жө…и°ҲLinuxеҶ…ж ёжәҗз ҒеҲҶжһҗж–№жі•( дёү )
иҝҷйҮҢдёҫдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗ пјҢ еҒҮе®ҡжҲ‘们иҰҒеҲҶжһҗLinuxзҡ„еҸҳйў‘жңәеҲ¶е®һзҺ°зҡ„д»Јз Ғ гҖӮ зӣ®еүҚдёәжӯўжҲ‘们仅仅жҳҜзҹҘйҒ“иҝҷдёӘеҗҚиҜҚиҖҢе·І пјҢ йҖҸиҝҮеӯ—йқўеҗ«д№үжҲ‘们еҸҜд»ҘеӨ§иҮҙзҢңжөӢе®ғеә”иҜҘе’ҢCPUзҡ„йў‘зҺҮи°ғиҠӮзӣёе…і гҖӮ йҖҡиҝҮдҝЎжҒҜжҗңйӣҶ пјҢ жҲ‘们еә”иҜҘиғҪеҫ—еҲ°еҰӮдёӢзҡ„зӣёе…ізҡ„дҝЎжҒҜпјҡ
1пјҺCPUFreqжңәеҲ¶ гҖӮ
2пјҺperformanceгҖҒpowersaveгҖҒuserspaceгҖҒondemandгҖҒconservativeи°ғйў‘зӯ–з•Ҙ гҖӮ
3пјҺ/driver/cpufreq/ гҖӮ
4пјҺ/documention/cpufreq гҖӮ
5пјҺP stateе’ҢC state гҖӮ
вҖҰвҖҰ
еҲҶжһҗLinuxеҶ…ж ёд»Јз ҒеҰӮжһңиғҪжҗңйӣҶеҲ°иҝҷдәӣдҝЎжҒҜ пјҢ еә”иҜҘиҜҙжҳҜйқһеёёвҖңе№ёиҝҗвҖқдәҶ гҖӮ жҜ•з«ҹжңүе…іLinuxеҶ…ж ёзҡ„иө„ж–ҷзЎ®е®һдёҚеҰӮ.NETе’ҢJQueryйӮЈд№Ҳдё°еҜҢ пјҢ дёҚиҝҮиҝҷзӣёжҜ”дәҺеҚҒж•°е№ҙеүҚ пјҢ жІЎжңүејәеӨ§зҡ„жҗңзҙўеј•ж“Һ пјҢ жІЎжңүзӣёе…ізҡ„з ”з©¶иө„ж–ҷзҡ„ж—¶жңҹеә”иҜҘз§°еҫ—дёҠжҳҜвҖңеӨ§дё°ж”¶вҖқж—¶д»ЈдәҶпјҒжҲ‘们йҖҡиҝҮз®ҖеҚ•зҡ„вҖңжҗңзҙўвҖқпјҲеҸҜиғҪдјҡиҠұиҙ№дёҖеҲ°дёӨеӨ©зҡ„ж—¶й—ҙеҗ§пјү пјҢ з”ҡиҮіжүҫеҲ°дәҶиҝҷйғЁеҲҶд»Јз ҒжүҖеңЁзҡ„жәҗз Ғж–Ү件зӣ®еҪ• пјҢ дёҚеҫ—дёҚиҜҙиҝҷж ·зҡ„дҝЎжҒҜз®ҖзӣҙжҳҜвҖңд»·еҖјиҝһеҹҺвҖқпјҒ
第дәҢжӯҘпјҡжәҗз Ғе®ҡдҪҚ
