爱可可AI论文推介(10月15日)( 二 )
 文章插图
文章插图
3、[AS]The Cone of Silence: Speech Separation by Localization
T Jenrungrot, V Jayaram, S Seitz, I Kemelmacher-Shlizerman
[University of Washington]
静默锥——结合方位的语音分离 , 提出一种新方法 , 在波形域进行定位和音源分离的联合处理 , 用网络分离特定角度区域的源 , 并用该网络进行二值搜索来分离和定位 。 可实现对任意数量说话者的泛化 , 包括训练中没见过的人 , 适用于真实场景的高水平噪声分离 。
Given a multi-microphone recording of an unknown number of speakers talking concurrently, we simultaneously localize the sources and separate the individual speakers. At the core of our method is a deep network, in the waveform domain, which isolates sources within an angular region θ±w/2, given an angle of interest θ and angular window size w. By exponentially decreasing w, we can perform a binary search to localize and separate all sources in logarithmic time. Our algorithm allows for an arbitrary number of potentially moving speakers at test time, including more speakers than seen during training. Experiments demonstrate state-of-the-art performance for both source separation and source localization, particularly in high levels of background noise.
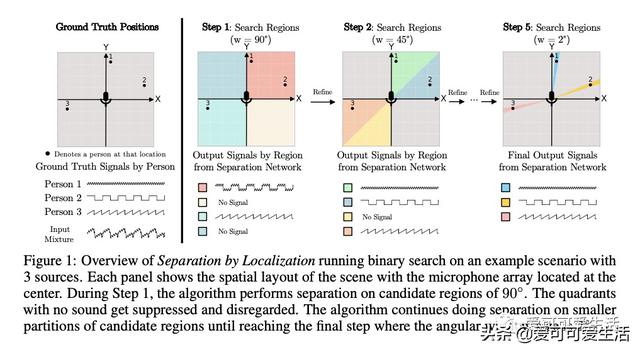 文章插图
文章插图
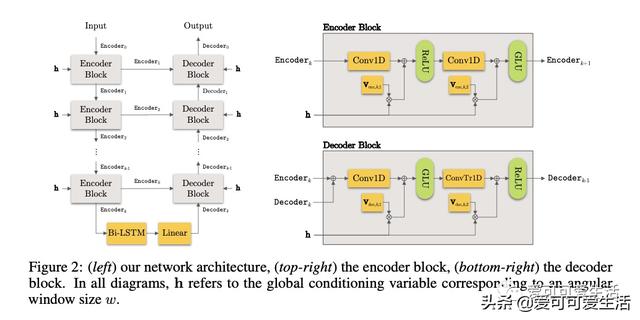 文章插图
文章插图
【爱可可AI论文推介(10月15日)】4、[CL]Embedding Words in Non-Vector Space with Unsupervised Graph Learning
M Ryabinin, S Popov, L Prokhorenkova, E Voita
[Yandex & University of Edinburgh]
无监督图学习非向量空间词嵌入 , 提出GraphGlove——无监督图词表示端到端学习 , 在GraphGlove中 , 每个词是加权图中的一个节点 , 词间距离就是对应节点间的最短路径 , 采用一种新方法来学习可微加权图形式数据表示 , 并修改GloVe训练算法 。 基于图的表示方法在词相似性和类比任务上大大优于基于向量的方法 。 GraphGlove具有层次结构(类似于WordNet)和高度非平凡的几何结构(包含不同的局部拓扑子图) 。
It has become a de-facto standard to represent words as elements of a vector space (word2vec, GloVe). While this approach is convenient, it is unnatural for language: words form a graph with a latent hierarchical structure, and this structure has to be revealed and encoded by word embeddings. We introduce GraphGlove: unsupervised graph word representations which are learned end-to-end. In our setting, each word is a node in a weighted graph and the distance between words is the shortest path distance between the corresponding nodes. We adopt a recent method learning a representation of data in the form of a differentiable weighted graph and use it to modify the GloVe training algorithm. We show that our graph-based representations substantially outperform vector-based methods on word similarity and analogy tasks. Our analysis reveals that the structure of the learned graphs is hierarchical and similar to that of WordNet, the geometry is highly non-trivial and contains subgraphs with different local topology.
推荐阅读


![[他人婚]被曝插足他人婚姻 《青你2》选手申冰退赛](https://img3.utuku.china.com/550x0/toutiao/20200326/5961a705-f613-40cd-b825-bc7656e59cfc.jpg)













- 谷歌:想发AI论文?请保证写的是正能量
- 谷歌对内部论文进行“敏感问题”审查!讲坏话的不许发
- 2019年度中国高质量国际科技论文数排名世界第二
- 谷歌通过启动敏感话题审查来加强对旗下科学家论文的控制
- Arxiv网络科学论文摘要11篇(2020-10-12)
- 聚焦城市治理新方向,5G+智慧城市推介会在长举行
- 中国移动5G新型智慧城市全国推介会在长沙举行
- 年年都考的数字鸿沟有了新进展?彭波老师的论文给出了解答!
- 打开深度学习黑箱,牛津大学博士小姐姐分享134页毕业论文
- 爱可可AI论文推介(10月9日)