Meteor 实时计算平台架构与实践( 二 )
 文章插图
文章插图
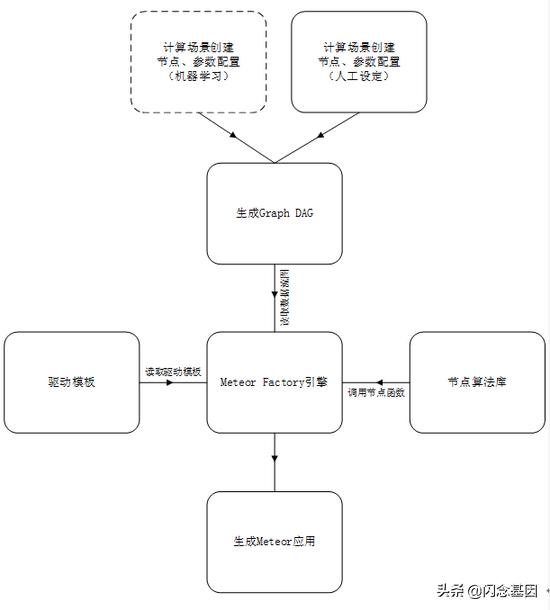
Meteor 数据流图由Meteor治理中心统一管理和运维 , 所有的数据层和计算节点统一在Meteor Service中进行注册 , 分配和调度 。 Meteor Service是整个系统的核心模块 , 用户通过RestAPI调用Service接口服务 , 提交场景配置和节点算法参数 , 目前由人工的方式根据不同的业务需求创建计算场景和计算节点参数配置 。 (计划由机器学习取代 , 机器学习直接生成数据流图)
生成后的数据流图注入Meteor Factory进行加工 , Meteor Factory是Meteor的应用引擎模块 , 主要是将组合场景的计算节点模块进行代码集成并编译打包 , 根据数据流图中配置的计算算法和参数 , 从节点算法库中调取相应的代码 , 触发Factory代码生成器 , 代码生成器根据Storm驱动模板生成相应的代码 , 生成好的代码执行自动编译并打成Storm可执行的应用包 。
 文章插图
文章插图
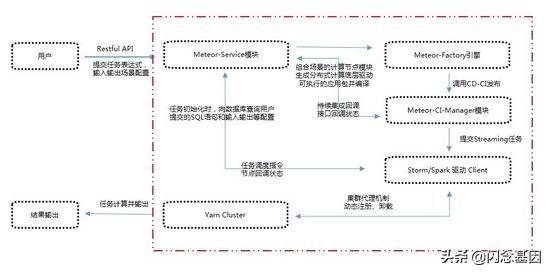
Meteor CI Service 模块将编译好的应用包和发布系统进行集成 , 由发布系统调用底层Storm客户端驱动 , 自动将应用包发布到Storm 。 Meteor CI Service和Storm客户端驱动的任务调度通过Meteor Service进行管理 。
 文章插图
文章插图
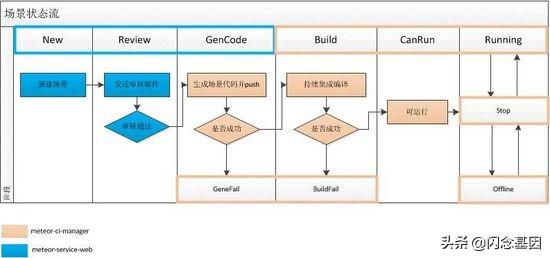
Meteor 任务调度由不同的状态控制和管理 , 以保证整个系统运行的有序性 。
1、场景被创建 , 不同的场景由不同的节点模块组成 , 场景创建时选取相应的节点模块 , 此时场景的数据状态为NEW;
2、新建完成的场景需要被审核 , 场景新建完成后提交给相应的审核 , 提交审核过程中的的场景数据状态为REVIEW;
3、当审核通过后场景代码开始生成 , 代码生成过程中的场景状态为GENCODE;
4、代码生成完成后进行编译动作 , 编译过程的场景状态为BUILD;
5、编译结束该场景就可以被执行了 , 可以被执行的场景状态为CANRUN;
6、当场景在运行过程中状态为RUNNING 。
 文章插图
文章插图
四、Meteor的特性
1、 高可用
Topology HAMeteor Service会定期与topology进行心跳交互 , 若Meteor Service检测到topology心跳超时 , 则会重新调起一个新的topology , 新的topology会将自身信息写入Zookeeper中 , 其它Container与Supervisor将通过Zookeeper来识别到新的topology , 从而保障topology的HA 。
Container/Worker HAContainer会定期与Meteor Service进行交互 , 若Meteor Service检测到Container心跳超时 , 则会重新从资源池里调起一个新的Container接管原来失效Container的任务 , 并把新的任务分配写入Zookeeper中 , 以便其它Container识别新的Container的位置 , 从而保障Container的HA 。
2、二级调度
封装后的Storm只需管理topology的调度 , 其它如UI访问、任务下发、拓扑、metrics、节点心跳等 , 均由Meteor Service的二级调度 。
3、 资源隔离
封装后每个topology实例下只有一个supervisor , 并且每个supervisor里只用一个worker , 通过每个worker来进行资源隔离 。 此外 , 不同节点可以任意组合一个新的topology , 同时我们引入权限管理 , 不用用户申请的计算资源(数据和节点算法)可以做到相互隔离 , 每个任务只能运行在授权的通道内 , 以此保证不同用户申请的资源不会被他人调用 。
4、 自动发布和部署
由于一个场景一个topology , 而一个topology实例可以理解为一个虚拟机 , 用户资源申请具有随机性、配置个性化等特点 , 因此对我们配置管理上必需具有自适应性 。 对此我们通过本地生成应用包 , 通过产品化把计算管理配置、Storm与CD-CI发布系统打通 , 并把资源配置、应用包的发布和部署等功能产品化 , 以达到自动发布和部署的目的 。
推荐阅读
![[科技全报导]空气净化器十大品牌选购,新房母婴快速去除甲醛应该这样做](https://imgcdn.toutiaoyule.com/20200430/20200430143240938393a_t.jpeg)
















- 大一非计算机专业的学生,如何利用寒假自学C语言
- 华云大咖说 云计算云运维浅谈
- 河北省首家“政策智通”计算器正式上线
- 计算机专业大一下学期,该选择学习Java还是Python
- 华为云知识计算解决方案获首批“知识图谱产品认证证书”
- 边缘|边缘计算将取代云计算?5G时代的最强黑马出现了吗?
- 边缘计算点燃新风暴,IT与OT之战一触即发
- 优刻得边缘计算产品正式更名UEC,打造低延时、高性能、低成本计算平台
- 仅用168天,商汤科技“新一代人工智能计算与赋能平台”项目结构封顶
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手