еҚҺдёәдә‘FusionInsightж№–д»“дёҖдҪ“и§ЈеҶіж–№жЎҲзҡ„жқҘдё–д»Ҡз”ҹ
дјҙйҡҸ5GгҖҒеӨ§ж•°жҚ®гҖҒAIгҖҒIoTзҡ„йЈһйҖҹеҸ‘еұ•,ж•°жҚ®е‘ҲзҺ°еӨ§и§„жЁЎгҖҒеӨҡж ·жҖ§зҡ„жһҒйҖҹеўһй•ҝ,дёәдәҶеә”еҜ№еӨҡеҸҳзҡ„дёҡеҠЎиҜүжұӮ,ж”ҝдјҒе®ўжҲ·еҜ№ж•°жҚ®еӨ„зҗҶеҲҶжһҗзҡ„е®һж—¶жҖ§е’ҢиһҚеҗҲжҖ§жҸҗеҮәдәҶжӣҙй«ҳзҡ„иҰҒжұӮ,вҖңж№–д»“дёҖдҪ“вҖқзҡ„жҰӮеҝөеә”иҝҗиҖҢз”ҹ,е®ғжү“з ҙж•°жҚ®ж№–дёҺж•°д»“й—ҙзҡ„еЈҒеһ’,дҪҝеҫ—еүІиЈӮж•°жҚ®иһҚеҗҲз»ҹдёҖ,еҮҸе°‘ж•°жҚ®еҲҶжһҗдёӯзҡ„жҗ¬иҝҒ,е®һзҺ°з»ҹдёҖзҡ„ж•°жҚ®з®ЎзҗҶ гҖӮ
ж—©еңЁ2020е№ҙ5жңҲд»Ҫзҡ„еҚҺдёәе…ЁзҗғеҲҶжһҗеёҲеӨ§дјҡдёҠ,еҚҺдёәдә‘CTOеј е®Үжҳ•жҸҗеҮәдәҶвҖңж№–д»“дёҖдҪ“вҖқжҰӮеҝө,еңЁйҡҸеҗҺзҡ„еҚҺдёәдә‘дёҺи®Ўз®—еҹҺеёӮеі°дјҡдёҠ,вҖңж№–д»“дёҖдҪ“вҖқзҗҶеҝөи·ҹйҡҸеҚҺдёәдә‘FusionInsightжҷәиғҪж•°жҚ®ж№–еңЁеҚ—дә¬гҖҒж·ұеңігҖҒиҘҝе®үгҖҒйҮҚеәҶзӯүең°еқҮжңүе‘ҲзҺ°,еңЁеҲҡз»“жқҹзҡ„HC2020дёҠ,еј е®Үжҳ•еңЁеҸ‘еёғж–°дёҖд»ЈжҷәиғҪж•°жҚ®ж№–еҚҺдёәдә‘FusionInsightж—¶еҶҚж¬ЎжҸҗеҲ°дәҶж№–д»“дёҖдҪ“зҗҶеҝө гҖӮ йӮЈжҲ‘们е°ұжқҘзңӢзңӢж№–д»“дёҖдҪ“зҡ„жқҘдё–д»Ҡз”ҹ гҖӮ
ж•°жҚ®ж№–е’Ңж•°жҚ®д»“еә“зҡ„еҸ‘еұ•еҺҶзЁӢе’ҢжҢ‘жҲҳ
