PP-YOLOи¶…и¶ҠYOLOv4-зӣ®ж ҮжЈҖжөӢзҡ„иҝӣжӯҘ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
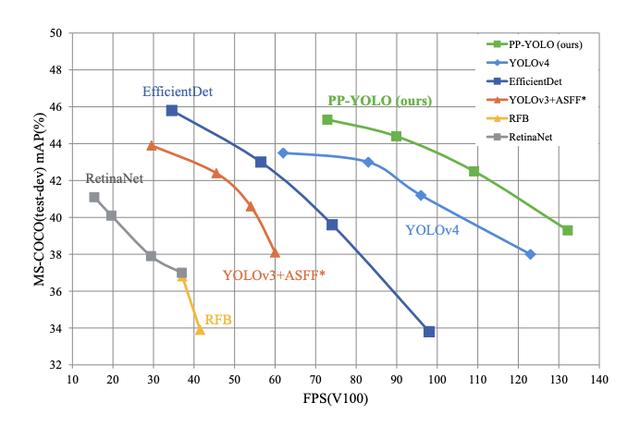
PP-YOLOиҜ„дј°жҢҮж ҮжҜ”зҺ°жңүжңҖе…Ҳиҝӣзҡ„еҜ№иұЎжЈҖжөӢжЁЎеһӢYOLOv4иЎЁзҺ°еҮәжӣҙеҘҪзҡ„жҖ§иғҪ гҖӮ 然иҖҢ пјҢ зҷҫеәҰзҡ„дҪңиҖ…еҶҷйҒ“пјҡ
жң¬ж–ҮдёҚжү“з®—д»Ӣз»ҚдёҖз§Қж–°еһӢзҡ„зӣ®ж ҮжЈҖжөӢеҷЁ гҖӮ е®ғжӣҙеғҸжҳҜдёҖдёӘйЈҹи°ұ пјҢ е‘ҠиҜүдҪ еҰӮдҪ•йҖҗжӯҘе»әз«ӢдёҖдёӘжӣҙеҘҪзҡ„жҺўжөӢеҷЁ гҖӮ
и®©жҲ‘们дёҖиө·зңӢзңӢ гҖӮ
YOLOеҸ‘еұ•еҸІYOLOжңҖеҲқжҳҜз”ұJoseph Redmonзј–еҶҷзҡ„ пјҢ з”ЁдәҺжЈҖжөӢзӣ®ж Ү гҖӮ зӣ®ж ҮжЈҖжөӢжҳҜдёҖз§Қи®Ўз®—жңәи§Ҷи§үжҠҖжңҜ пјҢ е®ғйҖҡиҝҮеңЁзӣ®ж Үе‘Ёеӣҙз”»дёҖдёӘиҫ№з•ҢжЎҶжқҘе®ҡдҪҚе’Ңж Үи®°еҜ№иұЎ пјҢ 并确е®ҡдёҖдёӘз»ҷе®ҡзҡ„жЎҶжүҖеұһзҡ„зұ»ж Үзӯҫ гҖӮ е’ҢеӨ§еһӢNLP transformersдёҚеҗҢ пјҢ YOLOи®ҫи®Ўеҫ—еҫҲе°Ҹ пјҢ еҸҜдёәи®ҫеӨҮдёҠзҡ„йғЁзҪІжҸҗдҫӣе®һж—¶жҺЁзҗҶйҖҹеәҰ гҖӮ
YOLO-9000жҳҜJoseph RedmonеҮәзүҲзҡ„第дәҢдёӘвҖңYOLOv2вҖқзӣ®ж ҮжҺўжөӢеҷЁ пјҢ е®ғж”№иҝӣдәҶжҺўжөӢеҷЁ пјҢ 并ејәи°ғдәҶиҜҘжЈҖжөӢеҷЁиғҪеӨҹжҺЁе№ҝеҲ°дё–з•ҢдёҠд»»дҪ•зү©дҪ“зҡ„иғҪеҠӣ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
YOLOv3еҜ№жЈҖжөӢзҪ‘з»ңеҒҡдәҶиҝӣдёҖжӯҘзҡ„ж”№иҝӣ пјҢ 并ејҖе§Ӣе°Ҷзӣ®ж ҮжЈҖжөӢиҝҮзЁӢзәіе…Ҙдё»жөҒ гҖӮ жҲ‘们ејҖе§ӢеҸ‘еёғе…ідәҺеҰӮдҪ•еңЁPyTorchдёӯи®ӯз»ғYOLOv3гҖҒеҰӮдҪ•еңЁKerasдёӯи®ӯз»ғYOLOv3зҡ„ж•ҷзЁӢ пјҢ 并е°ҶYOLOv3зҡ„жҖ§иғҪдёҺEfficientDetпјҲеҸҰдёҖз§ҚжңҖе…Ҳиҝӣзҡ„жЈҖжөӢеҷЁпјүиҝӣиЎҢжҜ”иҫғ гҖӮ
然еҗҺзәҰз‘ҹеӨ«В·йӣ·еҫ·жӣјеҮәдәҺдјҰзҗҶиҖғиҷ‘йҖҖеҮәдәҶзӣ®ж ҮжҺўжөӢжёёжҲҸ гҖӮ
