дҪҝз”Ёtensorflowе’ҢKerasзҡ„еҲқзә§ж•ҷзЁӢ( еӣӣ )
иҜ„дј°иҫ“еҮәX_test = preprocessing.normalize(X_test)results = model.evaluate(X_test, y_test.values)1781/1781 [==============================] - 1s 614us/step - loss: 0.0086 - accuracy: 0.9989з”ЁTensor BoardеҲҶжһҗеӯҰд№ жӣІзәҝTensorBoardжҳҜдёҖдёӘеҫҲеҘҪзҡ„дәӨдә’ејҸеҸҜи§ҶеҢ–е·Ҙе…· пјҢ еҸҜз”ЁдәҺжҹҘзңӢи®ӯз»ғжңҹй—ҙзҡ„еӯҰд№ жӣІзәҝгҖҒжҜ”иҫғеӨҡдёӘиҝҗиЎҢзҡ„еӯҰд№ жӣІзәҝгҖҒеҲҶжһҗи®ӯз»ғжҢҮж Үзӯү гҖӮ жӯӨе·Ҙе…·йҡҸTensorFlowиҮӘеҠЁе®үиЈ… гҖӮ
import osroot_logdir = os.path.join(os.curdir, вҖңmy_logsвҖқ)def get_run_logdir(): import time run_id = time.strftime(вҖңrun_%Y_%m_%d-%H_%M_%SвҖқ) return os.path.join(root_logdir, run_id)run_logdir = get_run_logdir()tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)model.fit(X_train, y_train.values, batch_size = 2000, epochs = 20, verbose = 1, callbacks=[tensorboard_cb])%load_ext tensorboard%tensorboard --logdir=./my_logs --port=6006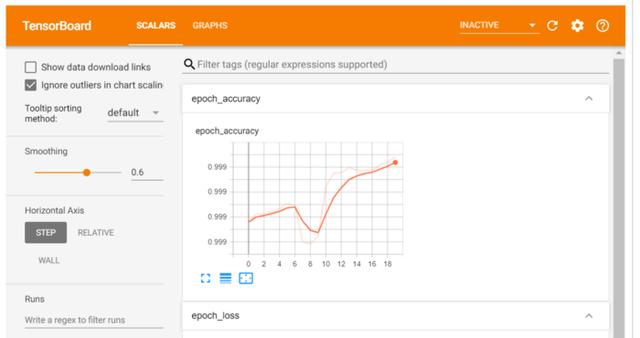 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
и¶…еҸӮи°ғиҠӮеҰӮеүҚжүҖиҝ° пјҢ еҜ№дәҺдёҖдёӘй—®йўҳз©әй—ҙ пјҢ жңүеӨҡе°‘йҡҗи—ҸеұӮжҲ–еӨҡе°‘зҘһз»Ҹе…ғжңҖйҖӮеҗҲ пјҢ 并没жңүйў„е®ҡд№үзҡ„规еҲҷ гҖӮ жҲ‘们еҸҜд»ҘдҪҝз”ЁйҡҸжңәеҢ–searchcvжҲ–GridSearchCVжқҘи¶…и°ғдёҖдәӣеҸӮж•° гҖӮ еҸҜеҫ®и°ғзҡ„еҸӮж•°жҰӮиҝ°еҰӮдёӢпјҡ
- йҡҗи—ҸеұӮж•°
- йҡҗи—ҸеұӮзҘһз»Ҹе…ғ
- дјҳеҢ–еҷЁ
- еӯҰд№ зҺҮ
- epoch
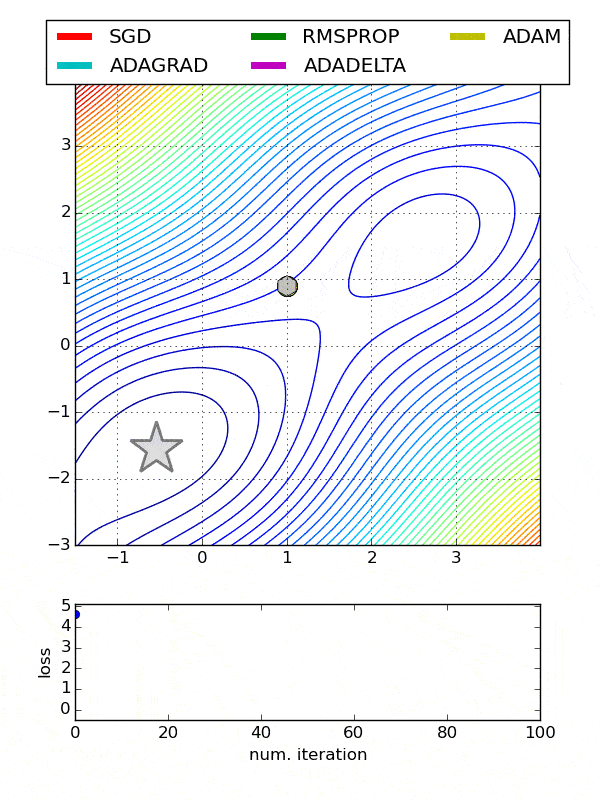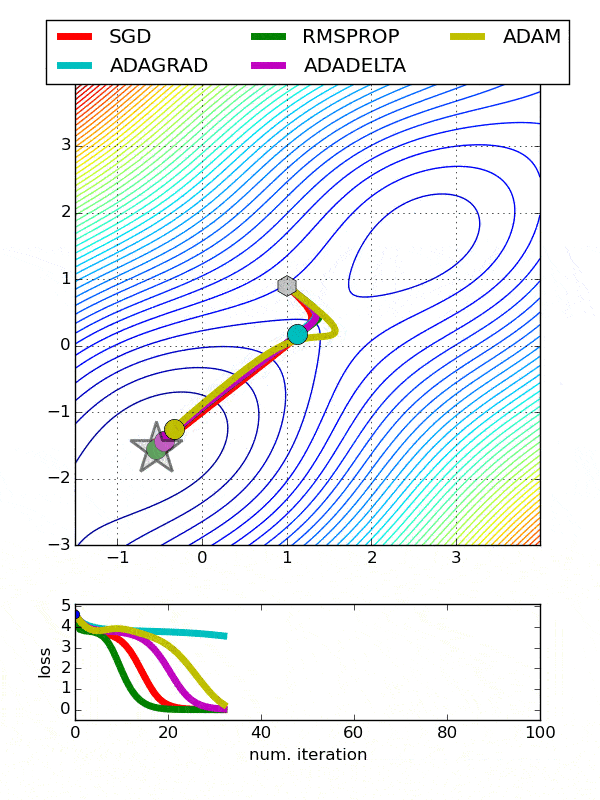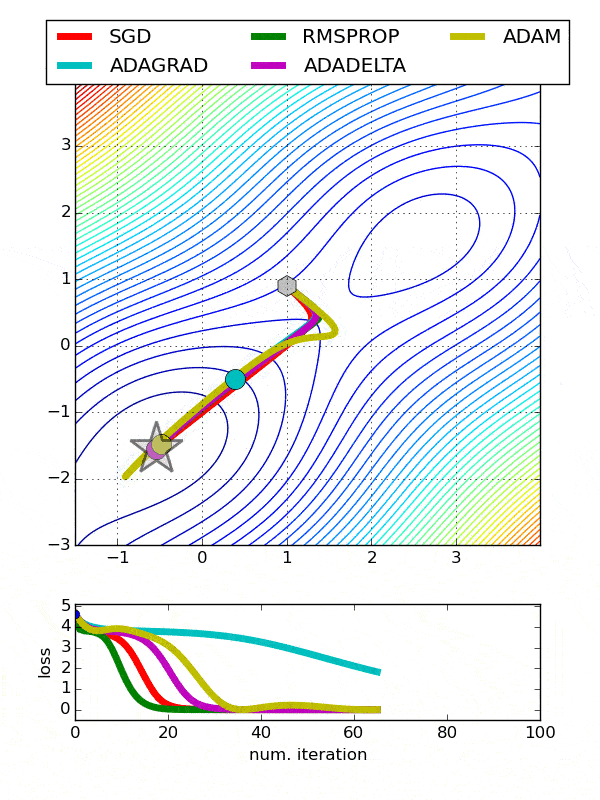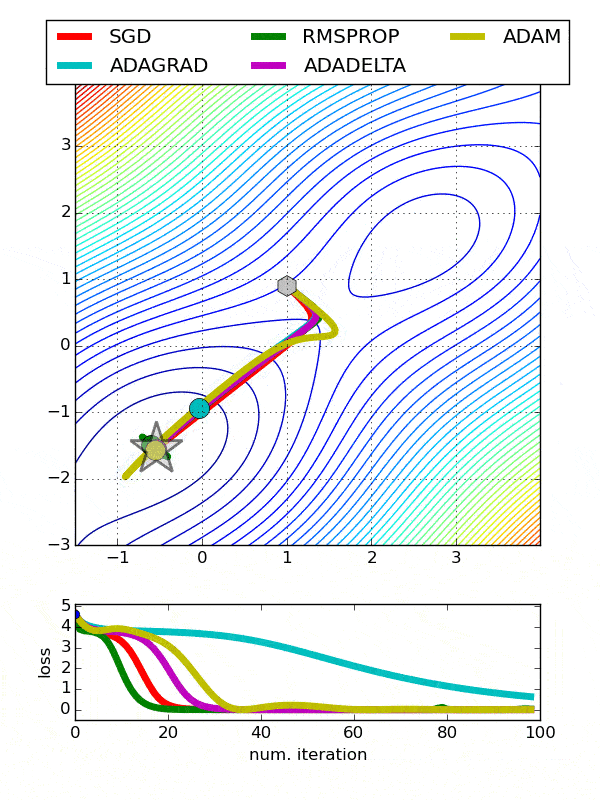
def build_model(n_hidden_layer=1, n_neurons=10, input_shape=29):# еҲӣе»әжЁЎеһӢmodel = Sequential()model.add(Dense(10, input_shape = (29,), activation = 'tanh'))for layer in range(n_hidden_layer):model.add(Dense(n_neurons, activation="tanh"))model.add(Dense(1, activation = 'sigmoid'))# зј–иҜ‘жЁЎеһӢmodel.compile(optimizer ='Adam', loss = 'binary_crossentropy', metrics=['accuracy'])return modelдҪҝз”ЁеҢ…иЈ…зұ»е…ӢйҡҶжЁЎеһӢfrom sklearn.base import clonekeras_class = tf.keras.wrappers.scikit_learn.KerasClassifier(build_fn = build_model,nb_epoch = 100, batch_size=10)clone(keras_class)keras_class.fit(X_train, y_train.values)еҲӣе»әйҡҸжңәжҗңзҙўзҪ‘ж