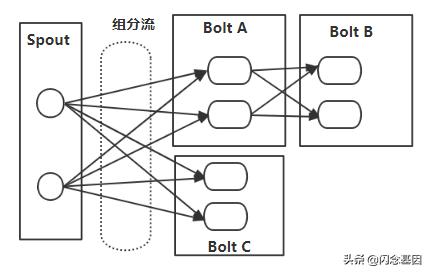
随时市场业务的不断发展 , 对实时计算的需求也逐渐增大 。 一直以来 , 我们根据市场的不同需求定制开发所要计算的Storm应用 , Storm实时运行的应用包逻辑上是一个topology , 一个Storm的topology相当于MapReduce的一个job , 不同是MapReduce的job有明确的起始和结束 , 而Storm的topology一旦被初始化就会一直运行下去 , 形成的topology是有spout、bolt通过数据流分组连接起来的图结构 。 如下:
 文章插图
文章插图
按照以上的结构拓扑图 , 很多情况下出现一个问题 , 针对一个实时计算的场景topology , 当我们需要改变当前拓扑的某一个或者某几个spout、bolt , 又或者我们仅需要增加一个处理节点 , 我们该如何处理?
Storm虽然可以通过rebalance 进行动态调整worker, executor等并发数 , 但是不支持spout、bolt节点的动态调整 , 一旦topology被初始化 , 其spout、bolt节点的数量和配置参数也就相对固定 。传统的架构方法是新增一个Storm应用 , 面对很多实时计算的需求 , 就需要新增这样的Storm应用 , 这些应用所要求的开发资源和集群规模也就越来越多、越来越大且难于管理 。
传统的解决方案已经成为业务发展的一个瓶颈 。 如何满足日益增长的计算需求、提高开发及系统资源的利用率成了我们急迫需要解决的问题 。
因此 , 我们对Storm进行了二次封装 , 结合节点管理 , 图形计算、自动编译、动态打包、自动发布及部署等工具进行了一次系统的封装 , 封装后的平台在我们内部称之为Meteor , 意思是快速达成美好的愿景 。
三、技术架构实现
下图给出的是Meteor的系统架构 , 自底向上分为驱动层、数据操作层、图计算层、服务层、应用层 , 其中驱动层、数据操作层、图计算层是Meteor的核心层 。
最下层是驱动层 。 驱动层包括Meteor分别在Storm、Spark等分布式计算系统上的实现 , 也就是对上层提供了一个统一的接口 , 使上层只需要处理场景计算等逻辑 , 而不需要关心在分布式计算系统上的实现过程 。
【Meteor 实时计算平台架构与实践】其上是数据操作层 , 主要包括逻辑表达式算法等操作 。 再往上是图计算层 , 也是我们要了解的核心 , 包含Graph DAG数据流图的实现(图的创建、编译、打包、发布和执行) 。 再往上是服务层和应用层 。
 文章插图
文章插图
Meteor 是用数据流图做处理的 , Meteor的数据流图是由计算节点(node)组成的有向无环图(directed acycline graph , DAG) 。 我们先创建一个数据流图(也称为网络结构图) , 如图所示 , 看一下数据流图中的各个要素 。 图中讲述了Meteor的运行原理 。 图中包含输入(input)、逻辑计算(function)、输出(output)等部分 。
它的计算过程是 , 首先从输入流开始 , 一层一层进行前向传播运算 。 逻辑计算可以定义一个或多个节点 , 每个节点代表一种算法 , 不同算法定义不同的传参 , 根据参数的配置可以调整计算的结果 。 然后进入输出层 , 输出层根据不同的客户端输出不同的数据格式 , 最后生成数据 。 如图所示 , 生成的每个数据流图从上往下依次进行计算 。
推荐阅读















- 大一非计算机专业的学生,如何利用寒假自学C语言
- 华云大咖说 云计算云运维浅谈
- 河北省首家“政策智通”计算器正式上线
- 计算机专业大一下学期,该选择学习Java还是Python
- 华为云知识计算解决方案获首批“知识图谱产品认证证书”
- 边缘|边缘计算将取代云计算?5G时代的最强黑马出现了吗?
- 边缘计算点燃新风暴,IT与OT之战一触即发
- 优刻得边缘计算产品正式更名UEC,打造低延时、高性能、低成本计算平台
- 仅用168天,商汤科技“新一代人工智能计算与赋能平台”项目结构封顶
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手