ж—©еңЁ1990е№ҙ,жҜ”е°”В·жҒ©й—Ё(Bill Inmon)жҸҗеҮәдәҶж•°жҚ®д»“еә“,дё»иҰҒжҳҜе°Ҷз»„з»ҮеҶ…дҝЎжҒҜзі»з»ҹиҒ”жңәдәӢеҠЎеӨ„зҗҶ(OLTP)еёёе№ҙзҙҜз§Ҝзҡ„еӨ§йҮҸиө„ж–ҷ,жҢүж•°жҚ®д»“еә“зү№жңүзҡ„иө„ж–ҷеӮЁеӯҳжһ¶жһ„иҝӣиЎҢиҒ”жңәеҲҶжһҗеӨ„зҗҶ(OLAP)гҖҒж•°жҚ®жҢ–жҺҳ(Data Mining)зӯүеҲҶжһҗ,её®еҠ©еҶізӯ–иҖ…еҝ«йҖҹжңүж•Ҳең°д»ҺеӨ§йҮҸиө„ж–ҷдёӯеҲҶжһҗеҮәжңүд»·еҖјзҡ„иө„и®Ҝ,д»ҘеҲ©еҶізӯ–еҲ¶е®ҡеҸҠеҝ«йҖҹе“Қеә”еӨ–еңЁзҺҜеўғеҸҳеҢ–,её®еҠ©жһ„е»әе•ҶдёҡжҷәиғҪ(BI) гҖӮ
еӨ§зәҰеҚҒе№ҙеүҚ,дјҒдёҡејҖе§Ӣжһ„е»әж•°жҚ®ж№–жқҘеә”еҜ№еӨ§ж•°жҚ®ж—¶д»Ј,е®ғйҖҡеёёжҠҠжүҖжңүзҡ„дјҒдёҡж•°жҚ®з»ҹдёҖеӯҳеӮЁ,ж—ўеҢ…жӢ¬жәҗзі»з»ҹдёӯзҡ„еҺҹе§ӢеүҜжң¬,д№ҹеҢ…жӢ¬иҪ¬жҚўеҗҺзҡ„ж•°жҚ®,жҜ”еҰӮйӮЈдәӣз”ЁдәҺжҠҘиЎЁ, еҸҜи§ҶеҢ–, ж•°жҚ®еҲҶжһҗе’ҢжңәеҷЁеӯҰд№ зҡ„ж•°жҚ® гҖӮ
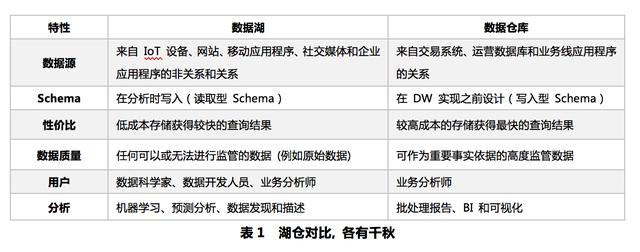
зәөи§Ӯж•°жҚ®ж№–дёҺж•°жҚ®д»“еә“зҡ„жҠҖжңҜеҸ‘еұ•,дёҚйҡҫеҸ‘зҺ°дёӨиҖ…жңүзқҖеҗ„иҮӘзҡ„дјҳеҠЈ,е…·дҪ“иЎЁзҺ°еҰӮдёӢ:
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дјҒдёҡеңЁиҝӣиЎҢзі»з»ҹжһ¶жһ„и®ҫи®ЎйҖүеһӢж—¶,йңҖиҰҒд»Һе…·дҪ“зҡ„еҲҶжһҗеңәжҷҜеҮәеҸ‘,еҚ•дёҖзҡ„жЁЎејҸе·Із»Ҹж— жі•ж»Ўи¶ідјҒдёҡеҸ‘еұ•зҡ„дёҡеҠЎиҜүжұӮ,йӣҶдёӯиЎЁзҺ°еңЁд»ҘдёӢдёӨдёӘз—ӣзӮ№:
?ж•°жҚ®ж№–дё»иҰҒд»ҘзҰ»зәҝжү№йҮҸи®Ўз®—дёәдё»,еӣ дёәдёҚж”ҜжҢҒж•°жҚ®д»“еә“зҡ„ж•°жҚ®з®ЎзҗҶиғҪеҠӣ,йҡҫд»ҘжҸҗй«ҳж•°жҚ®иҙЁйҮҸ;ж•°жҚ®е…Ҙж№–ж—¶ж•Ҳе·®дёҚж”ҜжҢҒе®һж—¶жӣҙж–°,ж•°жҚ®ж— жі•ејәдёҖиҮҙжҖ§;дё»йўҳе»әжЁЎдёҚеҸӢеҘҪ,ж— жі•зӣҙжҺҘеҺҶеҸІжӢүй“ҫе»әжЁЎ;еҗҢж—¶дәӨдә’еҲҶжһҗйҖҡеёёе°Ҷж•°жҚ®жҗ¬иҝҒеҲ°ж•°жҚ®д»“еә“е№іеҸ°,йҖ жҲҗеҲҶжһҗй“ҫи·Ҝй•ҝ,ж•°жҚ®еҶ—дҪҷеӯҳеӮЁ;жү№еҗҢж—¶д»“зјәд№Ҹе…ЁеұҖж•°жҚ®и§Ҷеӣҫ,дёҚеҗҢе№іеҸ°жҺҘеҸЈе·®ејӮе’ҢдёҚеҗҢејҖеҸ‘з®ЎзҗҶе·Ҙе…·,йҖ жҲҗз”ЁжҲ·ејҖеҸ‘дҪҝз”ЁеӨҚжқӮ,ж•°жҚ®еҲҶеҲ«з®ЎзҗҶз»ҙжҠӨд»Јд»·й«ҳдҪ“йӘҢе·® гҖӮ
ж•°жҚ®ж№–е’Ңж•°жҚ®д»“еә“жӯЈеңЁд»ҺдёӨжқЎжҠҖжңҜжј”иҝӣи·Ҝзәҝиө°еҗ‘иһҚеҗҲ
з»јдёҠ,ж•°жҚ®ж№–е’Ңж•°жҚ®д»“еә“еңЁдјҒдёҡж•°жҚ®еҲҶжһҗеңәжҷҜеҲҶеҲ«жүҝжӢ…дёҖж№–дёҖд»“зҡ„йҮҚиҰҒи§’иүІ,еҪўжҲҗдәҶе®Ңж•ҙзҡ„ж•°жҚ®еҲҶжһҗз”ҹжҖҒзі»з»ҹ,дёҠиҝ°дјҒдёҡеңәжҷҜйқўдёҙзҡ„2дёӘе…ій”®з—ӣзӮ№д№ҹеңЁй©ұеҠЁж•°жҚ®ж№–е’Ңж•°жҚ®д»“еә“еңЁжҠҖжңҜжј”иҝӣдёҠиө°еҗ‘иһҚеҗҲ:
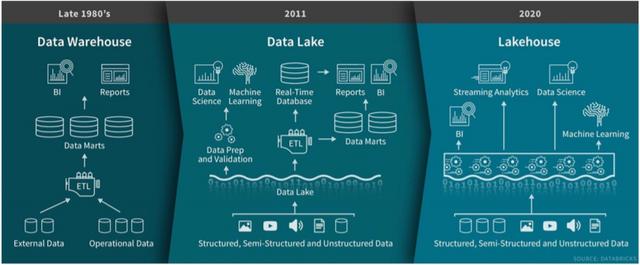
第дёҖдёӘиһҚеҗҲж–№еҗ‘жҳҜеҹәдәҺHadoopдҪ“зі»зҡ„ж•°жҚ®ж№–еҗ‘ж•°жҚ®д»“еә“иғҪеҠӣжү©еұ•,ж№–дёӯе»әд»“,д»ҺDataLakeиҝӣеҢ–еҲ°LakeHouse гҖӮ LakeHouseз»“еҗҲдәҶж•°жҚ®ж№–е’Ңж•°жҚ®д»“еә“зү№зӮ№,зӣҙжҺҘеңЁз”ЁдәҺж•°жҚ®ж№–зҡ„дҪҺжҲҗжң¬еӯҳеӮЁдёҠе®һзҺ°дёҺж•°жҚ®д»“еә“дёӯзұ»дјјзҡ„ж•°жҚ®з»“жһ„е’Ңж•°жҚ®з®ЎзҗҶеҠҹиғҪ гҖӮ зӣ®еүҚдёҡз•Ңе·Із»Ҹж¶ҢзҺ°дәҶдёҖдәӣLakeHouseдә§е“Ғ,еҰӮNexFlixејҖжәҗIcebergгҖҒUberејҖжәҗHudiгҖҒDatabricksзҡ„ DeltaLake гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