д»Һиө„ж–ҷжҗңйӣҶдёӯ пјҢ жҲ‘们вҖңжңүе№ёвҖқжүҫеҲ°дәҶжәҗз Ғзӣёе…ізҡ„жәҗз Ғзӣ®еҪ• гҖӮ дҪҶжҳҜиҝҷ并йқһж„Ҹе‘ізқҖжҲ‘们зҡ„зЎ®е°ұжҳҜеҲҶжһҗиҝҷдёӘзӣ®еҪ•дёӢзҡ„жәҗд»Јз Ғ гҖӮ жңүж—¶жҲ‘们жүҫеҲ°зҡ„зӣ®еҪ•жңүеҸҜиғҪжҳҜеҲҶж•Јзҡ„ пјҢ д№ҹжңүж—¶жҲ‘们жүҫеҲ°зҡ„зӣ®еҪ•дёӢжңүеҫҲеӨҡе’Ңе…·дҪ“жңәеҷЁзӣёе…ізҡ„д»Јз Ғ пјҢ иҖҢжҲ‘们жӣҙе…іеҝғзҡ„жҳҜеҫ…еҲҶжһҗд»Јз Ғзҡ„дё»иҰҒжңәеҲ¶ пјҢ иҖҢйқһдёҺжңәеҷЁзӣёе…ізҡ„зү№еҢ–д»Јз ҒпјҲиҝҷж ·жӣҙжңүеҠ©дәҺжҲ‘们зҗҶи§ЈеҶ…ж ёзҡ„жң¬иҙЁпјү гҖӮ еӣ жӯӨ пјҢ жҲ‘们йңҖиҰҒеҜ№иө„ж–ҷдёӯж¶үеҸҠд»Јз Ғж–Ү件зҡ„иө„ж–ҷиҝӣиЎҢд»”з»Ҷз”„йҖү гҖӮ еҪ“然 пјҢ иҝҷдёҖжӯҘд№ҹдёҚеӨӘеҸҜиғҪдёҖж¬ЎжҖ§е®ҢжҲҗ пјҢ и°Ғд№ҹдёҚиғҪдҝқиҜҒдёҖж¬Ўе°ұиғҪйҖүжӢ©еҮәжүҖжңүеҫ…еҲҶжһҗзҡ„жәҗз Ғж–Ү件иҖҢдё”дёҖдёӘдёҚжјҸ гҖӮ дҪҶжҳҜжҲ‘们д№ҹдёҚеҝ…жӢ…еҝғ пјҢ еҸӘиҰҒжҲ‘们иғҪжҠ“дҪҸеӨ§еӨҡж•°жЁЎеқ—зӣёе…ізҡ„ж ёеҝғжәҗж–Ү件 пјҢ йҖҡиҝҮеҗҺжңҹеҜ№д»Јз Ғзҡ„е…·дҪ“еҲҶжһҗ пјҢ е°ұеҫҲиҮӘ然зҡ„жҠҠе®ғ们全йғЁжүҫеҮәжқҘ гҖӮ
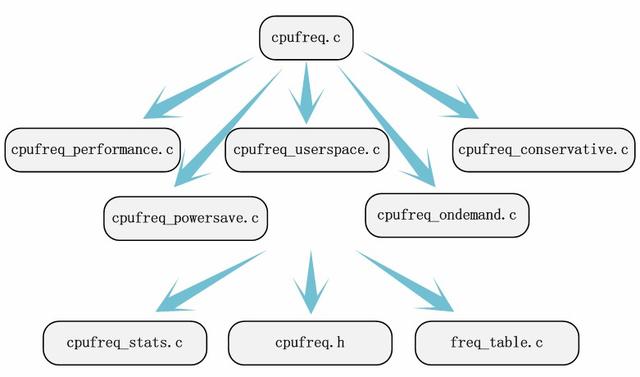
еӣһеҲ°дёҠиҝ°зҡ„дҫӢеӯҗдёӯ пјҢ жҲ‘们и®Өзңҹзҡ„йҳ…иҜ»/documention/cpufreqдёӢзҡ„ж–ҮжЎЈиҜҙжҳҺ гҖӮ зӣ®еүҚзҡ„Linuxжәҗз ҒдјҡжҠҠжЁЎеқ—зӣёе…ізҡ„ж–ҮжЎЈиҜҙжҳҺдҝқеӯҳеңЁжәҗз Ғзӣ®еҪ•зҡ„documentionзҡ„ж–Ү件еӨ№дёӢ пјҢ еҰӮжһңеҫ…еҲҶжһҗзҡ„жЁЎеқ—жІЎжңүж–ҮжЎЈиҜҙжҳҺ пјҢ иҝҷеӨҡе°‘дјҡеўһеҠ е®ҡдҪҚе…ій”®жәҗз Ғж–Ү件зҡ„йҡҫеәҰ пјҢ дҪҶжҳҜдёҚдјҡеҜјиҮҙжҲ‘们жүҫдёҚеҲ°жҲ‘们иҰҒеҲҶжһҗзҡ„жәҗз Ғ гҖӮ йҖҡиҝҮйҳ…иҜ»ж–ҮжЎЈиҜҙжҳҺ пјҢ жҲ‘们иҮіе°‘иғҪе…іжіЁеҲ°/driver/cpufreq/cpufreq.cиҝҷдёӘжәҗж–Ү件 гҖӮ йҖҡиҝҮиҝҷдёӘеҜ№жәҗж–Ү件зҡ„ж–ҮжЎЈиҜҙжҳҺ пјҢ з»“еҗҲд№ӢеүҚжҗңзҪ—еҲ°зҡ„и°ғйў‘зӯ–з•Ҙ пјҢ жҲ‘们еҫҲе®№жҳ“е…іжіЁеҲ°cpufreq_performance.cгҖҒcpufreq_powersave.cгҖҒcpufreq_userspace.cгҖҒcpufreq_ondemandгҖҒcpufreq_conservative.cиҝҷдә”дёӘжәҗж–Ү件 гҖӮ жүҖжңүж¶үеҸҠзҡ„ж–Ү件йғҪжүҫе®ҢдәҶеҗ—пјҹдёҚз”ЁжӢ…еҝғ пјҢ д»Һе®ғ们ејҖе§ӢеҲҶжһҗ пјҢ иҝҹж—©иғҪжүҫеҲ°е…¶д»–зҡ„жәҗж–Ү件 гҖӮ еҰӮжһңеңЁwindowsдёӢдҪҝз”Ёsourceinsightйҳ…иҜ»еҶ…ж ёжәҗз Ғзҡ„иҜқ пјҢ жҲ‘们йҖҡиҝҮеҮҪж•°зҡ„и°ғз”Ёе’ҢжҹҘжүҫз¬ҰеҸ·еј•з”ЁзӯүеҠҹиғҪ пјҢ з»“еҗҲд»Јз Ғзҡ„еҲҶжһҗеҸҜд»ҘеҫҲж–№дҫҝзҡ„жүҫеҲ°еҸҰеӨ–зҡ„ж–Ү件freq_table.cгҖҒcpufreq_stats.cе’Ң/include/linux/cpufreq.h гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҢүз…§жҗңзҙўеҮәзҡ„дҝЎжҒҜжөҒеҠЁж–№еҗ‘ пјҢ жҲ‘们е®Ңе…ЁеҸҜд»Ҙе®ҡдҪҚеҲ°йңҖиҰҒеҲҶжһҗзҡ„жәҗз Ғж–Ү件 гҖӮ жәҗз Ғе®ҡдҪҚиҝҷдёҖжӯҘ并йқһеҚҒеҲҶе…ій”® пјҢ еӣ дёәжҲ‘们дёҚйңҖиҰҒжүҫеҮәжүҖжңүжәҗз Ғж–Ү件 пјҢ жҲ‘们еҸҜд»ҘжҠҠйғЁеҲҶе·ҘдҪңжҺЁиҝҹеҲ°еҲҶжһҗд»Јз Ғзҡ„иҝҮзЁӢдёӯ гҖӮ жәҗз Ғе®ҡдҪҚд№ҹжҜ”иҫғе…ій”® пјҢ жүҫеҲ°дёҖйғЁеҲҶжәҗз Ғж–Ү件жҳҜеҲҶжһҗжәҗз Ғзҡ„еҹәзЎҖ гҖӮ
第дёүжӯҘпјҡз®ҖеҚ•жіЁйҮҠ