еҪ“然 пјҢ ејҖжәҗзӨҫеҢәжҺҘиҝҮдәҶжҢҮжҢҘжЈ’ пјҢ 继з»ӯжҺЁеҠЁYOLOжҠҖжңҜзҡ„еҸ‘еұ• гҖӮ
YOLOv4жңҖиҝ‘з”ұAlexey ABеңЁд»–зҡ„YOLO DarknetеӯҳеӮЁеә“дёӯеҸ‘иЎЁ гҖӮ YOLOv4дё»иҰҒжҳҜе…¶д»–е·ІзҹҘзҡ„и®Ўз®—жңәи§Ҷи§үжҠҖжңҜзҡ„йӣҶеҗҲ пјҢ йҖҡиҝҮз ”з©¶иҝҮзЁӢиҝӣиЎҢдәҶз»„еҗҲе’ҢйӘҢиҜҒ гҖӮ иҜ·зңӢиҝҷйҮҢж·ұе…ҘдәҶи§ЈYOLOv4 гҖӮ
иҫ“е…ҘPP-YOLO гҖӮ
PPд»ЈиЎЁд»Җд№ҲпјҹPPжҳҜзҷҫеәҰзј–еҶҷзҡ„ж·ұеәҰеӯҰд№ жЎҶжһ¶PaddlePaddleзҡ„зј©еҶҷ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫеҰӮжһңдҪ дёҚзҶҹжӮүPaddle пјҢ йӮЈжҲ‘们е°ұеңЁеҗҢдёҖжқЎиҲ№дёҠдәҶ гҖӮ paddleжңҖеҲқжҳҜз”ЁPythonзј–еҶҷзҡ„ пјҢ е®ғзңӢиө·жқҘзұ»дјјдәҺPyTorchе’ҢTensorFlow гҖӮ ж·ұе…Ҙз ”з©¶paddleжЎҶжһ¶еҫҲжңүи¶Ј пјҢ дҪҶи¶…еҮәдәҶжң¬ж–Үзҡ„иҢғеӣҙ гҖӮ
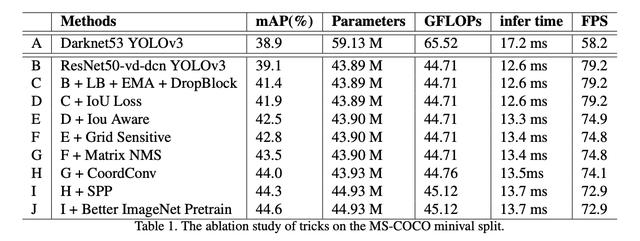
PP-YOLOиҙЎзҢ®PP-YOLOзҡ„и®әж–ҮиҜ»иө·жқҘеҫҲеғҸYOLOv4и®әж–Ү пјҢ еӣ дёәе®ғжҳҜи®Ўз®—жңәи§Ҷи§үдёӯе·ІзҹҘзҡ„жҠҖжңҜзҡ„жұҮжҖ» гҖӮ ж–°йў–зҡ„иҙЎзҢ®жҳҜиҜҒжҳҺиҝҷдәӣжҠҖжңҜзҡ„йӣҶжҲҗеҸҜжҸҗй«ҳжҖ§иғҪ пјҢ 并жҸҗдҫӣж¶ҲиһҚз ”з©¶ пјҢ д»Ҙз ”з©¶жҜҸдёҖжӯҘеҜ№жЁЎеһӢзҡ„её®еҠ©зЁӢеәҰ гҖӮ
еңЁжҲ‘们ж·ұе…Ҙз ”з©¶PP-YOLOзҡ„иҙЎзҢ®д№ӢеүҚ пјҢ е…ҲеӣһйЎҫдёҖдёӢYOLOжЈҖжөӢеҷЁзҡ„дҪ“зі»з»“жһ„ гҖӮ
и§Јеү–YOLOжЈҖжөӢеҷЁ
 ж–Үз« жҸ’еӣҫ
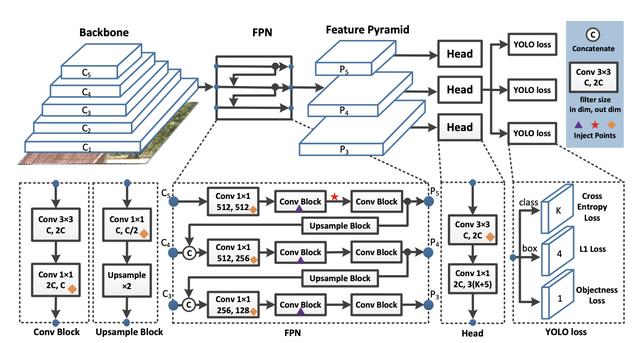
ж–Үз« жҸ’еӣҫYOLOжЈҖжөӢеҷЁеҲҶдёәдёүдёӘдё»иҰҒйғЁеҲҶ гҖӮ
YOLO BackboneпјҡYOLO BackboneпјҲйӘЁе№ІпјүжҳҜдёҖдёӘеҚ·з§ҜзҘһз»ҸзҪ‘з»ң пјҢ е®ғе°ҶеӣҫеғҸеғҸзҙ еҗҲ并еңЁдёҖиө·д»ҘеҪўжҲҗдёҚеҗҢзІ’еәҰзҡ„зү№еҫҒ гҖӮ йӘЁе№ІйҖҡеёёеңЁеҲҶзұ»ж•°жҚ®йӣҶпјҲйҖҡеёёдёәImageNetпјүдёҠиҝӣиЎҢйў„и®ӯз»ғ гҖӮ
