为什么微信推荐这么快?( 二 )
- 极限情况下(以 worker 线程数 80、部署 10 张 2kw 索引量的表为例):
 文章插图
文章插图- 现网运营中(以某现网模块(11台实例机器 , worker 线程 240)为例):
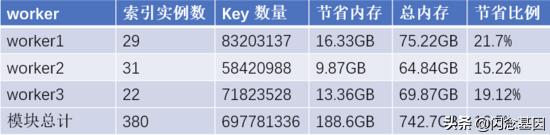 文章插图
文章插图2.3 点积距离召回率从 62.6% 到 97.8% 的蜕变心路历程
- HNSW 算法在 余弦距离 表现优秀 , 但在 点乘距离 的数据集上存在效果差的情况;
- 点乘距离非度量空间(metric space) ,不满足三角不等式, 距离比较没有传递性;
- 维基百科中关于度量空间的定义:
 文章插图
文章插图- hnswlib 中说明点积属于非度量空间:
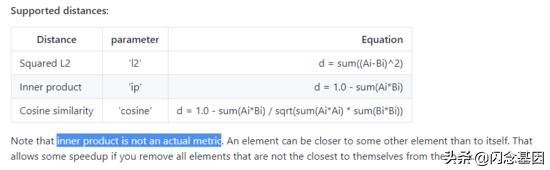 文章插图
文章插图- 而在论文 Non-metric Similarity Graphs forMaximum Inner Product Search 中 , 提到了将 点乘距离转换为余弦距离 计算的方法 , 我们将这种方法简称为 ip2cos;
 文章插图
文章插图在 ip2cos 距离转换的理论基础上 , 我们使用看一看视频实时 DSSM 模型进行了实际召回情况的效果对比(64 维、ip 距离、100 万索引数据量 , 进行 1 万次查询取平均耗时) , 并见证了 ip2cos 的神奇效果:
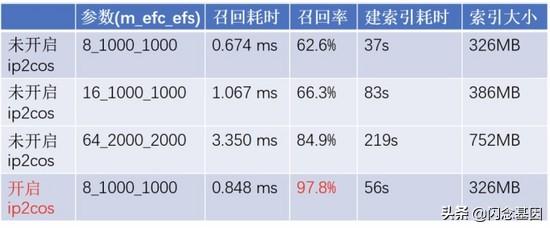 文章插图
文章插图2.4 如何使用 faiss 省下 2h 的训练时间并提升 30% 的召回率
- 在 faiss 中增加了 batch kmeans 聚类方法 , 在保证较好聚类效果的同时大幅加快训练速度 。 IVF 系类方法训练耗时主要体现在需要从数据中学习 nlist 个聚类中心 , 对于千万级数据 nlist 的大小在 20 万以上 , 在 cpu 上使用传统 kmeans 方法训练会非常耗时 , 下面展示在 128 维、IP 距离、1000 万条数据的情况下 batch kmeans 对训练速度的加速效果:
 文章插图
文章插图从结果中可以看到 , 在相同迭代轮次下 , 不使用 batch kmeans 的方法训练耗时更长 , 且没有很好收敛 , 导致召回率不高 。
3. 总体设计
3.1 数据结构 - 为达成一个小目标 , 需要做出怎样的改变
为了满足单模块多模型的需求 , SimSvr 使用了表的概念进行 多模型的管理 ;另外 , 为 支持亿级以上 HNSW 索引的表, 并且希望能够并发加速构建索引 , 我们根据单表的数据情况 , 将一张表分成了多个 sharding , 使得每个 sharding 承担表数据的其中一部分:
【为什么微信推荐这么快?】tablei 的索引 , 由 shard0、shard1、…、shardn 构成一份完整的索引数据;而 sect 的数量则决定了表的副本数(可用于伸缩读能力、提供容灾等) 。
在 SimSvr 中 , 我们将一个 shardi_sectj 称之为一个 container , 这是 SimSvr 中最小的数据调度和加载单位 。
3.2 系统架构 - 如何支撑亿级索引、5毫秒级的检索
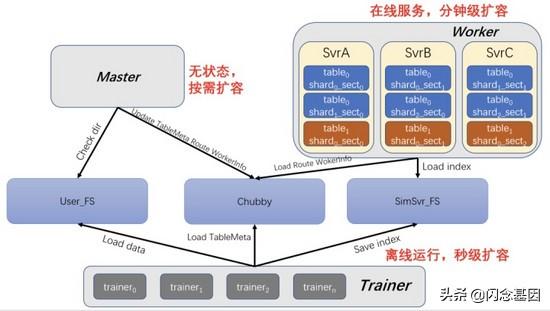 文章插图
文章插图SimSvr 架构
- SimSvr 与 FeatureKV 一样 , 涉及的外部依赖也是三个:
- Chubby:用来保存元数据、路由信息、worker 资源信息等;SimSvr 中的数据协同、分布式任务执行均是依赖于 Chubby;
推荐阅读
- 目前配置全性价比高的手机,我只推荐五款,闭着眼买都不会错
- 为什么有"iphone是穷人手机"的言论?用万元机的人真穷吗
- 央行的“硬钱包”来势汹汹,支付不再需要手机?支付宝、微信慌了
- 比起007,996真的是福报!互联网大厂为什么加班都这么狠?
- 微信还能这么用?让你大开眼界的微信隐藏操作
- 微软调侃WhatsApp隐私策略调整 并推荐用户迁移至Skype
- 短短几个月,安装包从200M涨到354M,微信越来越臃肿了?
- 国家发布“铁令”,微信、支付宝始料未及,必须作出整改
- iOS版微信又双更新了,AirPods Pro推出牛年限定款
- 飞书文档微信小程序审核被卡?字节跳动副总裁谢欣:希望腾讯停止无理由封杀