еҹәдәҺзҘһз»ҸзҪ‘з»ңзҡ„йЈҺж јиҝҒ移зӣ®ж ҮжҚҹеӨұи§Јжһҗ( дәҢ )
жүҖд»Ҙиҝҷж„Ҹе‘ізқҖж·ұеәҰеӯҰд№ ж–№жі•зҡ„зү№зӮ№еңЁдәҺжҸҗеҸ–еӣҫеғҸзҡ„йЈҺж ј пјҢ иҖҢдёҚд»…д»…жҳҜйҖҡиҝҮеҜ№йЈҺж јеӣҫеғҸзҡ„еғҸзҙ и§ӮеҜҹ пјҢ иҖҢжҳҜе°Ҷйў„е…Ҳи®ӯз»ғеҘҪзҡ„жЁЎеһӢжҸҗеҸ–зҡ„зү№еҫҒдёҺйЈҺж јеӣҫеғҸзҡ„еҶ…е®№зӣёз»“еҗҲ гҖӮ еӣ жӯӨ пјҢ д»Һжң¬иҙЁдёҠиҜҙ пјҢ иҰҒеҸ‘зҺ°дёҖдёӘеӣҫеғҸзҡ„йЈҺж ј пјҢ womenxuyao йҖҡиҝҮеҲҶжһҗе…¶еғҸзҙ жқҘеӨ„зҗҶйЈҺж јеӣҫеғҸ并е°ҶжӯӨдҝЎжҒҜжҸҗдҫӣз»ҷйў„е…Ҳи®ӯз»ғиҝҮзҡ„жЁЎеһӢеұӮ пјҢ д»Ҙдҫҝе°ҶжҸҗдҫӣзҡ„иҫ“е…Ҙ"зҗҶи§Ј"/еҲҶзұ»дёәеҜ№иұЎ
еҰӮдҪ•еҒҡеҲ°иҝҷдёҖзӮ№ пјҢ жҲ‘们е°ҶеңЁдёӢйқўдёҖиҠӮдёӯжҺўи®Ё гҖӮ
йЈҺж је’ҢеҶ…е®№еҹәжң¬жҖқжғіжҳҜе°ҶеӣҫеғҸзҡ„йЈҺж јиҪ¬жҚўдёәеӣҫеғҸзҡ„еҶ…е®№ гҖӮ
еӣ жӯӨ пјҢ жҲ‘们йңҖиҰҒдәҶи§ЈдёӨ件дәӢпјҡ
В· еӣҫзүҮзҡ„еҶ…е®№жҳҜд»Җд№Ҳ
В· еӣҫеғҸзҡ„йЈҺж јжҳҜд»Җд№Ҳ
жқҫж•Јең°иҜҙ пјҢ еӣҫеғҸзҡ„еҶ…е®№жҳҜжҲ‘们дәәзұ»иҜҶеҲ«дёәеӣҫеғҸдёӯзҡ„еҜ№иұЎзҡ„дёңиҘҝ гҖӮжұҪиҪҰ пјҢ жЎҘжўҒ пјҢ жҲҝеұӢзӯү гҖӮ йЈҺж јеҫҲйҡҫе®ҡд№ү гҖӮиҝҷеңЁеҫҲеӨ§зЁӢеәҰдёҠеҸ–еҶідәҺеӣҫеғҸ гҖӮе®ғжҳҜж•ҙдҪ“зә№зҗҶ пјҢ йўңиүІйҖүжӢ© пјҢ еҜ№жҜ”еәҰзӯү гҖӮ
иҝҷдәӣе®ҡд№үйңҖиҰҒд»Ҙж•°еӯҰж–№ејҸиЎЁиҫҫ пјҢ д»ҘдҫҝеңЁжңәеҷЁеӯҰд№ йўҶеҹҹдёӯе®һзҺ° гҖӮ
жҚҹеӨұеҮҪж•°зҡ„и®Ўз®—йҰ–е…Ҳ пјҢ дёәд»Җд№ҲиҰҒи®Ўз®—д»Јд»·/жҚҹеӨұпјҹйҮҚиҰҒзҡ„жҳҜиҰҒзҗҶи§Ј пјҢ еңЁиҝҷз§Қжғ…еҶөдёӢ пјҢ жҚҹеӨұеҸӘжҳҜеҺҹе§ӢеӣҫеғҸе’Ңз”ҹжҲҗеӣҫеғҸд№Ӣй—ҙзҡ„е·®ејӮ гҖӮ жңүеӨҡз§Қи®Ўз®—ж–№жі•пјҲMSE пјҢ 欧ж°Ҹи·қзҰ»зӯүпјү гҖӮ йҖҡиҝҮжңҖе°ҸеҢ–еӣҫеғҸзҡ„е·®ејӮ пјҢ жҲ‘们иғҪеӨҹдј йҖ’йЈҺж ј гҖӮ
