关于分类数据编码所需了解的所有信息(使用Python代码)
介绍机器学习模型的性能不仅取决于模型和超参数 , 还取决于我们如何处理并将不同类型的变量输入模型 。 由于大多数机器学习模型仅接受数值变量 , 因此对分类变量进行预处理成为必要的步骤 。 我们需要将这些分类变量转换为数字 , 以便该模型能够理解和提取有价值的信息 。
 文章插图
文章插图
典型的数据科学家花费70-80%的时间来清理和准备数据 。 转换分类数据是不可避免的活动 。 它不仅可以提高模型质量 , 而且可以帮助进行更好的特征工程 。 现在的问题是 , 我们如何进行?我们应该使用哪种分类数据编码方法?
在本文中 , 我将解释各种类型的分类数据编码方法以及在Python中的实现 。
目录
- 什么是分类数据?
- 标签编码或有序编码
- 独热编码
- 虚拟编码
- 效果编码
- 二进制编码
- BaseN编码
- 哈希编码
- 目标编码
- 一个人居住的城市:德里 , 孟买 , 艾哈迈达巴德 , 班加罗尔等 。
- 一个人工作的部门:财务 , 人力资源 , 生产部 。
- 一个人拥有的最高学位:高中 , 学士 , 硕士 , 博士学位 。
- 学生的成绩:A + , A , B + , B , B-等 。
有序数据:类别具有固有顺序
名义数据:类别没有固有顺序
在有序数据中 , 在进行编码时 , 应保留有关类别提供顺序的信息 。 就像上面的例子一样 , 一个人拥有的最高学位 , 给出了有关他的资格的重要信息 。 学位是决定一个人是否适合担任职位的重要特征 。
在编码名义数据时 , 我们必须考虑特征的存在与否 。 在这种情况下 , 不存在顺序的概念 。 例如 , 一个人居住的城市 。 对于数据 , 保留一个人居住的位置很重要 。 在这里 , 我们没有任何顺序 。 如果一个人住在德里或班加罗尔 , 这是平等的 , 与顺序无关 。
为了编码分类数据 , 我们有一个python包category_encoders 。 以下代码可帮助你轻松安装 。
pip install category_encoders标签编码或有序编码当分类特征有序时 , 我们使用这种分类数据编码技术 。 在这种情况下 , 保留顺序很重要 。 因此编码应该反映顺序 。在标签编码中 , 每个标签都被转换成一个整数值 。 我们将创建一个变量 , 该变量包含代表一个人的教育资格的类别 。
import category_encoders as ceimport pandas as pdtrain_df=pd.DataFrame({'Degree':['High school','Masters','Diploma','Bachelors','Bachelors','Masters','Phd','High school','High school']})# 创建Ordinalencoding的对象encoder= ce.OrdinalEncoder(cols=['Degree'],return_df=True,mapping=[{'col':'Degree','mapping':{'None':0,'High school':1,'Diploma':2,'Bachelors':3,'Masters':4,'phd':5}}])#原始数据train_df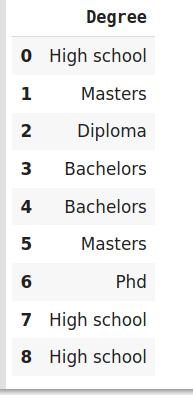 文章插图
文章插图# 调整并转换数据 df_train_transformed = encoder.fit_transform(train_df)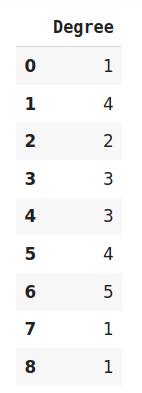 文章插图
文章插图独热编码当特征没有任何顺序时 , 我们使用这种分类数据编码技术 。 在独热编码中 , 对于一个分类特征的每个级别 , 我们创建一个新的变量 。 每个类别都映射有一个包含0或1的二进制变量 。 在这里 , 0代表该类别不存在 , 1代表该类别存在 。
推荐阅读
















- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 高下立现!关于核心技术的态度,柳传志和任正非截然不同
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能