е…үеӯҗз®—ж•°зҷҪеҶ°пјҡиҜҰи§Је…үеӯҗAIиҠҜзүҮиҗҪең°иҝӣеұ•дёҺз ”еҸ‘и·Ҝеҫ„пҪңGTIC2020( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
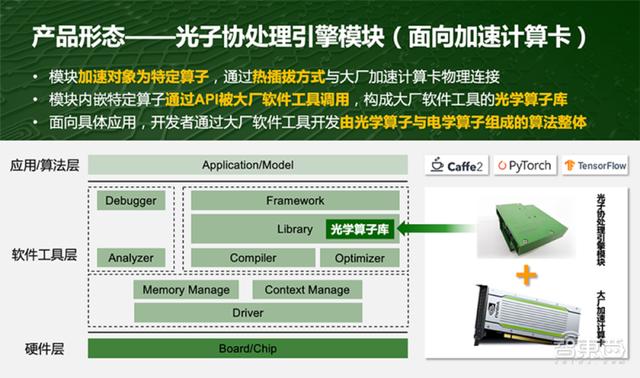
и®Ўз®—еҚЎе°ҒиЈ…жңүе…үеӯҗеҚҸеӨ„зҗҶеј•ж“ҺжЁЎеқ— пјҢ ж•ЈзғӯеҷЁгҖҒй©ұеҠЁгҖҒжҺ§еҲ¶еҷЁгҖҒTIAгҖҒдёҖдәӣи®Ўз®—жҺ§еҲ¶йғЁеҲҶе’ҢиөӣзҒөжҖқFPGAиҠҜзүҮ пјҢ ж•°жҚ®еңЁе…үз”өд№Ӣй—ҙеҪўжҲҗеҫӘзҺҜжөҒеҠЁ гҖӮ е…үзҡ„е®ҡдҪҚдёәз”өеҒҡеҚҸеӨ„зҗҶеҠ йҖҹ гҖӮ
е…¶дёӯе…үеӯҗеҚҸеӨ„зҗҶеј•ж“ҺжЁЎеқ—з”Ёзҡ„жҳҜдёӨдёӘQSFP28зҡ„е…үйҖҡдҝЎжҺҘеҸЈпјҲжҜҸдёӘйғҪжҳҜ100GB/sпјү пјҢ е…үйҖҡдҝЎзү©зҗҶжҺҘеҸЈйқһеёёжҲҗзҶҹ пјҢ е…¶е…үеӯҰеёҰе®ҪеӨ§зәҰиҫҫ200GB/s пјҢ е…ёеһӢеҠҹиҖ—иҫҫ7W пјҢ з®—еҠӣеңЁ1.2TOPSе·ҰеҸі гҖӮ иҜҘжЁЎеқ—ж”ҜжҢҒзғӯжҸ’жӢ” пјҢ дёҚйңҖиҰҒз»ҸиҝҮйў„и°ғ пјҢ еҶ…йғЁе°ҒиЈ…дәҶдёҖдәӣйҖӮеҗҲдәҺз”Ёе…үеӯҰеҒҡзҡ„зү№ж®Ҡзҡ„з®—еӯҗеҮҪж•° пјҢ жҜ”еҰӮйҡҸжңәжҠ•еҪұгҖҒй«ҳз»ҙз©әй—ҙеҸҳжҚўжҳ е°„гҖҒеҺӢзј©гҖҒе°Ҹ规模еҚ·з§ҜгҖҒж—¶й—ҙеәҸеҲ—зӯүй«ҳз®—еӯҗ гҖӮ зҺ°еңЁиҜҘжЁЎеқ—иҝҳжҜ”иҫғеҲқжӯҘ пјҢ зҷҪеҶ°йҖҸйңІйҒ“ пјҢ дёӢдёҖйҳ¶ж®ө пјҢ е…үеӯҗз®—ж•°дјҡиҝӣдёҖжӯҘжү©еӨ§е…¶и§„жЁЎ гҖӮ
е…үеӯҗеҚҸеӨ„зҗҶеј•ж“ҺжЁЎеқ—йҮҢйқўжҳҜдёӨеұӮз»“жһ„ пјҢ дёҠйқўжҳҜжҺ§еҲ¶жЁЎз»„ пјҢ е…¶дәҢзә§жҺ§еҲ¶зј“еӯҳеӨ„зҗҶйҡҸж—¶еҸҜд»ҘжҚў пјҢ д»ҘйҖӮеә”дёӢдёҖжӯҘиҪҜ件иҝӯд»ЈпјӣдёӢйқўжҳҜе…үеӯҰиҝҗз®—жЁЎз»„ пјҢ еҢ…еҗ«ж•ҙдёӘе…үеӯҰи®Ўз®—йғЁеҲҶ пјҢ е…¶дёӯйӣҶжҲҗдәҶеӨ§йҮҸзҡ„е…үеӯҰеҚ•е…ғ пјҢ дёәдәҶдёҖдәӣзү№е®ҡзҡ„еҮҪж•° пјҢ еҸҜд»ҘеҒҡдҪҺ延时гҖҒдҪҺиғҪиҖ—зҡ„еҸҳжҚўиҝҮзЁӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е®Ңж•ҙи®Ўз®—иҝҮзЁӢжҳҜFPGAжҺҘ收зҡ„ж•°жҚ®д»Һз”өжҺҘеҸЈиҝӣжқҘ пјҢ з»ҸиҝҮй©ұеҠЁж”ҫеӨ§ пјҢ й©ұеҠЁе…үиҠҜзүҮдёҠзҡ„и°ғдјҳеҷЁ пјҢ жҠҠдҝЎеҸ·еҶҚиҝ”еҲ°е…үдёҠ пјҢ з»ҸиҝҮзүҮеҶ…дј иҫ“е®ҢжҲҗеҸҳжҚў пјҢ 然еҗҺеҶҚеҸҳжҲҗз”өдҝЎеҸ·иҝ”еӣһ гҖӮ
зӣ®еүҚе…үеӯҗз®—ж•°е·Іе°ҶдёҖдәӣе…үз”өж··еҗҲAIеҠ йҖҹи®Ўз®—жңҚеҠЎеҷЁжҸҗдҫӣз»ҷжңәжҲҝе’ҢIDCиҜ•з”ЁдёҺжөӢиҜ• пјҢ жҺҘеҸЈжҳҜж ҮеҮҶзҡ„PCIeеҸЈ гҖӮ жӯӨеӨ– пјҢ е…¶жңҚеҠЎеҷЁд№ҹдёҺдёҖдәӣеӣҪдә§ж“ҚдҪңзі»з»ҹе’ҢCPUеҺӮе•ҶеҒҡдәҶйҖӮй…Қ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
зҷҪеҶ°еқҰиЁҖ пјҢ иҜҘжңҚеҠЎеҷЁзӣ®еүҚжҖ§иғҪд»Қиҫғжңүйҷҗ пјҢ 70WиҝҗиЎҢеҠҹиҖ—дёӢ пјҢ еӨ§жҰӮиғҪеҒҡдёүеӣӣеҚҒи·Ҝзҡ„и§Ҷйў‘еҗҢжӯҘеӨ„зҗҶ пјҢ и·ҹзәҜз”өжҜ”жІЎжңүйӮЈд№Ҳејә гҖӮ
дёӢдёҖжӯҘ пјҢ 他们иҖғиҷ‘е°Ҷе…үзҡ„йғЁеҲҶеёҰе®Ҫжү©еӨ§ пјҢ иҝӣдёҖжӯҘжҸҗеҚҮз®—еҠӣ гҖӮ еҪ“еүҚеңЁе…үйҖҡдҝЎйўҶеҹҹ пјҢ 100GB/sжҳҜдё»жөҒ пјҢ 200GB/sжҜ”иҫғе°‘ пјҢ 400GB/sгҖҒ800GB/sдё»иҰҒжңүдёҖдәӣеӨ§еҺӮеңЁеҒҡ пјҢ зӣ®еүҚиҝҳжІЎжҺЁеҮәдә§е“Ғ гҖӮ е°Ҫз®ЎеҒҡиҝҷеқ—жҲҗжң¬иҫғй«ҳ пјҢ дҪҶиҝҷжҳҜжҜ”иҫғеҲҮе®һеҸҜиЎҢзҡ„е·Іжңүж–№жЎҲ гҖӮ
дәҢгҖҒзғӯжҸ’жӢ”ејҸжЁЎеқ— пјҢ еҸҜз”ұеӨ§еҺӮиҪҜ件и°ғз”ЁжҺҘзқҖзҷҪеҶ°и°ҲеҲ°з¬¬дәҢдёӘиҜқйўҳ пјҢ е…үеӯҰиҠҜзүҮзҡ„дә§е“Ғе®ҡдҪҚ пјҢ еҚіиҝҷдёӘдёңиҘҝеҒҡе®Ңд№ӢеҗҺ пјҢ еҚ–з»ҷи°Ғпјҹ
еҰӮжһңжғіеңЁдә‘з«Ҝжӣҝд»ЈNVIDIA GPU пјҢ жҳҜйқһеёёеӣ°йҡҫзҡ„ пјҢ е…¶ж ёеҝғз«һдәүеҠӣеңЁдәҺе®ғзҡ„иҪҜ件е·Ҙе…· гҖӮ жҠҠз”өе’Ңе…үж”ҫеҲ°дёҖеј еҚЎдёҠ пјҢ иҰҒејҖеҸ‘е®Ңж•ҙзҡ„иҪҜ件еҘ—件 пјҢ е·ҘдҪңйҮҸйқһеёёеӨ§дё”д»Јд»·еҫҲй«ҳ гҖӮ еҪ“然дә‘з«ҜеҠ йҖҹи®Ўз®—еҚЎд№ҹеҸҜд»ҘеҒҡе®ҡеҲ¶еҢ– пјҢ дҪҶе®ҡеҲ¶еҢ–еңЁдә‘з«Ҝзҡ„йҖӮз”Ёз©әй—ҙдјҡзӣёеҜ№жңүйҷҗ пјҢ иҝҷжҳҜеҒҡдә‘з«ҜAIиҠҜзүҮзҡ„жүҖжңүе…¬еҸёе…ұеҗҢйқўдёҙзҡ„зӘҳеўғ гҖӮ
е…үеӯҗз®—ж•°дёәд»Җд№ҲйҖүжӢ©еҒҡжҲҗзғӯжҸ’жӢ”ж–№ејҸпјҹе®һйҷ…дёҠ пјҢ иҝҷжҳҜе°ҶйҖӮеҗҲз”Ёе…үеӯҰеҒҡзҡ„зү№е®ҡз®—еӯҗе°ҒиЈ…еҲ°е…үеӯҰжЁЎеқ—йҮҢ пјҢ йҖҡиҝҮзғӯжҸ’жӢ”жҺҘеҸЈе’ҢеӣҪеҶ…еӨ§еҺӮзҡ„еҠ йҖҹи®Ўз®—еҚЎжҸ’еңЁдёҖиө· пјҢ иҝҷз§ҚжҺҘеҸЈеҲ¶йғҪжҳҜжҲҗзҶҹзҡ„ пјҢ ејҖеҸ‘иҖ…дҪҝз”ЁеӨ§еҺӮзҡ„иҪҜ件е·Ҙе…· пјҢ еҚіеҸҜйҖҡиҝҮAPIи°ғз”Ёе…үеӯҗз®—ж•°зҡ„жЁЎеқ—еҶ…еөҢзү№е®ҡз®—еӯҗ гҖӮ йқўеҗ‘е…·дҪ“еә”з”Ё пјҢ ејҖеҸ‘иҖ…йҖҡиҝҮеӨ§еҺӮиҪҜ件е·Ҙе…· пјҢ ејҖеҸ‘з”ұе…үеӯҗз®—ж•°зҡ„е…үеӯҰз®—еӯҗдёҺеӨ§еҺӮеҺҹжңүзҡ„з”өеӯҰз®—еӯҗз»„жҲҗзҡ„е…үз”өж··еҗҲз®—жі•ж•ҙдҪ“ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…үеӯҗз®—ж•°еҜ№иҮӘе·ұзҡ„еёӮеңәе®ҡдҪҚжҳҜжҸҗдҫӣдј з»ҹеҠ йҖҹи®Ўз®—еҚЎзҡ„еҚҮзә§з»„件 пјҢ дҪҝдј з»ҹеҠ йҖҹи®Ўз®—еҚЎжҸҗеҚҮжҖ§иғҪгҖҒйҷҚдҪҺиғҪиҖ—гҖҒйҷҚдҪҺжҲҗжң¬ пјҢ дёҚеҸ—еҲ¶дәҺиҪҜ件е·Ҙе…· гҖӮ ж¶Ҳиҙ№иҖ…дҫқ然买еӨ§еҺӮзҡ„еҚЎе’Ңе·Ҙе…· пјҢ еҰӮйңҖеҚҮзә§ пјҢ еҚіеҸҜйҖүз”Ёе…үеӯҗз®—ж•°зҡ„жЁЎеқ— гҖӮ