еҪ“жҲ‘们д»ҺжҚҹеӨұзҡ„е·ЁеӨ§е·®ејӮејҖе§Ӣж—¶ пјҢ жҲ‘们дјҡзңӢеҲ°йЈҺж јиҪ¬жҚўдёҚжҳҜйӮЈд№ҲеҘҪ гҖӮ жҲ‘们еҸҜд»ҘзңӢеҲ°йЈҺж је·Із»ҸиҪ¬з§» пјҢ дҪҶжҳҜзңӢиө·жқҘеҫҲзІ—зіҷиҖҢдё”дёҚзӣҙи§Ӯ гҖӮ еңЁжҜҸдёӘд»Јд»·жңҖе°ҸеҢ–жӯҘйӘӨдёӯ пјҢ жҲ‘们йғҪжңқзқҖжӣҙеҘҪең°еҗҲ并йЈҺж је’ҢеҶ…容并жңҖз»ҲиҺ·еҫ—жӣҙеҘҪзҡ„еӣҫеғҸзҡ„ж–№еҗ‘еҸ‘еұ• гҖӮ
жҲ‘们еҸҜд»ҘзңӢеҲ° пјҢ жӯӨиҝҮзЁӢзҡ„ж ёеҝғиҰҒзҙ жҳҜжҚҹеӨұи®Ўз®— гҖӮ йңҖиҰҒи®Ўз®—3йЎ№жҚҹеӨұпјҡ
еҶ…е®№жҚҹеӨұ
йЈҺж јжҚҹеӨұ
жҖ»пјҲеҸҳеҠЁпјүжҚҹеӨұ
еңЁжҲ‘зңӢжқҘ пјҢ иҝҷдәӣжӯҘйӘӨжҳҜжңҖйҡҫзҗҶи§Јзҡ„ пјҢ еӣ жӯӨи®©жҲ‘们дёҖдёҖж·ұе…Ҙз ”з©¶ гҖӮ
иҜ·е§Ӣз»Ҳи®°дҪҸ пјҢ жҲ‘们жӯЈеңЁе°ҶеҺҹе§Ӣиҫ“е…ҘдёҺз”ҹжҲҗзҡ„еӣҫеғҸиҝӣиЎҢжҜ”иҫғ гҖӮ иҝҷдәӣе·®ејӮе°ұжҳҜд»Јд»· гҖӮ иҖҢжҲ‘们еёҢжңӣе°ҶжӯӨд»Јд»·йҷҚиҮіжңҖдҪҺ гҖӮ
зҗҶи§ЈиҝҷдёҖзӮ№йқһеёёйҮҚиҰҒ пјҢ еӣ дёәеңЁжӯӨиҝҮзЁӢдёӯиҝҳе°Ҷи®Ўз®—е…¶д»–е·®ејӮжҚҹеӨұ гҖӮ
еҶ…е®№д»Јд»·и®Ўз®—д»Җд№ҲжҳҜеҶ…е®№д»Јд»·пјҹ жӯЈеҰӮжҲ‘们д№ӢеүҚеҸ‘зҺ°зҡ„ пјҢ жҲ‘们йҖҡиҝҮеӣҫеғҸеҜ№иұЎе®ҡд№үеӣҫеғҸзҡ„еҶ…е®№ гҖӮдҪңдёәдәәзұ»зҡ„дәӢзү©еҸҜд»ҘиҜҶеҲ«дёәдәӢзү© гҖӮ
дәҶи§ЈдәҶCNNзҡ„з»“жһ„еҗҺ пјҢ зҺ°еңЁеҫҲжҳҺжҳҫ пјҢ еңЁзҘһз»ҸзҪ‘з»ңзҡ„жң«з«Ҝ пјҢ жҲ‘们еҸҜд»ҘеҫҲеҘҪең°и®ҝй—®дёҖдёӘиЎЁзӨәеҜ№иұЎпјҲеҶ…е®№пјүзҡ„еұӮ гҖӮйҖҡиҝҮжұ еҢ–еұӮ пјҢ жҲ‘们丢еӨұдәҶеӣҫеғҸзҡ„йЈҺж јйғЁеҲҶ пјҢ дҪҶжҳҜе°ұиҺ·еҸ–еҶ…е®№иҖҢиЁҖ пјҢ иҝҷжҳҜзҗҶжғізҡ„ гҖӮ