јfrom scipy.stats import reciprocalfrom sklearn.model_selection import RandomizedSearchCVparam_distribs = { вҖңn_hidden_layerвҖқ: [1, 2, 3], вҖңn_neuronsвҖқ: [20, 30],# вҖңlearning_rateвҖқ: reciprocal(3e-4, 3e-2),# вҖңoptвҖқ:[вҖҳAdamвҖҷ]}rnd_search_cv = RandomizedSearchCV(keras_class, param_distribs, n_iter=10, cv=3)rnd_search_cv.fit(X_train, y_train.values, epochs=5)жЈҖжҹҘжңҖдҪіеҸӮж•°rnd_search_cv.best_params_{'n_neurons': 30, 'n_hidden_layer': 3}rnd_search_cv.best_score_model = rnd_search_cv.best_estimator_.modelдјҳеҢ–еҷЁд№ҹеә”иҜҘеҫ®и°ғ пјҢ еӣ дёәе®ғ们еҪұе“ҚжўҜеәҰдёӢйҷҚгҖҒ收ж•ӣе’ҢеӯҰд№ йҖҹзҺҮзҡ„иҮӘеҠЁи°ғж•ҙ гҖӮ- Adadelta -AdadeltaжҳҜAdagradзҡ„дёҖдёӘжӣҙеҒҘеЈ®зҡ„жү©еұ• пјҢ е®ғеҹәдәҺжўҜеәҰжӣҙж–°зҡ„移еҠЁзӘ—еҸЈжқҘи°ғж•ҙеӯҰд№ йҖҹзҺҮ пјҢ иҖҢдёҚжҳҜзҙҜз§ҜжүҖжңүиҝҮеҺ»зҡ„жўҜеәҰ
- йҡҸжңәжўҜеәҰдёӢйҷҚ-еёёз”Ё гҖӮ йңҖиҰҒдҪҝз”ЁжҗңзҙўзҪ‘ж јеҫ®и°ғеӯҰд№ зҺҮ
- Adagrad-еҜ№дәҺжүҖжңүеҸӮж•°е’Ңе…¶д»–дјҳеҢ–еҷЁзҡ„жҜҸдёӘе‘Ёжңҹ пјҢ еӯҰд№ йҖҹзҺҮйғҪжҳҜжҒ’е®ҡзҡ„ гҖӮ 然иҖҢ пјҢ AdagradеңЁеӨ„зҗҶиҜҜе·®еҮҪж•°еҜјж•°ж—¶ пјҢ дјҡж”№еҸҳжҜҸдёӘеҸӮж•°зҡ„еӯҰд№ йҖҹзҺҮвҖңО·вҖқ пјҢ 并еңЁжҜҸдёӘж—¶й—ҙжӯҘй•ҝвҖңtвҖқеӨ„ж”№еҸҳ
