жө…и°ҲLinuxеҶ…ж ёжәҗз ҒеҲҶжһҗж–№жі•( дә” )
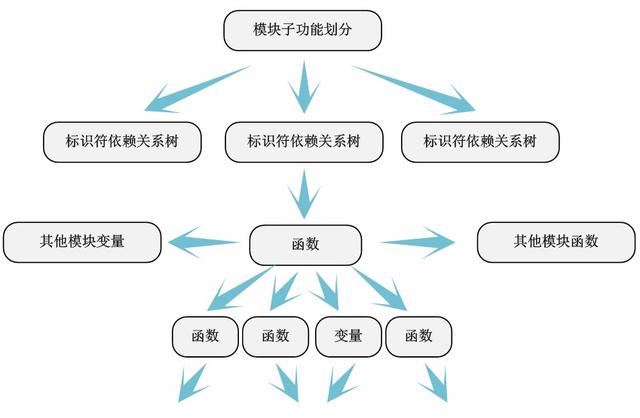
йҖҡиҝҮ第еӣӣжӯҘеҜ№д»Јз ҒжЁЎеқ—зҡ„еҲ’еҲҶ пјҢ жҲ‘们е°ұеҸҜд»ҘеҫҲвҖңиҪ»жқҫвҖқең°йҖҗдёӘеҜ№жЁЎеқ—иҝӣиЎҢеҲҶжһҗ гҖӮ дёҖиҲ¬зҡ„ пјҢ жҲ‘们еҸҜд»Ҙд»Һж–Ү件еә•йғЁзҡ„жЁЎеқ—еҮәе…ҘеҸЈеҮҪж•°ејҖе§ӢпјҲвҖңmodule_initвҖқе’ҢвҖңmodule_exitвҖқеЈ°жҳҺзҡ„еҮҪж•° пјҢ дёҖиҲ¬йғҪеңЁж–Ү件жңҖеҗҺпјү пјҢ ж №жҚ®е®ғ们и°ғз”Ёзҡ„еҮҪж•°пјҲиҮӘе·ұе®ҡд№үзҡ„жҲ–иҖ…е…¶д»–жЁЎеқ—зҡ„еҮҪж•°пјүе’ҢдҪҝз”Ёзҡ„е…ій”®еҸҳйҮҸпјҲжң¬ж–Ү件еҶ…зҡ„е…ЁеұҖеҸҳйҮҸжҲ–иҖ…е…¶д»–жЁЎеқ—зҡ„еӨ–йғЁеҸҳйҮҸпјүз”»еҮәвҖңеҮҪж•°-еҸҳйҮҸ-еҮҪж•°вҖқдҫқиө–е…ізі»еӣҫвҖ”вҖ”жҲ‘们称дёәж ҮиҜҶз¬Ұдҫқиө–е…ізі»еӣҫ гҖӮ
еҪ“然 пјҢ жЁЎеқ—еҶ…ж ҮиҜҶз¬Ұдҫқиө–关系并йқһжҳҜеҚ•зәҜзҡ„ж ‘еҪўз»“жһ„ пјҢ еҫҲеӨҡжғ…еҶөжҳҜй”ҷз»јеӨҚжқӮзҡ„зҪ‘з»ңе…ізі» гҖӮ иҝҷж—¶еҖҷ пјҢ жҲ‘们еҜ№д»Јз Ғзҡ„иҜҰз»ҶжіЁйҮҠзҡ„дҪңз”Ёе°ұдҪ“зҺ°еҮәжқҘдәҶ гҖӮ жҲ‘д»¬ж №жҚ®еҮҪж•°жң¬иә«зҡ„еҗ«д№ү пјҢ е°ҶжЁЎеқ—иҝӣиЎҢеӯҗеҠҹиғҪеҲ’еҲҶ пјҢ жҠҪеҸ–еҮәжҜҸдёӘеӯҗеҠҹиғҪзҡ„ж ҮиҜҶз¬Ұдҫқиө–ж ‘ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
йҖҡиҝҮж ҮиҜҶз¬Ұдҫқиө–е…ізі»еҲҶжһҗ пјҢ еҸҜд»ҘеҫҲжё…жҷ°зҡ„еұ•зӨәжЁЎеқ—е®ҡд№үзҡ„еҮҪж•°и°ғз”ЁдәҶйӮЈдәӣеҮҪж•° пјҢ дҪҝз”ЁдәҶе“ӘдәӣеҸҳйҮҸ пјҢ д»ҘеҸҠжЁЎеқ—еӯҗеҠҹиғҪд№Ӣй—ҙзҡ„дҫқиө–е…ізі»вҖ”вҖ”е…¬з”ЁдәҶе“ӘдәӣеҮҪж•°е’ҢеҸҳйҮҸзӯү гҖӮ