зҺ°еңЁ пјҢ еңЁеӯҳеңЁдёҚеҗҢеҜ№иұЎзҡ„жғ…еҶөдёӢ пјҢ еҸҜд»ҘжҝҖжҙ»CNNиҫғй«ҳеұӮдёӯзҡ„зү№еҫҒеӣҫ гҖӮеӣ жӯӨ пјҢ еҰӮжһңдёӨдёӘеӣҫеғҸе…·жңүзӣёеҗҢзҡ„еҶ…е®№ пјҢ еҲҷе®ғ们еңЁиҫғй«ҳеұӮдёӯеә”е…·жңүзӣёдјјзҡ„жҝҖжҙ» гҖӮ
иҝҷжҳҜе®ҡд№үд»Јд»·еҮҪж•°зҡ„еүҚжҸҗ гҖӮ
дёӢеӣҫжңүеҠ©дәҺдәҶи§ЈеҰӮдҪ•еұ•ејҖиҜҘеұӮд»ҘеҮҶеӨҮиҝӣиЎҢи®Ўз®—пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
йЈҺж јд»Јд»·и®Ўз®—зҺ°еңЁ пјҢ е®ғеҸҳеҫ—и¶ҠжқҘи¶ҠеӨҚжқӮ гҖӮ
зЎ®дҝқдәҶи§ЈеӣҫеғҸйЈҺж је’ҢеӣҫеғҸйЈҺж јжҚҹеӨұд№Ӣй—ҙзҡ„еҢәеҲ« гҖӮдёӨз§Қи®Ўз®—жҳҜдёҚеҗҢзҡ„ гҖӮдёҖз§ҚжҳҜжЈҖжөӢ"йЈҺж јиЎЁзӨә"пјҲзә№зҗҶ пјҢ йўңиүІзӯүпјү пјҢ еҸҰдёҖз§ҚжҳҜе°ҶеҺҹе§ӢеӣҫеғҸзҡ„йЈҺж јдёҺз”ҹжҲҗзҡ„еӣҫеғҸзҡ„йЈҺж јиҝӣиЎҢжҜ”иҫғ гҖӮ
йЈҺж јжҖ»д»Јд»·еҲҶдёәдёӨдёӘжӯҘйӘӨпјҡ
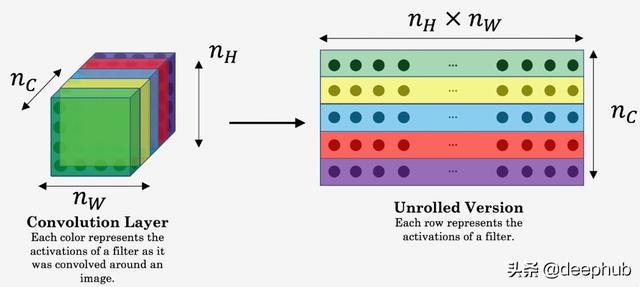
В· иҜҶеҲ«йЈҺж јеӣҫеғҸзҡ„йЈҺж ј пјҢ д»ҺжүҖжңүеҚ·з§ҜеұӮдёӯиҺ·еҸ–зү№еҫҒеҗ‘йҮҸ;е°Ҷиҝҷдәӣеҗ‘йҮҸдёҺеҸҰдёҖеұӮдёӯзҡ„зү№еҫҒеҗ‘йҮҸиҝӣиЎҢжҜ”иҫғпјҲжҹҘжүҫе…¶зӣёе…іжҖ§пјү
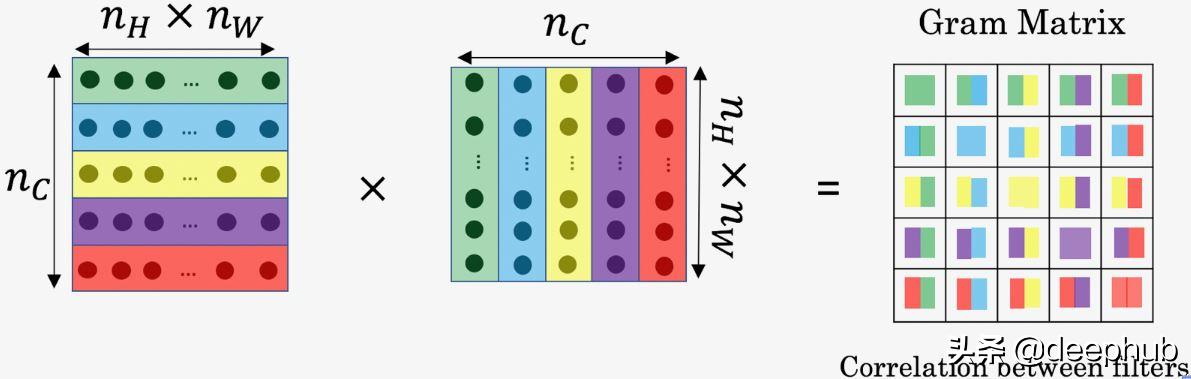
В· еҺҹе§ӢпјҲеҺҹе§ӢйЈҺж јеӣҫеғҸпјҒпјүе’Ңз”ҹжҲҗзҡ„еӣҫеғҸд№Ӣй—ҙзҡ„йЈҺж јд»Јд»· гҖӮ дёәдәҶжүҫеҲ°йЈҺж ј пјҢ еҸҜд»ҘйҖҡиҝҮе°Ҷзү№еҫҒеӣҫд№ҳд»Ҙе…¶иҪ¬зҪ®жқҘжҚ•иҺ·зӣёе…іжҖ§ пјҢ д»ҺиҖҢз”ҹжҲҗgramзҹ©йҳө гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е№ёиҝҗзҡ„жҳҜ пјҢ CNNдёәжҲ‘们жҸҗдҫӣдәҶеӨҡдёӘеұӮж¬Ў пјҢ жҲ‘们еҸҜд»ҘйҖүжӢ©жӯЈзЎ®ең°жҹҘжүҫе…¶йЈҺж ј гҖӮжҜ”иҫғеҗ„дёӘеӣҫеұӮеҸҠе…¶зӣёе…іжҖ§ пјҢ жҲ‘们еҸҜд»ҘзЎ®е®ҡеӣҫеғҸзҡ„йЈҺж ј гҖӮ
еӣ жӯӨ пјҢ жҲ‘们дёҚдҪҝз”ЁеӣҫеұӮзҡ„еҺҹе§Ӣиҫ“еҮә пјҢ иҖҢжҳҜдҪҝз”ЁеҚ•дёӘеӣҫеұӮзҡ„иҰҒзҙ еӣҫзҡ„gramзҹ©йҳөжқҘж ҮиҜҶеӣҫеғҸзҡ„йЈҺж ј гҖӮ
第дёҖдёӘд»Јд»·жҳҜиҝҷдәӣзҹ©йҳөд№Ӣй—ҙзҡ„е·®ејӮ пјҢ еҚізӣёе…іжҖ§зҡ„е·®ејӮ гҖӮ 第дәҢдёӘд»Јд»·еҗҢж ·жҳҜеҺҹе§ӢеӣҫеғҸе’Ңз”ҹжҲҗзҡ„еӣҫеғҸд№Ӣй—ҙзҡ„е·®ејӮ гҖӮ иҝҷеңЁжң¬иҙЁдёҠе°ұжҳҜ"йЈҺж јиҪ¬жҚў" гҖӮ
жҺЁиҚҗйҳ…иҜ»



















- еҚҺзЎ•еҹәдәҺWRX80зҡ„дё»жқҝзҺ°иә« дёәAMD Ryzen Threadripper Proжү“йҖ
- еҫ®иҪҜж–°зүҲз”өеӯҗйӮ®д»¶е®ўжҲ·з«ҜжҲӘеӣҫжӣқе…үпјҡеҹәдәҺзҪ‘йЎөз«ҜOutlook
- жӣқе…ү | е°Ҹй№ҸжҲ–жҳҘиҠӮеүҚжҺЁйҖҒNGPжӣҙж–°пјҢеҹәдәҺй«ҳзІҫең°еӣҫеҸҜиҮӘеҠЁеҸҳйҒ“
- еҚҺдёәйёҝи’ҷжүӢжңәеӨӘйҡҫдәҶпјҒеј•еҸ‘ејҖеҸ‘иҖ…еӨ§еҗҗж§ҪпјҡдёәдҪ•жІЎжңүиҮӘе·ұзӢ¬зү№йЈҺж јпјҹ
- еҹәдәҺSpring+Angular9+MySQLејҖеҸ‘е№іеҸ°
- 14ж¬ҫеҚҺдёәжүӢжңә/е№іжқҝе…¬жөӢEMUI 11пјҡе…ЁйғЁеҹәдәҺйә’йәҹ980
- AIиөӢиғҪпјҢи®©ж¶ҲйҳІгҖҒз”Ёз”өжӣҙвҖңжҷәж…§вҖқ
- еҹәдәҺе®үеҚ“11жү“йҖ пјҒйӯ…ж—Ҹ17зі»еҲ—е°ҶеҚҮзә§е…Ёж–°Flyme 8
- и°·жӯҢдёәз”ЁжҲ·жҸҗдҫӣдәҶеҹәдәҺARзҡ„иҷҡжӢҹеҢ–еҰҶдҪ“йӘҢ
- жҷәиғҪеҢ–зӨҫеҢәжҳҜжҷәж…§еҹҺеёӮйҮҚиҰҒзҡ„з»„жҲҗйғЁеҲҶ