即插即用,涨点明显!FPT:特征金字塔Transformer( 三 )
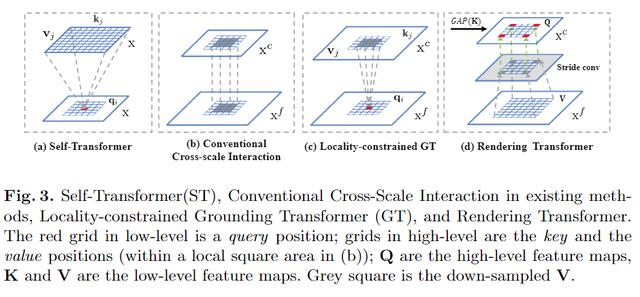
在特征金字塔中 , 高/低层次特征图包含大量全局/局部图像信息 。 然而 , 对于通过跨尺度特征交互的语义分割 , 没有必要使用全局信息来分割图像中的两个对象 。 从经验上讲 , 查询位置周围的局部区域内的上下文会提供更多信息 。 这就是为什么常规的跨尺度交互(例如求和和级联)在现有的分割方法中有效的原因 。 如图3(b)所示 , 它们本质上是隐式的局部non-local样式 , 但是本文的默认GT是全局交互的 。
 文章插图
文章插图
Locality-constrained Grounding Transformer 。 因此 , 作者引入了局域性GT转换进行语义分割 , 这是一个明确的局域特征交互作用 。 如图3(c)所示 , 每个q(即低层特征图上的红色网格)在中心区域的局部正方形区域内与k和v的一部分(即高层特征图上的蓝色网格)相互作用 。 坐标与q相同 , 边长为正方形 。 特别是 , 对于k和v超出索引的位置 , 改用0值 。
4、Rendering Transformer
Rendering Transformer(RT)以自下而上的方式工作 , 旨在通过将视觉属性合并到低层级“像素”中来渲染高层级“概念” 。 如图3(d)所示 , RT是一种局部交互 , 其中该局部是基于渲染具有来自另一个遥远对象的特征或属性的“对象”是没有意义的这一事实 。
在本文的实现中 , RT不是按像素进行的 , 而是按整个特征图进行的 。 具体来说 , 高层特征图定义为Q , 低层特征图定义为K和V , 为了突出渲染目标 , Q和K之间的交互是以通道导向的关注方式进行的 , K首先通过全局平均池化(GAP)计算出Q的权重w 。 然后 , 加权后的Q(即Qatt)通过3×3卷积进行优化 , V通过3×3卷积与步长来缩小特征规模(图3(d)中的灰色方块) 。 最后 , 将优化后的Qatt和下采样的V(即Vdow)相加 , 再经过一次3×3卷积进行细化处理 。
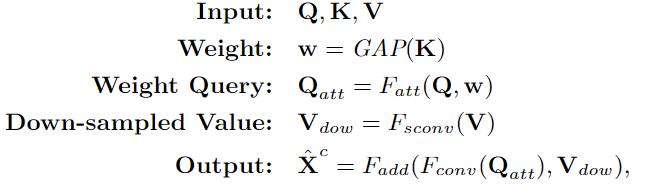 文章插图
文章插图
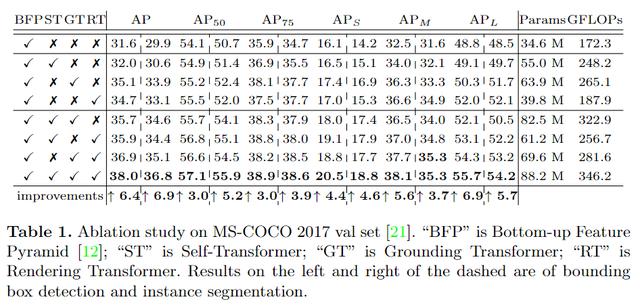
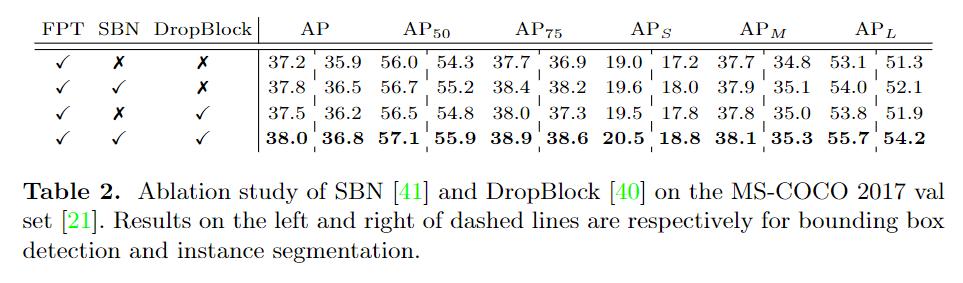
3 实验与结果
消融实验
 文章插图
文章插图
 文章插图
文章插图
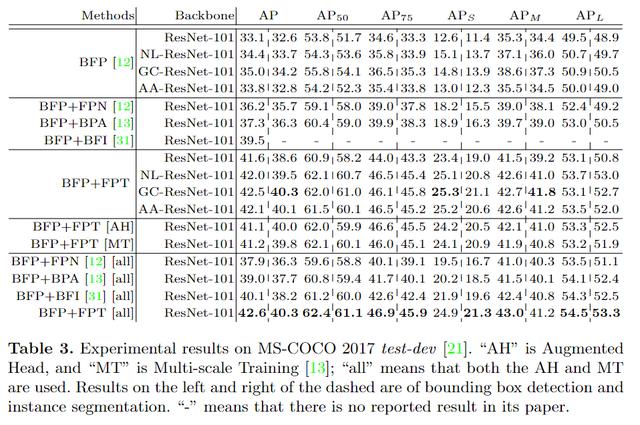
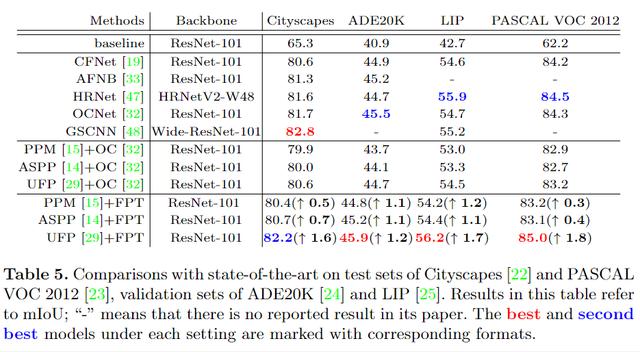
对比实验
 文章插图
文章插图
 文章插图
文章插图
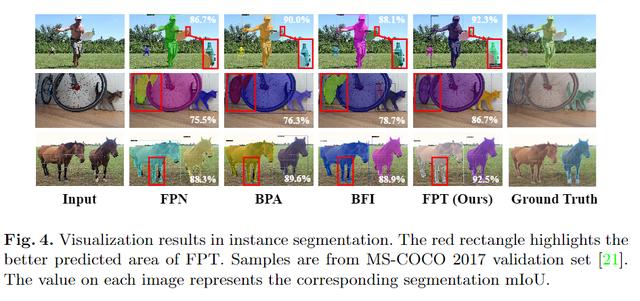
可视化对比
 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
NeurIPS 2020论文接收列表已出 , 欢迎大家投稿让更多的人了解你们的工作~
 文章插图
文章插图
 文章插图
文章插图







![[快科技]小米10青春版邀请函图赏:哆啦A梦迷你抓娃娃机](http://ttbs.guangsuss.com/image/3edcbb553cbab8a02c1d1c782772809f)