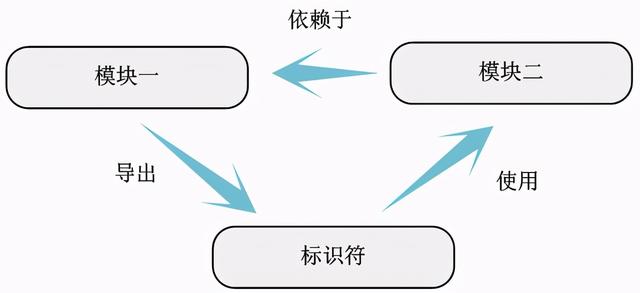
第е…ӯжӯҘпјҡжЁЎеқ—й—ҙзӣёдә’дҫқиө–е…ізі»
дёҖж—Ұе°ҶжүҖжңүзҡ„жЁЎеқ—еҶ…йғЁж ҮиҜҶз¬Ұдҫқиө–е…ізі»еӣҫж•ҙзҗҶе®ҢжҜ• пјҢ ж №жҚ®жЁЎеқ—дҪҝз”Ёзҡ„е…¶д»–жЁЎеқ—зҡ„еҸҳйҮҸжҲ–еҮҪж•° пјҢ еҸҜд»ҘеҫҲе®№жҳ“еҫ—еҲ°жЁЎеқ—д№Ӣй—ҙзҡ„дҫқиө–е…ізі» гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
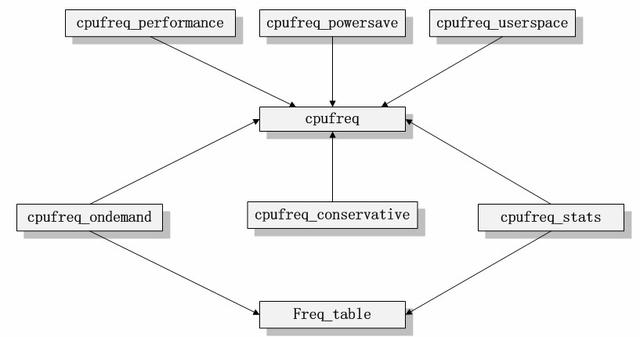
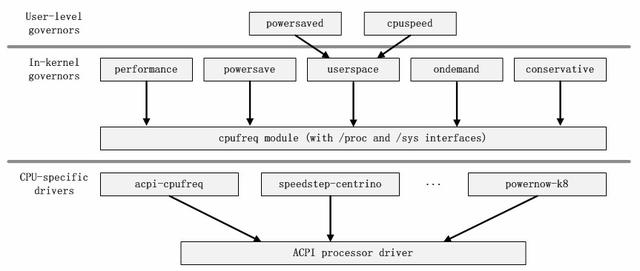
cpufreqд»Јз Ғзҡ„жЁЎеқ—дҫқиө–е…ізі»еҸҜд»ҘиЎЁзӨәдёәеҰӮдёӢе…ізі» гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
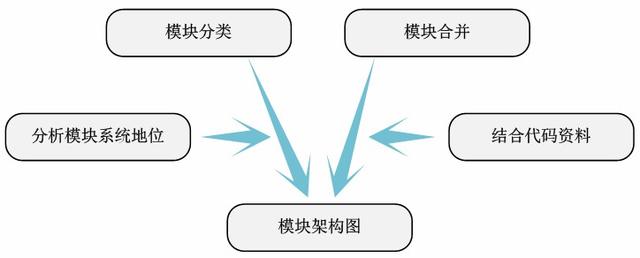
第дёғжӯҘпјҡжЁЎеқ—жһ¶жһ„еӣҫ
йҖҸиҝҮжЁЎеқ—й—ҙзҡ„дҫқиө–е…ізі»еӣҫ пјҢ еҸҜд»ҘеҫҲжё…жҘҡзҡ„иЎЁиҫҫжЁЎеқ—еңЁж•ҙдёӘеҫ…еҲҶжһҗд»Јз Ғдёӯзҡ„ең°дҪҚе’ҢеҠҹиғҪ гҖӮ еҹәдәҺжӯӨ пјҢ жҲ‘们еҸҜд»Ҙе°ҶжЁЎеқ—еҲҶзұ» пјҢ ж•ҙзҗҶеҮәд»Јз Ғзҡ„жһ¶жһ„е…ізі» гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҰӮcpufreqзҡ„жЁЎеқ—дҫқиө–е…ізі»еӣҫжүҖзӨә пјҢ жҲ‘们еҸҜд»ҘеҫҲжё…жҘҡзҡ„зңӢеҲ°жүҖжңүзҡ„и°ғйў‘зӯ–з•ҘжЁЎеқ—йғҪжҳҜдҫқиө–дәҺж ёеҝғжЁЎеқ—cpufreqгҖҒcpufreq_statsе’Ңfreq_tableзҡ„ гҖӮ еҰӮжһңжҲ‘们жҠҠиў«дҫқиө–зҡ„дёүдёӘжЁЎеқ—жҠҪиұЎдёәд»Јз Ғзҡ„ж ёеҝғжЎҶжһ¶зҡ„иҜқ пјҢ иҝҷдәӣи°ғйў‘зӯ–з•ҘжЁЎеқ—йғҪжҳҜе»әз«ӢеңЁиҝҷдёӘжЎҶжһ¶д№ӢдёҠзҡ„ пјҢ е®ғ们иҙҹиҙЈе’Ңз”ЁжҲ·еұӮдәӨдә’ гҖӮ иҖҢж ёеҝғжЁЎеқ—cpufreqжҸҗдҫӣдәҶй©ұеҠЁзӯүзӣёе…ізҡ„жҺҘеҸЈиҙҹиҙЈдёҺзі»з»ҹеә•еұӮдәӨдә’ гҖӮ еӣ жӯӨ пјҢ жҲ‘们еҸҜд»Ҙеҫ—еҲ°еҰӮдёӢзҡ„жЁЎеқ—жһ¶жһ„еӣҫ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҪ“然 пјҢ жһ¶жһ„еӣҫ并йқһжЁЎеқ—зҡ„ж— жңәжӢјжҺҘ пјҢ жҲ‘们иҝҳйңҖиҰҒз»“еҗҲжҹҘйҳ…зҡ„иө„ж–ҷеҺ»дё°еҜҢжһ¶жһ„еӣҫзҡ„еҗ«д№ү гҖӮ еӣ жӯӨ пјҢ иҝҷйҮҢзҡ„жһ¶жһ„еӣҫзҡ„з»ҶиҠӮдјҡйҡҸзқҖдёҚеҗҢзҡ„дәәзҡ„зҗҶи§ЈжңүжүҖеҒҸе·® гҖӮ дҪҶжҳҜжһ¶жһ„еӣҫдё»дҪ“зҡ„еҗ«д№үеҫҲеҹәжң¬дёҖиҮҙзҡ„ гҖӮ иҮіжӯӨ пјҢ жҲ‘们е®ҢжҲҗдәҶеҫ…еҲҶжһҗзҡ„еҶ…ж ёд»Јз Ғзҡ„жүҖжңүеҲҶжһҗе·ҘдҪң гҖӮ
еӣӣгҖҒжҖ»з»“
жӯЈеҰӮж–Үз« ејҖе§ӢжүҖиҜҙ пјҢ жҲ‘们дёҚеҸҜиғҪеҜ№е…ЁйғЁзҡ„еҶ…ж ёд»Јз ҒиҝӣиЎҢеҲҶжһҗ гҖӮ еӣ жӯӨ пјҢ йҖҡиҝҮеҜ№еҫ…еҲҶжһҗзҡ„д»Јз ҒиҝӣиЎҢдҝЎжҒҜжҗңйӣҶ пјҢ 然еҗҺжҢүз…§дёҠиҝ°зҡ„жөҒзЁӢеҲҶжһҗеҮәд»Јз Ғзҡ„еҺҹжң¬е§Ӣжң«жҳҜдәҶи§ЈеҶ…ж ёжң¬иҙЁзҡ„жңүж•ҲжүӢж®ө гҖӮ иҝҷз§ҚжҢүз…§е…·дҪ“йңҖиҰҒеҲҶжһҗеҶ…ж ёд»Јз Ғзҡ„ж–№ејҸ пјҢ дёәеҝ«йҖҹиҝӣе…ҘLinuxеҶ…ж ёзҡ„дё–з•ҢжҸҗдҫӣдәҶеҸҜиғҪ гҖӮ йҖҡиҝҮиҝҷз§Қж–№ејҸ пјҢ дёҚж–ӯзҡ„еҜ№еҶ…ж ёзҡ„е…¶д»–жЁЎеқ—еҲҶжһҗ пјҢ жңҖеҗҺз»јеҗҲеҫ—еҲ°иҮӘе·ұеҜ№LinuxеҶ…ж ёзҡ„зҗҶи§Ј пјҢ д№ҹе°ұиҫҫеҲ°дәҶжҲ‘们еӯҰд№ LinuxеҶ…ж ёзҡ„зӣ®зҡ„ гҖӮ
