еҝ«йҖҹе…Ҙй—ЁElasticSearchпјҲдёҠпјү( дёү )
еҰӮжһңеҮәзҺ°дёӢйқўзҡ„й”ҷиҜҜпјҡ
failed to send join request to master [{master}{4f6DA5uJQ8iJokZ3T18gjg}{2dOtfXXbTrynhShWrzt3xQ}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=8374956032, ml.max_open_jobs=20, xpack.installed=true, ml.enabled=true}], reason [RemoteTransportException[[master][127.0.0.1:9300]йӮЈжҳҜеӣ дёәд№ӢеүҚеӨҚеҲ¶ElasticSearchж–Ү件时 пјҢ е°Ҷе…¶dataзӣ®еҪ•дёӢзҡ„ж–Ү件д№ҹдёҖеҗҢеӨҚеҲ¶дәҶ пјҢ еӣ жӯӨйңҖиҰҒжё…з©әdataж–Ү件еӨ№ пјҢ 然еҗҺеҶҚиҝӣиЎҢйҮҚиҜ•еҚіеҸҜ гҖӮ
ElasticSearchеҹәзЎҖжҰӮеҝөйҰ–е…ҲжҳҜйӣҶзҫӨе’ҢиҠӮзӮ№зҡ„жҰӮеҝө пјҢ жҲ‘们зҹҘйҒ“йӣҶзҫӨжҳҜз”ұдёҖдёӘжҲ–еӨҡдёӘиҠӮзӮ№з»„жҲҗзҡ„ пјҢ еҰӮеүҚйқўжҲ‘们жҗӯе»әзҡ„е…·жңүдёүдёӘиҠӮзӮ№зҡ„йӣҶзҫӨ пјҢ е…¶й»ҳи®ӨеҗҚз§°дёәElasticSearch пјҢ дҪҶжҳҜеүҚйқўжҲ‘们йҖҡиҝҮcluster.nameеҸӮж•°е°Ҷе…¶дҝ®ж”№дёәenvythink гҖӮ иҜ·жіЁж„ҸеҜ№дәҺд»»ж„ҸдёҖдёӘиҠӮзӮ№жқҘиҜҙ пјҢ е…¶йӣҶзҫӨзҡ„еҗҚеӯ—еҸӘиғҪжңүдёҖдёӘ пјҢ е®һйҷ…дёҠжүҖжңүзҡ„иҠӮзӮ№йғҪжҳҜйқ иҝҷдёӘйӣҶзҫӨзҡ„еҗҚз§°жқҘеҠ е…ҘйӣҶзҫӨзҡ„ гҖӮ жӯӨеӨ–жҜҸдёӘиҠӮзӮ№йғҪжңүиҮӘе·ұзҡ„еҗҚеӯ— пјҢ еҸҜд»ҘйҖҡиҝҮnode.nameжқҘиҮӘе®ҡд№ү пјҢ еҗҢж—¶иҠӮзӮ№йғҪжҳҜеҸҜд»ҘеӯҳеӮЁж•°жҚ® пјҢ еҸӮдёҺйӣҶзҫӨзҙўеј•ж•°жҚ® пјҢ д»ҘеҸҠжҗңзҙўж•°жҚ®зҡ„зӢ¬з«ӢжңҚеҠЎ гҖӮ е…¶ж¬ЎжҳҜзҙўеј• пјҢ дҪ еҸҜд»Ҙе°Ҷе…¶зҗҶи§ЈдёәжҳҜеҗ«жңүзӣёеҗҢеұһжҖ§зҡ„ж–ҮжЎЈйӣҶеҗҲ гҖӮ жҺҘзқҖжҳҜзұ»еһӢ пјҢ дёҖиҲ¬жқҘиҜҙзҙўеј•еҸҜд»Ҙе®ҡд№үдёҖдёӘжҲ–иҖ…еӨҡдёӘзұ»еһӢ пјҢ дҪҶжҳҜж–ҮжЎЈеҝ…йЎ»жҳҜеұһдәҺдёҖдёӘзұ»еһӢ гҖӮ йӮЈд№Ҳй—®йўҳжқҘдәҶ пјҢ ж–ҮжЎЈеҸҲжҳҜд»Җд№Ҳе‘ўпјҹж–ҮжЎЈе°ұжҳҜеҸҜд»Ҙиў«зҙўеј•зҡ„еҹәжң¬ж•°жҚ®еҚ•дҪҚ пјҢ еҰӮз”ЁжҲ·зҡ„дёӘдәәдҝЎжҒҜ пјҢ е®ғжҳҜElasticSearchдёӯжңҖеҹәжң¬зҡ„еӯҳеӮЁеҚ•дҪҚ гҖӮ зҙўеј•еңЁElasticSearchдёӯжҳҜйҖҡиҝҮеҗҚеӯ—жқҘиҜҶеҲ«зҡ„ пјҢ дё”е®ғеҝ…йЎ»жҳҜиӢұж–Үеӯ—жҜҚе°ҸеҶҷ пјҢ дё”дёҚеҗ«дёӯеҲ’зәҝ пјҢ жҲ‘们йғҪжҳҜйҖҡиҝҮеҗҚеӯ—жқҘеҜ№ж–ҮжЎЈж•°жҚ®иҝӣиЎҢеўһеҲ ж”№жҹҘзӯүж“ҚдҪң гҖӮ
е…ідәҺзҙўеј•гҖҒзұ»еһӢе’Ңж–ҮжЎЈиҝҷдёүиҖ…д№Ӣй—ҙзҡ„е…ізі» пјҢ еҸҜд»ҘеҖҹйүҙж•°жҚ®еә“зҡ„зӣёе…ізҹҘиҜҶ пјҢ е°Ҷзҙўеј•зұ»жҜ”дёәж•°жҚ®еә“пјӣзұ»еһӢзұ»жҜ”дёәж•°жҚ®иЎЁпјӣиҖҢж–ҮжЎЈе°ұжҳҜдёҖиЎҢSQLи®°еҪ• гҖӮ еҶҚжқҘдёҫдёҖдёӘиҫғдёәиҜҰз»Ҷзҡ„зі»з»ҹ пјҢ еҒҮи®ҫжҲ‘们иҝҷйҮҢжңүдёҖдёӘдҝЎжҒҜжҹҘиҜўзі»з»ҹ пјҢ жӯӨеӨ„дҪҝз”ЁElasticSearchжқҘдҪңеӯҳеӮЁ пјҢ йӮЈд№ҲйҮҢйқўзҡ„ж•°жҚ®е°ұеҸҜд»ҘеҲҶдёәеҗ„з§Қеҗ„ж ·зҡ„зҙўеј• пјҢ еҰӮеӣҫд№Ұзҙўеј• пјҢ жңҚиЈ…зҙўеј• пјҢ з”өеҷЁзҙўеј•зӯү пјҢ иҖҢеҜ№дәҺеӣҫд№Ұзҙўеј•еҸҲеҸҜд»Ҙз»ҶеҲҶдёәж–ҮеӯҰзұ»гҖҒе·Ҙе…·зұ»гҖҒжҠҖжңҜзұ»зӯүзұ»еһӢ пјҢ иҖҢе…·дҪ“еҲ°жҜҸдёҖжң¬д№ҰзұҚеҲҷе°ұжҳҜж–ҮжЎЈ пјҢ д№ҹе°ұжҳҜжңҖе°Ҹзҡ„еӯҳеӮЁеҚ•дҪҚ гҖӮ
