为什么微信推荐这么快?( 三 )
- 负责对外提供检索服务 , 通过对 Chubby 的轮询检查索引的更新 , 进而将索引加载至本机以提供服务;
- 每台 worker 负责的数据 , 由 master 进行调度 , worker 根据 master 保存在 Chubby 上的分配信息进行数据的加载/卸载;
- worker 的数据是根据 master 分配得来的 , 除此之外没有其他状态的差别 , 因此 worker 是易于扩缩容的 。
- 数据调度:通过表的元信息及 worker 状态 , 将未分配的数据或者失效 worker 上的数据调度给其他有效的 worker;
- 生成路由表:根据 worker 的数据加载情况及状态 , 生成集群的路由表;
- 感知数据更新:检查表的自动更新目录 , 若最大数字目录发生了增长 , 则建一个任务以供 trainer 进行索引的构建;
- master 是一个无状态的服务 , 通过 Chubby 提供的分布式锁保证数据调度以及路由生成的唯一执行 。
- 负责构建表的索引及资源回收;
- trainer 单次可构建一张表中一个 sharding 的索引 , 因此如果表有多个 sharding 时 , 可通过增加 trainer 的个数实现构建索引的并发加速;
- trainer 是无状态的服务 , 通常部署在微信 Yard 系统上 , 充分了利用微信闲置机器上的资源 。
- 在建表时 , 对其指定了一个 fs 的目录 , 该目录下 , 是一系列数字递增的目录;
- 当业务侧需要更新索引时 , 将最新的数据 dump 到更大的数字目录中;
- master 感知最大数字目录的更新 , 从而更新了元信息;
- trainer 感知元信息的更新并触发建索引;
- worker 加载索引完成索引的更新 。
- 由业务侧主动通过接口的调用 , 创建一个索引任务;
- 在索引任务中 , 指定了数据的配置信息(如 fs 信息及路径等);
- trainer 按照表的任务序列 , 执行任务并构建索引;
- worker 加载索引完成索引的更新 。
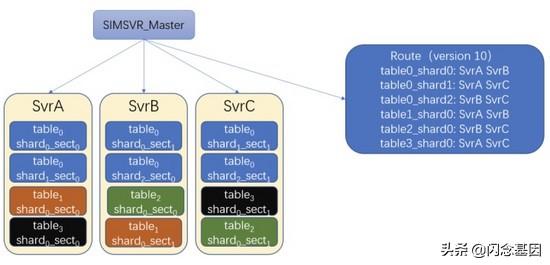
- SimSvr 在每张表创建时就指定了 sharding 数 n 及 sect 数 m , 因此这张表拥有了 n * m 个 Conatiner 以供 master 调度;
- master 会根据 worker 的健康情况及资源使用情况进行数据的调度及路由表的生成;
- 路由表带有递增的版本号 , 可根据版本号感知路由的变化 。
 文章插图
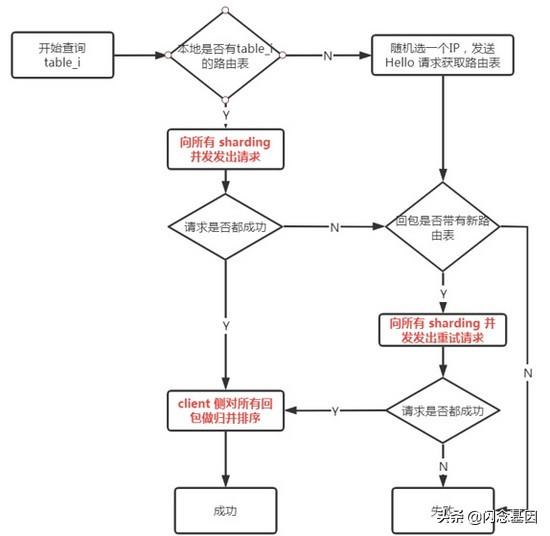
文章插图- worker 定期轮询 Chubby 获取数据的调度情况及最新的路由表信息;
- client 首次请求时 , 将随机请求一台 worker 获取最新的路由表信息并将其缓存在本地;
- client 在本地有路由表的情况下 , 将根据表的数据分布情况 , 带上版本号并发地向目标 worker 发起请求 , 最终合并所有 sharding 的结果 , 将其返回给业务端 。
 文章插图
文章插图3.4 系统拓展 - 篮子装满了该怎么办
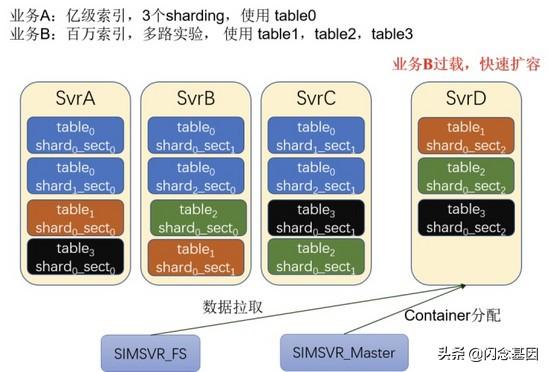
- SimSvr 将表拆分成了更小粒度的数据调度单位 , 且不要求每台机器上的数据一样 , 因此可以用拓展机器的方式 , 将集群的存储容量扩大;
- 对于单表而言 , 当读能力达到瓶颈时 , 可以单独扩展此表的读副本数;
 文章插图
文章插图
推荐阅读















- 目前配置全性价比高的手机,我只推荐五款,闭着眼买都不会错
- 为什么有"iphone是穷人手机"的言论?用万元机的人真穷吗
- 央行的“硬钱包”来势汹汹,支付不再需要手机?支付宝、微信慌了
- 比起007,996真的是福报!互联网大厂为什么加班都这么狠?
- 微信还能这么用?让你大开眼界的微信隐藏操作
- 微软调侃WhatsApp隐私策略调整 并推荐用户迁移至Skype
- 短短几个月,安装包从200M涨到354M,微信越来越臃肿了?
- 国家发布“铁令”,微信、支付宝始料未及,必须作出整改
- iOS版微信又双更新了,AirPods Pro推出牛年限定款
- 飞书文档微信小程序审核被卡?字节跳动副总裁谢欣:希望腾讯停止无理由封杀