гҖҗжө…и°ҲLinuxеҶ…ж ёжәҗз ҒеҲҶжһҗж–№жі•гҖ‘жңҖеҗҺеҗ‘еӨ§е®¶жҺЁиҚҗдёӨжң¬еӯҰд№ еҶ…ж ёзҡ„еҸӮиҖғд№Ұ гҖӮ дёҖжң¬жҳҜгҖҠLinuxеҶ…ж ёзҡ„и®ҫи®ЎдёҺе®һзҺ°гҖӢ пјҢ иҜҘд№ҰдёәиҜ»иҖ…еҝ«йҖҹзІҫз®Җзҡ„д»Ӣз»ҚдәҶLinuxеҶ…ж ёзҡ„дё»иҰҒеҠҹиғҪе’Ңе®һзҺ° гҖӮ дҪҶдёҚдјҡжҠҠиҜ»иҖ…еёҰе…ҘLinuxеҶ…ж ёд»Јз Ғзҡ„ж·ұжёҠдёӯ пјҢ жҳҜдәҶи§ЈеҶ…ж ёжһ¶жһ„е’Ңе…Ҙй—ЁLinuxеҶ…ж ёд»Јз Ғзҡ„йқһеёёеҘҪзҡ„еҸӮиҖғд№Ұ пјҢ еҗҢж—¶иҜҘд№ҰдјҡжҸҗй«ҳиҜ»иҖ…еҜ№еҶ…ж ёд»Јз Ғзҡ„е…ҙи¶Ј гҖӮ еҸҰдёҖжң¬жҳҜгҖҠж·ұе…ҘзҗҶи§Ј
жҺЁиҚҗйҳ…иҜ»














- еҚҺдә‘еӨ§е’–иҜҙ дә‘и®Ўз®—дә‘иҝҗз»ҙжө…и°Ҳ
- еҗ‘ж—Ҙи‘өиҝңзЁӢжҺ§еҲ¶дјҒдёҡзүҲе®ўжҲ·з«Ҝжӣҙж–°еҚҮзә§пјҢдјҳеҢ–иҝңжҺ§UIйҖӮй…ҚSADDCеҶ…ж ёз®—жі•
- AMD Zen3 APUеҶ…ж ёеӣҫжҸҗеүҚеҒ·и·‘пјҡдёүзә§зј“еӯҳиҙЁеҸҳ
- иӢ№жһңM1гҖҒA14еҶ…ж ёи®ҫи®ЎеҜ№жҜ”пјҡе·®еҲ«еҫҲеӨ§
- Linux Kernel 5.10.5еҸ‘еёғпјҡзҰҒз”ЁFBCONеҠ йҖҹж»ҡеҠЁзү№жҖ§
- Linux 5.11ејҖе§Ӣеӣҙз»•PCI Express 6.0иҝӣиЎҢж—©жңҹеҮҶеӨҮ
- FedoraжӯЈеңЁеҜ»жұӮеҚҸеҠ© еёҢжңӣеҠ еҝ«Linux 5.10 LTSеҶ…ж ёжөӢиҜ•иҝӣеәҰ
- Linux Mint 20.1 UlyssaзЁіе®ҡзүҲе·ІзЎ®е®ҡ延жңҹиҮі2021е№ҙеҲқеҸ‘еёғ
- иӢұзү№е°”Xe GPUеңЁLinux 5.11дёҠзҡ„жҖ§иғҪиЎЁзҺ°дёҚй”ҷ
- MIPSжһ¶жһ„еҺӮе•Ҷж—ҘжёҗејҸеҫ® LinuxжҠҘе‘Ҡе…¶жјҸжҙһйҒӯйҒҮеӣ°йҡҫ