е’Ңзҙўеј•зӣёе…іиҝҳжңүдёӨдёӘжҜ”иҫғйҮҚиҰҒзҡ„жҰӮеҝөе°ұжҳҜеҲҶзүҮе’ҢеӨҮд»Ҫ гҖӮ жҜҸдёӘзҙўеј•йғҪжңүеӨҡдёӘеҲҶзүҮ пјҢ жҜҸдёӘеҲҶзүҮе°ұжҳҜдёҖдёӘLuceneзҙўеј• гҖӮ иҖҢжӢ·иҙқдёҖд»ҪеҲҶзүҮе°ұе®ҢжҲҗдәҶеҲҶзүҮзҡ„еӨҮд»Ҫ гҖӮ дҪҝз”ЁеҲҶзүҮеҸҜд»Ҙе°Ҷзҙўеј•иҝӣиЎҢжӢҶеҲҶ пјҢ еҸҜд»ҘеҲҶжӢ…жҜҸдёҖдёӘзҙўеј•дёҠзҡ„еҺӢеҠӣ пјҢ еҗҢж—¶еҲҶзүҮиҝҳе…Ғи®ёз”ЁжҲ·иҝӣиЎҢж°ҙе№іжү©еұ•е’ҢжӢҶеҲҶ пјҢ д»ҘеҸҠеҲҶеёғејҸзҡ„ж“ҚдҪң пјҢ еҸҜд»ҘжҸҗй«ҳжҗңзҙўд»ҘеҸҠе…¶д»–ж“ҚдҪңзҡ„ж•ҲзҺҮ гҖӮ дҪҝз”ЁеӨҮд»Ҫзҡ„еҘҪеӨ„е°ұжҳҜеҪ“дёҖдёӘдё»еҲҶзүҮеҮәзҺ°й—®йўҳж—¶ пјҢ еӨҮд»Ҫзҡ„еҲҶзүҮе°ұеҸҜд»Ҙд»Јжӣҝе·ҘдҪң пјҢ д»ҺиҖҢжҸҗй«ҳдәҶElasticSearchзҡ„еҸҜз”ЁжҖ§ пјҢ еҗҢж—¶еӨҮд»Ҫзҡ„еҲҶзүҮд№ҹж”ҜжҢҒжҗңзҙўж“ҚдҪң пјҢ еҸҜд»ҘеҮҸиҪ»жҗңзҙўзҡ„еҺӢеҠӣ гҖӮ ElasticSearchй»ҳи®ӨеңЁеҲӣе»әзҙўеј•ж—¶ пјҢ дјҡеҲӣе»ә5дёӘеҲҶзүҮ пјҢ дёҖдёӘз”ЁдәҺеӨҮд»Ҫ пјҢ еҪ“然иҝҷдёӘж•°жҚ®д№ҹжҳҜеҸҜд»Ҙдҝ®ж”№зҡ„ гҖӮ жӯӨеӨ–еҲҶзүҮзҡ„ж•°йҮҸеҸӘиғҪеңЁеҲӣе»әзҙўеј•зҡ„ж—¶еҖҷжҢҮе®ҡ пјҢ иҖҢдёҚиғҪеңЁеҗҺжңҹиҝӣиЎҢдҝ®ж”№ пјҢ дҪҶжҳҜеӨҮд»ҪеҚҙжҳҜеҸҜд»ҘеҠЁжҖҒдҝ®ж”№зҡ„ гҖӮ
ElasticSearchеҹәжң¬з”Ёжі•з”ұдәҺElasticSearchдҪҝз”Ёзҡ„жҳҜRESTfulйЈҺж јзҡ„API пјҢ еӣ жӯӨеңЁеӯҰд№ ElasticSearchзҡ„еҹәжң¬з”Ёжі•д№ӢеүҚ пјҢ йңҖиҰҒдәҶи§ЈElasticSearchдёӯAPIзҡ„еҹәжң¬ж јејҸпјҡhttp://
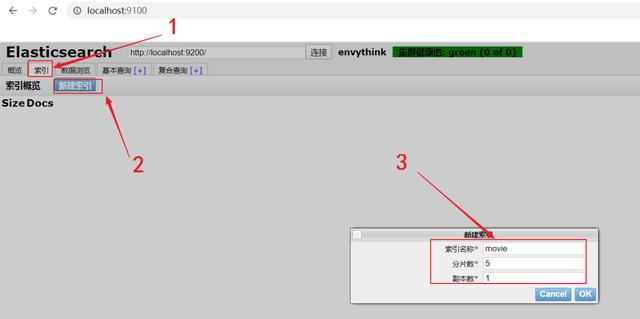
еҲӣе»әзҙўеј•жҺҘдёӢжқҘеҸҜд»Ҙз»“еҗҲд№ӢеүҚзҡ„HeadжҸ’件жқҘжҳҫејҸеҲӣе»әзҙўеј• пјҢ зӮ№еҮ»е·ҰдёҠи§’зҡ„зҙўеј•-->еҲӣе»әзҙўеј•-->еЎ«е…Ҙж•°жҚ®-->зӮ№еҮ»зЎ®е®ҡпјҲжіЁж„ҸиҝҷйҮҢзҡ„movieжҳҜзҙўеј•еҗҚз§° пјҢ еҝ…йЎ»жҳҜиӢұж–Үе°ҸеҶҷ пјҢ дё”дёҚиғҪдҪҝз”ЁдёӯеҲ’зәҝпјүпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