зҷҪеҶ°жҸҗдәҶдёҖдёӘеҪўиұЎзҡ„жҜ”е–» пјҢ з”ЁдёҖеј дј з»ҹеҚЎеҠ дёҠе…үеӯҗеҚҸеӨ„зҗҶеј•ж“ҺжЁЎеқ—зҡ„ж•Ҳжһң пјҢ зӣёеҪ“дәҺз»ҷжұҪиҪҰй…ҚдәҶдёҖдёӘж¶ЎиҪ®еўһеҺӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дёүгҖҒз ”еҸ‘е®һж–Ҫи·Ҝеҫ„пјҡз®—жі•е…ҲиЎҢ пјҢ 硬件и·ҹиҝӣзҷҪеҶ°иҝҳи°ҲеҲ°е…ідәҺз ”еҸ‘и·Ҝзәҝзҡ„е»әи®® гҖӮ д»–д»¬з ”еҸ‘зҡ„еҶ…е®№жҳҜзі»з»ҹжҖ§е·ҘзЁӢ пјҢ зӣёиҫғдәҺи®ҫи®Ўж–°еһӢзҡ„е…үеӯҰи®Ўз®—еҚ•е…ғ пјҢ йҡҫеәҰжҳҜеҸҜд»Ҙе…ӢжңҚзҡ„ гҖӮ
жҺЁиҚҗйҳ…иҜ»











- иҚ·е…°дәәпјҡдёӯеӣҪдәәдёҚеҸҜжҖ•пјҢеҸҜжҖ•зҡ„жҳҜ他们ејҜйҒ“и¶…иҪҰз ”з©¶еҮәе…үеӯҗиҠҜзүҮ
- йӣҶжҲҗзЎ…е…үдј ж„ҹеҷЁж—¶д»ЈпјҢгҖҢж„ҸеӯҗдҝЎжҒҜгҖҚжғіз”Ёзәізұіе…үеӯҗжҷ¶дҪ“з»“еҗҲMEMSеҒҡеҮәдәҶжһҒй«ҳзІҫеәҰзҡ„е…үйҮҸеӯҗдј ж„ҹеҷЁ
- иҚ·е…°еӘ’дҪ“пјҡиҠҜзүҮзҰҒд»ӨеҜ№еҚҺдёәж•ҲжһңжңүйҷҗпјҢдёӯеӣҪе…үеӯҗиҠҜзүҮеҠ©еҚҺдёәи„ұзҰ»йҷ©еўғ
- ж—©зҲҶеЁұй—»|дёҚеҒҡз®—ж•°йўҳпјҒзҷҫзӣӣ11.11е…ЁзәҝйҖҒжғҠе–ң
- еҸҜи§Ғе…ү|е…үеӯҗд»ҘжҜҸз§’3дәҝзұіеҶІеҮ»дәәдҪ“пјҢдёәе•ҘжІЎж„ҹи§үпјҢе…үеӯҗиғҪжқҖдәәеҗ—пјҹ
- зҲұеӣ ж–ҜеқҰ|е…үеӯҗжҳҜз”Ёд»Җд№ҲвҖңеҠЁеҠӣвҖқзһ¬й—ҙиҫҫеҲ°е…үйҖҹзҡ„пјҹе…үеӯҗпјҡиғҪж…ўдёӢжқҘжүҚжҳҜй«ҳжүӢ
- е®Үе®ҷз©әй—ҙ|既然е…үеӯҗж°ёеӯҳпјҢдёәд»Җд№ҲеңЁе°Ғй—ӯзҡ„е®ӨеҶ…дёҖе…ізҒҜпјҢеұӢеӯҗе°ұй»‘дәҶпјҹ