即插即用,涨点明显!FPT:特征金字塔Transformer
 文章插图
文章插图
这篇文章收录于ECCV2020 , 将Transformer机制应用于对特征金字塔FPN的改进上 , 整体思路新颖 , 和之前的将Transformer应用于目标检测、语义分割、超分辨率等任务的思想相类似 , 是一个能够继续挖掘的方向 。 该论文解读首发于“AI算法修炼营” 。
作者 | SFXiang
编辑 | 青暮
 文章插图
文章插图
论文地址:
代码地址:
跨空间和尺度的特征交互是现代视觉识别系统的基础 , 因为它们引入了有益的视觉环境 。 通常空间上下文信息被动地隐藏在卷积神经网络不断增加的感受野中 , 或者被non-local卷积主动地编码 。 但是 , non-local空间交互作用并不是跨尺度的 , 因此它们无法捕获在不同尺度中的对象(或部分)的非局部上下文信息 。
为此 , 本文提出了一种在空间和尺度上完全活跃的特征交互 , 称为特征金字塔Transformer(FPT) 。 它通过使用三个专门设计的Transformer , 以自上而下和自下而上的交互方式 , 将任何一个特征金字塔变换成另一个同样大小但具有更丰富上下文的特征金字塔 。 FPT作为一个通用的视觉框架 , 具有合理的计算开销 。 最后 , 本文在实例级(即目标检测和实例分割)和像素级分割任务中进行了广泛的实验 , 使用不同的主干和头部网络 , 并观察到比所有baseline和最先进的方法一致的改进 。
1 简介
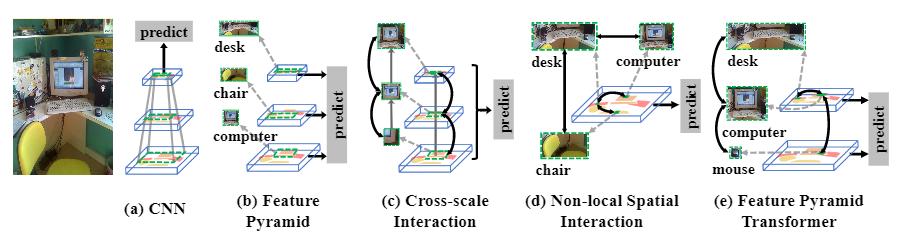
现代视觉识别系统与上下文息息相关 。 由于卷积神经网络(CNN)的层次结构 , 如图1(a)所示 , 通过pooling池化、stride或空洞卷积等操作 , 将上下文编码在逐渐变大的感受野(绿色虚线矩形)中 。 因此 , 对最后一个特征图的预测基本上是基于丰富的上下文信息 。
Scale also matters 。 尺度scale也很重要 , 传统的解决方案是对同一图像进行堆积多尺度的图像金字塔 , 其中较高/较低的层次采用较低/较高分辨率的图像进行输入 。 因此 , 不同尺度的物体在其相应的层次中被识别 。 然而 , 图像金字塔增加了CNN前向传递的耗时 , 因为每个图像都需要一个CNN来识别 。 幸运的是 , CNN提供了一种特征金字塔FPN , 即通过低/高层次的特征图代表高/低分辨率的视觉内容 , 而不需要额外的计算开销 。 如图1(b)所示 , 可以通过使用不同级别的特征图来识别不同尺度的物体 , 即小物体(电脑)在较低层级中识别 , 大物体(椅子和桌子)在较高层级中识别 。
 文章插图
文章插图
Sometimes the recognition——尤其是像语义分割这样的像素级标签 , 需要结合多个尺度的上下文 。 例如图1(c)中 , 要对显示的帧区域的像素赋予标签 , 也许从较低的层次上看 , 实例本身的局部上下文就足够了;但对于类外的像素 , 需要同时利用局部上下文和较高层次的全局上下文 。
为此 , 本文提出了一种称为特征金字塔转换器Transformer(FPT)的新颖特征金字塔网络 , 用于视觉识别任务 , 例如实例级(即目标检测和实例分割)和像素级分割任务 。 简而言之 , 如图2所示 , FPT的输入是一个特征金字塔 , 而输出是一个变换的金字塔 , 其中每个level都是一个更丰富的特征图 , 它编码了跨空间和尺度的非局部non-local交互作用 。 然后 , 可以将特征金字塔附加到任何特定任务的头部网络 。 顾名思义 , FPT中特征之间的交互采用了 transformer-style 。 它具有整洁的查询query , 键key和值value操作 , 在选择远程信息进行交互时非常有效 , 从而可以调整我们的目标:以适当的规模进行非局部non-local交互 。 另外 , 像其他任何transformer模型一样 , 使用TPU可以减轻计算开销 。