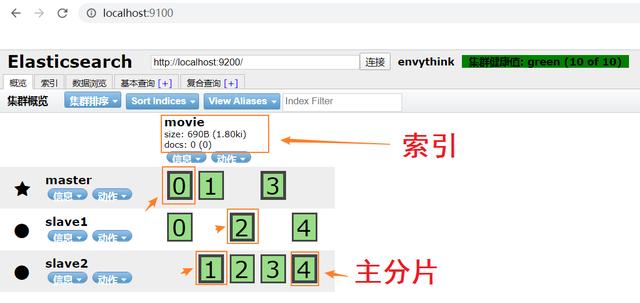
д№ӢеҗҺеӣһеҲ°йҰ–йЎө пјҢ еҸҜд»ҘзңӢеҲ°йЎөйқўеҮәзҺ°дәҶ10дёӘз»ҝеә•й»‘еӯ—зҡ„ж–№жЎҶ пјҢ иҝҷдәӣйғҪжҳҜElasticSearchзҡ„еҲҶзүҮ пјҢ еҰӮдёӢжүҖзӨәпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»


![[дә®еү‘еҗӣ]жҖҖжүҚдёҚйҒҮпјҢз»Ҳиў«жҲ‘еӣҪиөҸиҜҶпјҢиҝҷдҪҚзҫҺеӣҪж•ҷжҺҲдёәжҲ‘еӣҪеӨ©зҪ‘иҙЎзҢ®е·ЁеӨ§пјҒпјҢ](https://imgcdn.toutiaoyule.com/20200402/20200402010437473463a_t.jpeg)













- иӢ№жһңдёӨж¬ҫж–°iPadйҪҗжӣқе…үпјҡжҖ§иғҪжҸҗй«ҳгҖҒе…Ҙй—Ёж¬ҫжӣҙиҪ»и–„гҖҒе”®д»·дҫҝе®ң
- вҖңеҚғеә—еҗҢејҖвҖқеј•иҙЁйҮҸжӢ…еҝ§пјҢе°Ҹзұіеӣһеә”
- RHEL 9жҸҗеҚҮдәҶx86_64еӨ„зҗҶеҷЁзҡ„е…Ҙй—ЁиҰҒжұӮ
- дјҒдёҡ|жҠҖжңҜеҝ«йҖҹиҝӯд»ЈеҖ’йҖјзҹҘиҜҶдә§жқғвҖңиҙҙиә«вҖқжңҚеҠЎпјҢдёҠжө·йҰ–家AIе•Ҷж Үе“ҒзүҢжҢҮеҜјз«ҷе…Ҙй©»еҫҗжұҮиҘҝеІё
- дёүжҳҹGalaxy A52 5GйҖҡиҝҮ3Cи®ӨиҜҒ ж”ҜжҢҒжңҖй«ҳ15Wеҝ«йҖҹе……з”ө
- е…Ҙй—ЁHiFiдә«еҘҪеЈ°пјҢиҝҷеҮ ж¬ҫиҖіжңәз»қеҜ№еҖјеҫ—е…ҘжүӢ
- еӨ§еҒҘеә·йҖҹйҖ’дёЁи…ҫи®ҜдёҠзәҝз–«иӢ—жҺҘз§ҚжңҚеҠЎеҢәпјӣеҚҺеӨ§еҹәеӣ з ”еҸ‘еҮәеҝ«йҖҹйүҙе®ҡзӣ’
- DIYд»Һе…Ҙй—ЁеҲ°ж”ҫејғпјҡз”өжәҗжҢ‘иҙөзҡ„д№°е°ұйқ и°ұеҗ—пјҹ
- е°ҸзұіиҒ”еҗҲдә¬дёңеҸҠзҲұеӣһ收жҺЁе…Ёж–°жҚўжңәжңҚеҠЎ её®дҪ еҝ«йҖҹжҚўж–°жңә
- иҘҝе®үеҘ•ж–ҜдјҹзЎ…дә§дёҡеҹәең°йЎ№зӣ®е»әи®ҫеҲ·ж–°жҲ‘еӣҪе»әи®ҫеӨ§зЎ…зүҮеҲ¶йҖ йЎ№зӣ®зҡ„жңҖеҝ«йҖҹеәҰ