- ADAM-ADAM(иҮӘйҖӮеә”зҹ©дј°и®Ў)еҲ©з”ЁдёҖйҳ¶е’ҢдәҢйҳ¶еҠЁйҮҸжқҘйҳІжӯўи·іи¶ҠеұҖйғЁжһҒе°ҸеҖј пјҢ дҝқжҢҒдәҶиҝҮеҺ»жўҜеәҰзҡ„жҢҮж•°иЎ°еҮҸе№іеқҮеҖј
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»












![[жңЁдёҖи®әеҸІ]еҸӘеӣ еҘіжҠӨеЈ«дёә10дёҮзҫҺйҮ‘пјҢеҒ·еҒ·жҺҗж–ӯж°§ж°”з®ЎпјҢдјҠжң—еҜјеј№дё“家зӘ’жҒҜиә«дәЎ](https://imgcdn.toutiaoyule.com/20200425/20200425183300092024a_t.jpeg)


- Biogenе°ҶдҪҝз”ЁApple Watchз ”з©¶иҖҒе№ҙз—ҙе‘Ҷз—Үзҡ„ж—©жңҹз—ҮзҠ¶
- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- жҲ–дҪҝз”ЁеӨ©зҺ‘1000+иҠҜзүҮпјҹиҚЈиҖҖV40е·Іе…Ёжё йҒ“ејҖеҗҜйў„зәҰ
- иӢ№жһңе°ҶжҺЁеҮәдҪҝз”Ёmini LEDеұҸзҡ„iPad Pro
- жүӢжңәиғҪз”ЁеӨҡд№…пјҹеҰӮжһңеҮәзҺ°иҝҷ3з§ҚеҫҒе…ҶпјҢиҜҙжҳҺвҖңй»ҳи®ӨдҪҝз”Ёж—¶й—ҙвҖқе·ІеҲ°
- иӢ№жһңжңүжңӣеңЁ2021е№ҙеҲқеҸ‘еёғйҰ–ж¬ҫдҪҝз”Ёmini LEDжҳҫзӨәеұҸзҡ„ iPad Pro
- 笔记жң¬дҝқе…»жңүеҰҷжӢӣпјҒеӯҰдјҡиҝҷеҮ жӢӣ笔记жң¬еҶҚжҲҳдёүе№ҙ
- ж•°жҚ®еҸҜи§ҶеҢ–дёүиҠӮиҜҫд№ӢдәҢпјҡеҸҜи§ҶеҢ–зҡ„дҪҝз”Ё
- зҙўе°јsw77дёҺsw55зҡ„дҪҝз”Ёе·®еҲ«ж„ҹеҸ—
- зҲҶж–ҷз§°дёҖеҠ 9зі»еҲ—дёҺжҪңжңӣејҸй•ңеӨҙж— зјҳ 继з»ӯдҪҝз”Ёжҷ®йҖҡй•ҝз„Ұ