гҖҗеҚҺдёәдә‘FusionInsightж№–д»“дёҖдҪ“и§ЈеҶіж–№жЎҲзҡ„жқҘдё–д»Ҡз”ҹгҖ‘еӣҫ2д»ҺDataLakeиҝӣеҢ–еҲ°LakeHouse,ж•°жҚ®ж№–жү©еұ•ж•°д»“иғҪеҠӣ
д»Ҙзӣ®еүҚз”ҹжҖҒеҸ‘еұ•иҝ…йҖҹзҡ„Apache HudiдёәдҫӢ:з»ҹдёҖж•°жҚ®еӯҳеӮЁ,еҲҶеёғејҸеӯҳеӮЁдёҚеҗҢеә”з”ЁжүҖйңҖзҡ„еҗ„з§Қзұ»еһӢж•°жҚ®;ж•°д»“жЁЎејҸжү§иЎҢе’ҢжІ»зҗҶ,е®һзҺ°дәӢеҠЎж”ҜжҢҒеҗ„з§ҚеҲҶжһҗеј•ж“Һ,з»ҹдёҖж•°жҚ®еӯҳеӮЁйҖҡиҝҮејҖж”ҫе’Ңж ҮеҮҶеҢ–зҡ„еӯҳеӮЁж јејҸ(еҰӮParquet),жҸҗдҫӣAPIд»Ҙдҫҝеҗ„зұ»е·Ҙе…·е’Ңеј•ж“Һ(еҢ…жӢ¬жңәеҷЁеӯҰд№ е’ҢPython / Rеә“)зӣҙжҺҘжңүж•Ҳең°и®ҝй—®ж•°жҚ® гҖӮ
иҷҪ然LakeHouse并дёҚиғҪе®Ңе…Ёжӣҝд»Јж•°жҚ®д»“еә“,дҪҶйҖҡиҝҮеўһејәжҖ§иғҪ,ж”ҜжҢҒе®һж—¶е…Ҙж№–гҖҒе»әжЁЎгҖҒдәӨдә’еҲҶжһҗзӯүеңәжҷҜ,е°ҶеңЁдјҒдёҡеҲҶжһҗзҺҜеўғдёӯеҸ‘жҢҘжӣҙеӨ§дҪңз”Ё гҖӮ
第дәҢдёӘиһҚеҗҲж–№еҗ‘жҳҜж•°жҚ®ж№–е’Ңж•°жҚ®д»“еә“еҚҸеҗҢиө·жқҘеҗ‘ж№–д»“дёҖдҪ“зҡ„иһҚеҗҲеҲҶжһҗжһ¶жһ„еҸ‘еұ•,йҡҸзқҖдјҒдёҡж•°жҚ®йҮҸеҝ«йҖҹеўһй•ҝ,дёҚд»…жҳҜз»“жһ„еҢ–ж•°жҚ®,д№ҹжңүйқһз»“жһ„еҢ–ж•°жҚ®,еҗҢж—¶жҸҗеҮәдәҶеҜ№жҗңзҙў/жңәеҷЁеӯҰд№ жӣҙеӨҡзҡ„иғҪеҠӣиҰҒжұӮ,дҪҝеҫ—еҺҹжқҘж•°д»“жҠҖжңҜдёҚиғҪеӨҹжңүж•Ҳзҡ„еӨ„зҗҶеӨҚжқӮеңәжҷҜ,дёәжӯӨйңҖжү©еұ•еҺҹжңүзі»з»ҹ,еј•е…ҘHadoopеӨ§ж•°жҚ®е№іеҸ°е®һзҺ°ж–°зұ»еһӢж•°жҚ®гҖҒж–°дёҡеҠЎеңәжҷҜзҡ„ж”ҜжҢҒ гҖӮ еңЁиҝҷдёӘиғҢжҷҜдёӢз”ұGartnerеңЁ2011е№ҙжҸҗеҮәйҖ»иҫ‘ж•°жҚ®д»“еә“зҡ„жҰӮеҝө,йў„жөӢдјҒдёҡж•°жҚ®еҲҶжһҗеҖҫеҗ‘дәҺиҪ¬еҗ‘дёҖз§ҚжӣҙеҠ йҖ»иҫ‘еҢ–зҡ„жһ¶жһ„,еҲ©з”ЁеҲҶеёғејҸеӨ„зҗҶгҖҒж•°жҚ®иҷҡжӢҹеҢ–д»ҘеҸҠе…ғж•°жҚ®з®ЎзҗҶзӯүжҠҖжңҜ,е®һзҺ°йҖ»иҫ‘з»ҹдёҖзү©зҗҶеҲҶејҖзҡ„еҚҸеҗҢдҪ“зі» гҖӮ
жҺЁиҚҗйҳ…иҜ»












- еҚҺдёәйёҝи’ҷжқҘиўӯпјҢеҲҳејәдёңгҖҒи‘ЈжҳҺзҸ гҖҒ马еҢ–и…ҫеҠӣжҢәпјҢеҚҙдёҚи§ҒйҳҝйҮҢзі»иә«еҪұ
- йёҝи’ҷиҺ·ж¬§дјҒеҠӣжҢәпјҒеҚҺдёәзҡ„еӨ§ж—¶д»Је°ҶеҲ°жқҘпјҢи°·жӯҢиә«дёҠйҮҚзҺ°иҜәеҹәдәҡзҡ„еҪұеӯҗ
- зҰ»ејҖеҚҺдёәзҡ„ж–°иҚЈиҖҖжһҜжңЁйҡҫж”ҜпјҹйҰ–ж¬ҫжүӢжңәе°ұиў«еҶ·иҗҪпјҢдә¬дёңйў„зәҰж•°еӨӘйҡҫзңӢ
- OPPO Reno4 Pro DxOMarkжҲҗз»©е…¬еёғпјҡ109еҲҶдҪҺдәҺеҚҺдёәP20 Pro
- иҪ¬иҪ¬Q4жүӢжңәиЎҢжғ…пјҡеҚҺдёәMate40 ProжӣҙдҝқеҖј
- еҗ‘зҫҺеӣҪйқ жӢўпјҹз‘һе…ёз»•ејҖеҚҺдёәйғЁзҪІ5GпјҒеҚҺдёәе·І2ж¬Ўиө·иҜү
- еҚҺдёәејҖе§ӢиҝӣеҶӣжө·еӨ–ж”Ҝд»ҳпјҹе…Ҳз»ҷ他们зӮ№з”ңеӨҙпјҢж–°еҠ еқЎжҲҗйҹӯиҸңеҹәең°пјҹ
- еҚҺдёәеӣ зҘёеҫ—зҰҸпјҹжү“иҙҘй«ҳйҖҡйӘҒйҫҷ888зҡ„пјҢе…¶е®һ并дёҚжҳҜйә’йәҹ9000
- зәҝдёӢеёӮеңәеҪ»еә•вҖңд№ұдәҶвҖқпјҒе°Ҹзұіе®Јеёғ新规пјҒеҚҺдёәжҚҶз»‘еҠ д»·иЎҢдёәиҝҺдәүи®®
- иҝӣж”»жүҚжҳҜжңҖеҘҪзҡ„йҳІе®ҲпјҒеҚҺдёәжҢүдёӢвҖңеҝ«иҝӣй”®вҖқпјҢдј жқҘ3дёӘеҘҪж¶ҲжҒҜ