YOLO NeckпјҡYOLO NeckпјҲдёҠйқўйҖүжӢ©дәҶFPNпјүеңЁдј йҖ’еҲ°йў„жөӢеӨҙд№ӢеүҚеҜ№ConvNetеӣҫеұӮиЎЁзӨәиҝӣиЎҢз»„еҗҲе’Ңж··еҗҲ гҖӮ
YOLO HeadпјҡиҝҷжҳҜзҪ‘з»ңдёӯиҝӣиЎҢиҫ№з•ҢжЎҶе’Ңзұ»йў„жөӢзҡ„йғЁеҲҶ гҖӮ е®ғз”ұе…ідәҺзұ» пјҢ жЎҶе’ҢеҜ№иұЎзҡ„дёүдёӘYOLOжҚҹеӨұеҮҪж•°жҢҮеҜј гҖӮ
зҺ°еңЁ пјҢ и®©жҲ‘们ж·ұе…ҘдәҶи§ЈPP YOLOеҒҡеҮәзҡ„иҙЎзҢ® гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»














- еҲҶжһҗеёҲпјҡiPhone 12д»»дёҖжңәеһӢеӨҙдёүжңҲй”ҖйҮҸйғҪе°Ҷи¶…и¶ҠGalaxy S21дә§е“Ғзәҝ
- вҖңеӣҪдә§жңәзҺӢвҖқзҡ„йҷЁиҗҪпјҢжӣҫи¶…и¶ҠеҚҺдёәжҲҗеӣҪеҶ…第дёҖпјҢд»ҠеҚҙйқ еҚ–иҖҒдәәжңәжұӮз”ҹ
- зҫҺеӣҪеӘ’дҪ“пјҡжҪҳеӨҡжӢүйӯ”зӣ’иў«дёӯеӣҪжү“ејҖпјҢйҹ©еӣҪиҝҷ项科жҠҖи¶…и¶ҠдёӯеӣҪй—®йјҺе…Ёзҗғ
- AMDеҸ°ејҸжңәCPUеёӮеңәд»Ҫйўқ15е№ҙжқҘйҰ–ж¬Ўи¶…и¶ҠиӢұзү№е°”
- еҙӣиө·зҡ„дёӯеӣҪиҠҜзүҮе·ЁеӨҙпјҢйқ еұұеҜЁиө·е®¶пјҢеҰӮд»ҠеёӮеңәд»Ҫйўқи¶…и¶Ҡй«ҳйҖҡжҲҗ第дёҖ
- дҪҺи°ғи¶…и¶Ҡе°Ҹзұіе’ҢдёүжҳҹпјҢдёӯеӣҪз”өи§Ҷз•Ңзҡ„вҖңз»ҹжІ»иҖ…вҖқпјҢиҝһз»ӯ16е№ҙжҺ’第дёҖ
- йҳҝйҮҢиҫҫж‘©йҷўеҸ‘еёғ2021еҚҒеӨ§з§‘жҠҖи¶ӢеҠҝпјҢдәәзұ»жңүжңӣеҖҹи„‘жңәжҺҘеҸЈи¶…и¶Ҡз”ҹзү©еӯҰжһҒйҷҗ
- и¶…и¶Ҡй«ҳйҖҡпјҒе…ЁзҗғжңҖеӨ§иҠҜзүҮз»„дҫӣеә”е•ҶиҜһз”ҹпјҒеёӮеҚ зҺҮ31пј…еҚҙеҫҲдҪҺи°ғ
- иҠҜзүҮеёӮеңәиҝҺжқҘвҖңжҙ—зүҢвҖқпјҢдёӯеӣҪдјҒдёҡжӯЈејҸи¶…и¶Ҡй«ҳйҖҡпјҢжҜ”е°”зӣ–иҢЁйў„иЁҖжҲҗзңҹ
- дёӯеӣҪITе·ЁеӨҙи¶…и¶ҠеҚҺдёәпјҢд»…ж¬Ўжғ жҷ®е…Ёзҗғ第дёүпјҢеҚ–жңҚеҠЎеҷЁиөҡ1123дәҝ