еңЁе·Іе®ҡдҪҚеҘҪзҡ„жәҗз Ғж–Ү件дёӯ пјҢ еҲҶжһҗжҜҸдёӘеҸҳйҮҸгҖҒе®ҸгҖҒеҮҪж•°гҖҒз»“жһ„дҪ“зӯүд»Јз Ғе…ғзҙ зҡ„еӨ§иҮҙеҗ«д№үе’ҢеҠҹиғҪ гҖӮ д№ӢжүҖд»Ҙз§°жӯӨдёәз®ҖеҚ•жіЁйҮҠ пјҢ 并йқһжҢҮиҝҷйғЁеҲҶзҡ„жіЁйҮҠе·ҘдҪңеҫҲз®ҖеҚ• пјҢ иҖҢжҳҜжҢҮиҝҷйғЁеҲҶзҡ„жіЁйҮҠеҸҜд»ҘдёҚеҝ…иҝҮеҲҶз»ҶеҢ– пјҢ еҸӘиҰҒеӨ§иҮҙжҸҸиҝ°еҮәзӣёе…ід»Јз Ғе…ғзҙ зҡ„еҗ«д№үеҚіеҸҜ гҖӮ зӣёеҸҚ пјҢ иҝҷйҮҢзҡ„е·ҘдҪңе…¶е®һжҳҜж•ҙдёӘеҲҶжһҗжөҒзЁӢдёӯжңҖеӣ°йҡҫзҡ„дёҖжӯҘ гҖӮ еӣ дёәиҝҷжҳҜ第дёҖж¬Ўж·ұе…ҘеҲ°еҶ…ж ёд»Јз Ғзҡ„еҶ…йғЁ пјҢ е°Өе…¶жҳҜеҜ№дәҺйҰ–ж¬ЎеҲҶжһҗеҶ…ж ёжәҗз Ғзҡ„дәәжқҘиҜҙ пјҢ еӨ§йҮҸзҡ„з”ҹз–Ҹ
жҺЁиҚҗйҳ…иҜ»














- еҚҺдә‘еӨ§е’–иҜҙ дә‘и®Ўз®—дә‘иҝҗз»ҙжө…и°Ҳ
- еҗ‘ж—Ҙи‘өиҝңзЁӢжҺ§еҲ¶дјҒдёҡзүҲе®ўжҲ·з«Ҝжӣҙж–°еҚҮзә§пјҢдјҳеҢ–иҝңжҺ§UIйҖӮй…ҚSADDCеҶ…ж ёз®—жі•
- AMD Zen3 APUеҶ…ж ёеӣҫжҸҗеүҚеҒ·и·‘пјҡдёүзә§зј“еӯҳиҙЁеҸҳ
- иӢ№жһңM1гҖҒA14еҶ…ж ёи®ҫи®ЎеҜ№жҜ”пјҡе·®еҲ«еҫҲеӨ§
- Linux Kernel 5.10.5еҸ‘еёғпјҡзҰҒз”ЁFBCONеҠ йҖҹж»ҡеҠЁзү№жҖ§
- Linux 5.11ејҖе§Ӣеӣҙз»•PCI Express 6.0иҝӣиЎҢж—©жңҹеҮҶеӨҮ
- FedoraжӯЈеңЁеҜ»жұӮеҚҸеҠ© еёҢжңӣеҠ еҝ«Linux 5.10 LTSеҶ…ж ёжөӢиҜ•иҝӣеәҰ
- Linux Mint 20.1 UlyssaзЁіе®ҡзүҲе·ІзЎ®е®ҡ延жңҹиҮі2021е№ҙеҲқеҸ‘еёғ
- иӢұзү№е°”Xe GPUеңЁLinux 5.11дёҠзҡ„жҖ§иғҪиЎЁзҺ°дёҚй”ҷ
- MIPSжһ¶жһ„еҺӮе•Ҷж—ҘжёҗејҸеҫ® LinuxжҠҘе‘Ҡе…¶жјҸжҙһйҒӯйҒҮеӣ°йҡҫ